es基本概念
es是什么
elasticsearch是一个分布式、restful风格的搜索和数据存储分析引擎
es主要功能
数据存储、数据搜索、数据分析
es相关术语
文档document
document文档就是用户存在es中的一些数据,它是es中存储的最小单元(类似于表中的一行数据)。
注意:每个文档都有一个唯一的id表示,可以自行指定,如果不指定es会自动生成
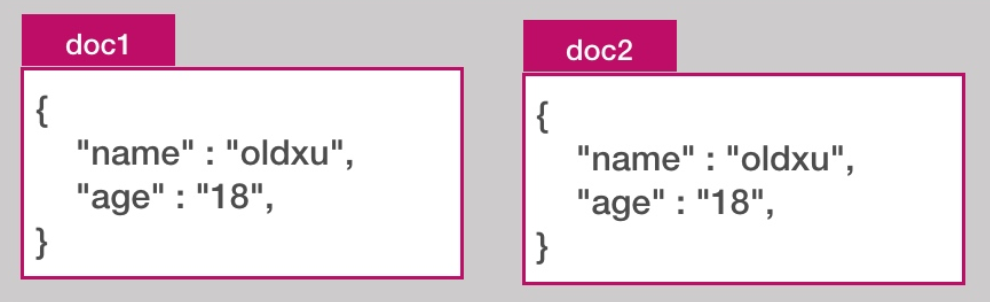
索引index
索引其实是一堆文档document的集合(类似数据库中的一个表)

字段filed
在es中,document就是一个json object,一个json object其实是由多个字段组成的,每个字段它有不同的数据类型

字符串:text、keyword
数值型:long、integer、short、byte、double、float
布尔:boolean
日期:date
二进制:binary
范围类型:integer_range,float_range,long_range,double_range,date_range
es术语总结
es索引、文档、字段关系小结:
一个索引里面存储了很多的document文档,一个文档就是一个json object,一个json object是由多个不同或相同的filed字段组成;
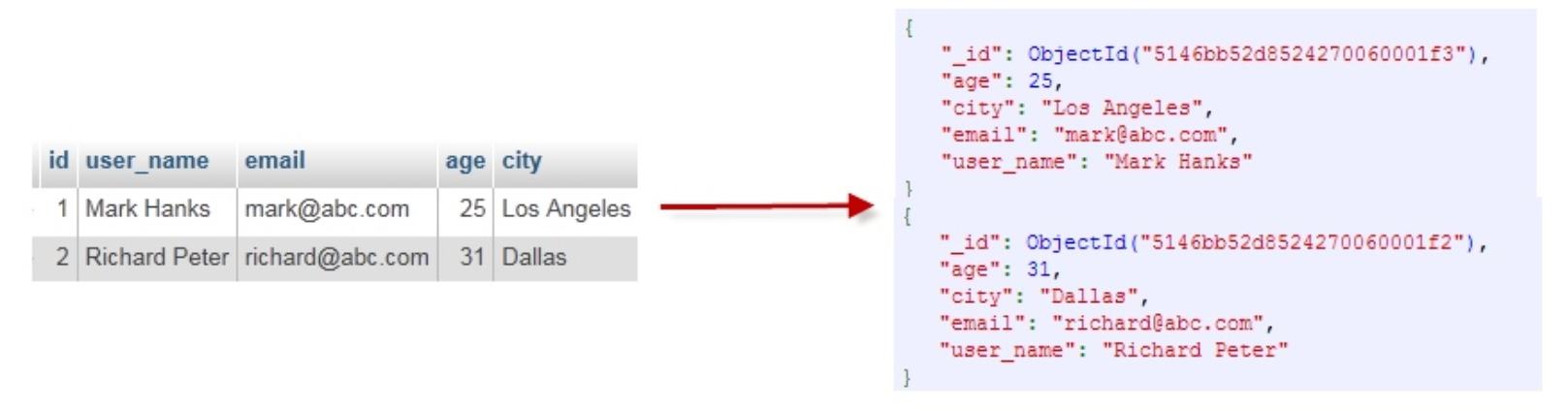
es操作方式
-
es的操作和我们传统的数据库操作不太一样,它是通过restfulapi方式进行操作的,其实本质上就是通过http的方式去变更我们的资源状态- 通过
uri指定要操作的资源,比如index、document - 通过
http method指定要操作的方法:如get、post、put、delete
- 通过
-
常见操作
es的两种方式:curl、kibana devtools
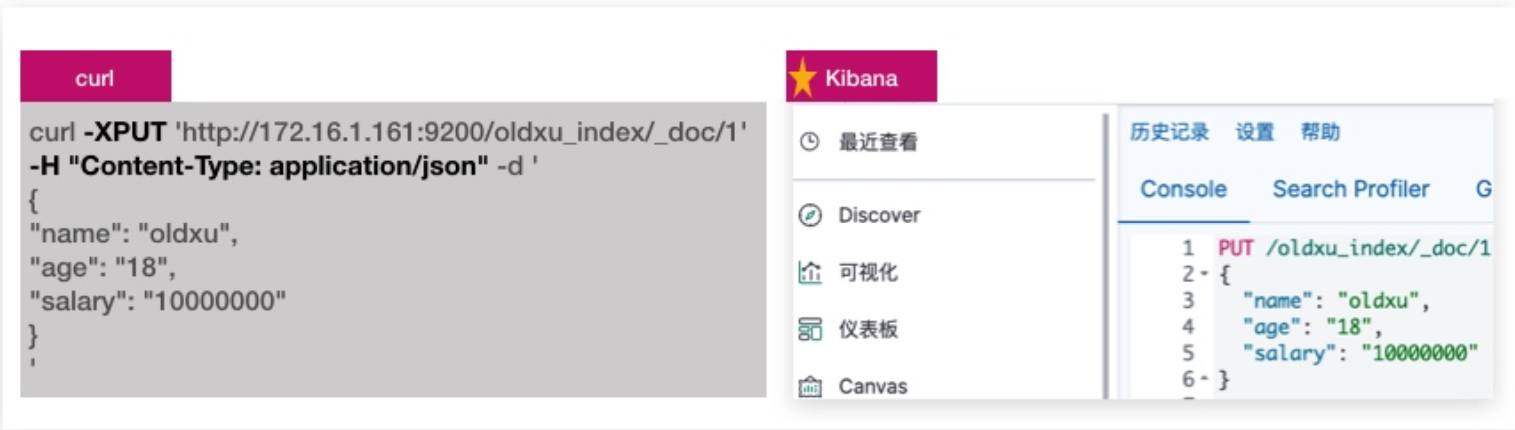
curl命令操作es
kibana操作es
# 安装kibana
rpm -ivh kibana-7.8.1-x86_64.rpm
# 配置kibana
grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "kibana.dot.com"
elasticsearch.hosts: ["http://x.x.x.x:9200"]
i18n.locale: "zh-CN"
# 启动kibana
systemctl start kibana
systemctl enable kibanaes索引api
es有专门的index api,用于创建、更新、删除索引配置等
创建索引
创建索引api如下:
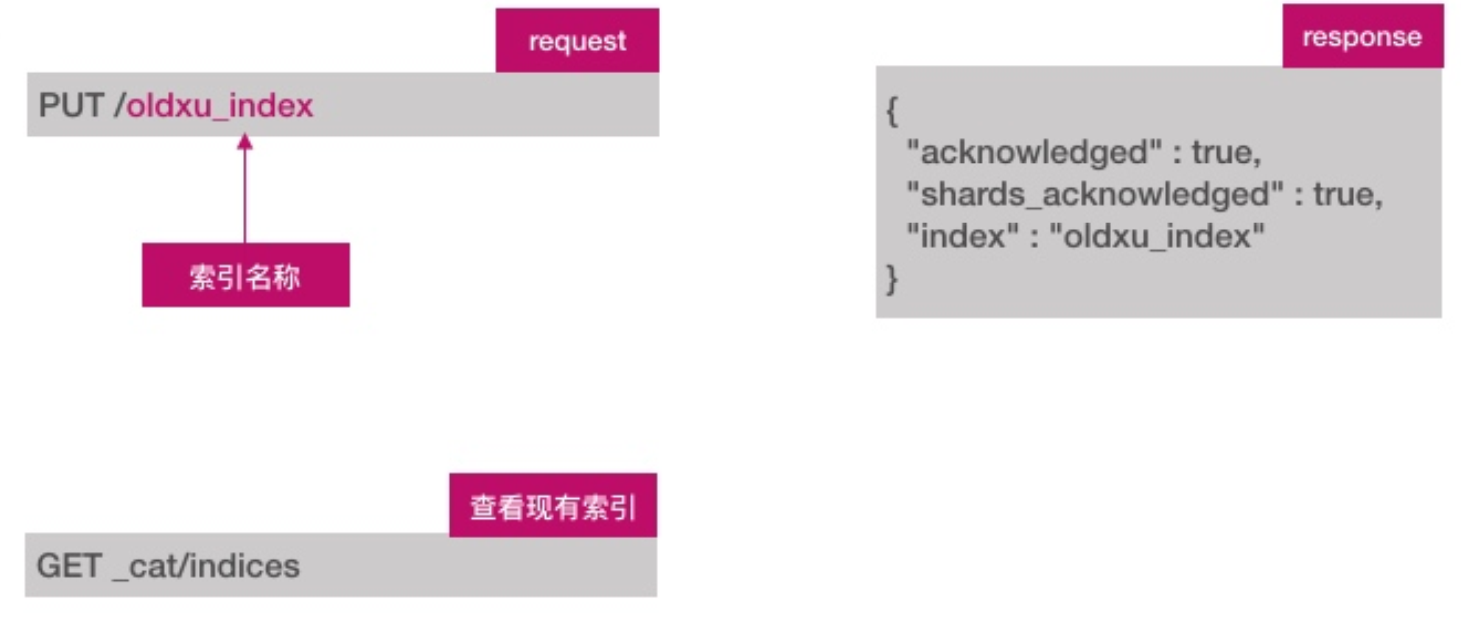
# 创建索引
PUT /test_index
# 查看所有已存在的索引
GET _cat/indices删除索引
删除索引api如下

# 删除索引
DELETE /test_indexes文档api
es为索引添加文档,有专门的document api
- 创建文档
创建文档,需要指定id

# 创建一个文档(指定ID)
POST /test_index/_doc/1
{
"username": "hello",
"age": 18,
"salary": 100
}创建文档,不指定id

- 查询文档
查询文档,指定要查询的文档id

查询文档,搜索所有文档,用_search
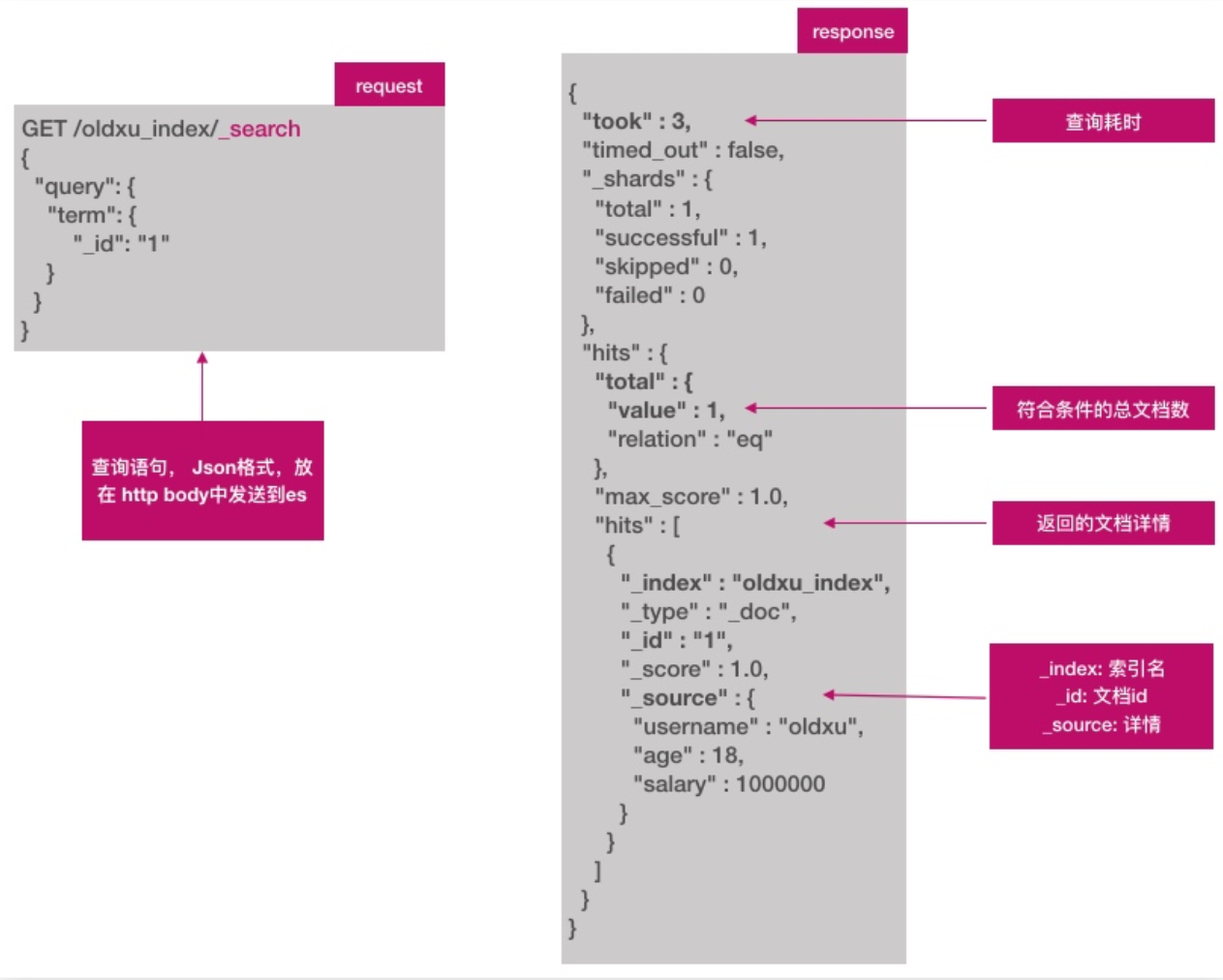
# 查询指定的内容
GET /tencentnginx-access-7.8.1-2024.08.03/_search
{
"query": {"match": {
"remote_addr": "222.217.160.209"
}}
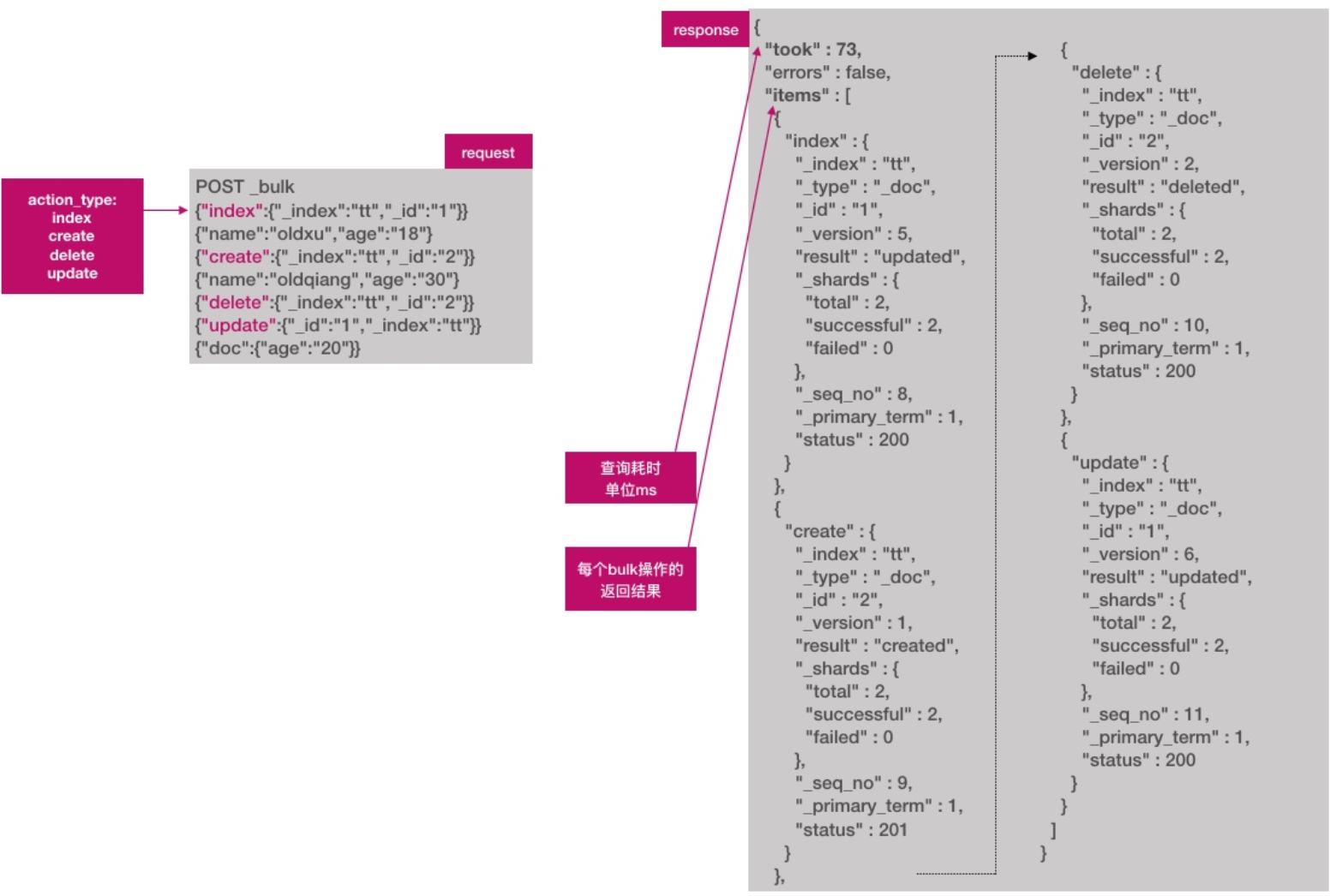
}- 批量创建文档
es允许通过_bulk一次创建多个文档,从而减少网络传输开销,提升写入速率
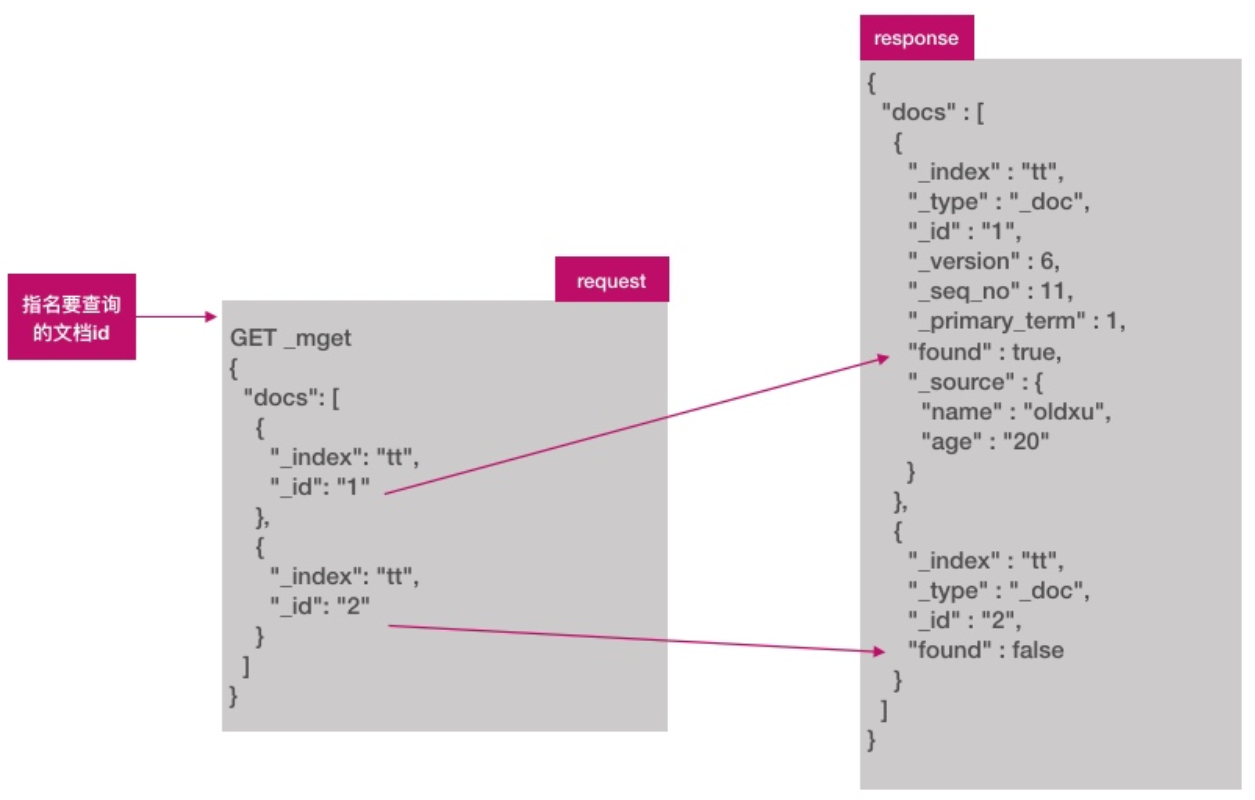
es允许通过_mget一次查询多个文档
es集群安装部署
es集群的好处
es天然支持集群模式、其好处主要有两个:- 1.能够增大系统的容量,如内存、磁盘,使得
es集群可以支持pb级的数据 - 2.能够提供系统可用性,即使部分节点停止服务,整个集群依然可以正常服务
- 1.能够增大系统的容量,如内存、磁盘,使得
es如何组建集群
- 单节点
es,如下图所示
- 如果单节点出现问题,服务就不可用了,如何新增一个
es节点加入集群
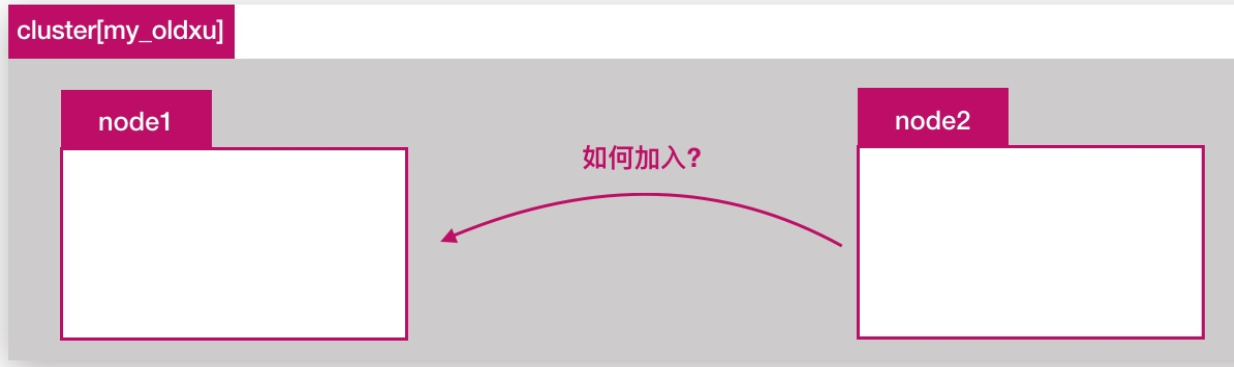
elasticsearch集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点通过node.name指定节点的名称
es集群环境部署
环境准备
| 主机名称 | ip地址 |
|---|---|
| es-node1 | 192.168.1.11 |
| es-node2 | 192.168.1.12 |
| es-node3 | 192.168.1.13 |
安装es软件
所有集群节点都需要安装es软件
yum install java
rpm -ivh elasticsearch-7.8.1-x86_64.rpmnode1集群节点配置
grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application # 集群名称
node.name: node-1 # 节点名称
path.data: /elkstorage # 数据存储路径
path.logs: /var/log/elasticsearch # 日志存储路径
bootstrap.memory_lock: true # 不使用swap分区(需修改启动参数)
network.host: 192.168.99.11 # 监控在本地哪个地址(web访问需通过cerebro)
http.port: 9200 # 监听端口
discovery.seed_hosts: ["192.168.99.11", "192.168.99.12","192.168.99.13"] # 集群主机列表
cluster.initial_master_nodes: ["192.168.99.11", "192.168.99.12","192.168.99.13"] # 仅第一次启动集群时进行选举node2集群节点配置
grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: node-2
path.data: /elkstorage
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.99.12
http.port: 9200
discovery.seed_hosts: ["192.168.99.11", "192.168.99.12","192.168.99.13"]
cluster.initial_master_nodes: ["192.168.99.11", "192.168.99.12","192.168.99.13"]node3集群节点配置
grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: node-3
path.data: /elkstorage
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.99.13
http.port: 9200
discovery.seed_hosts: ["192.168.99.11", "192.168.99.12","192.168.99.13"]
cluster.initial_master_nodes: ["192.168.99.11", "192.168.99.12","192.168.99.13"]es集群健康检测
cluster health获取集群的健康状态,整个集群状态包括以下三种:
- 1.
green健康状态,指所有主副分片都正常分配 - 2.
yellow指所有主分片都正常分配,但是有副本分片未正常分配 - 3.
red有主分片未分配,表示索引不完备,写可能有问题。(但不代表不能存储数据和读取数据)
检查es集群是否正常运行,可以通过curl、cerebro两种方式;
curl命令检查集群状态
# 通过curl检查es集群状态
curl http://192.168.99.11:9200/_cluster/health?pretty=true
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 20,
"active_shards" : 40,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# 监控es集群状态脚本
curl -s http://192.168.99.11:9200/_cluster/health?pretty=true | grep "status" | awk -F '"' '{print $4}'
greencerebro检查集群状态
可视化cerebro工具检查es集群状态
rpm -ivh cerebro-0.9.4-1.noarch.rpm
vim /etc/cerebro/application.conf
# Path of local database file
data.path: "/var/lib/cerebro/cerebro.db"
#data.path = "./cerebro.db"
systemctl enable cerebro.service
systemctl start cerebro.service
netstat -lntp
tcp6 0 0 :::9000 :::* LISTEN 3149/java集群检查效果如下图所示:
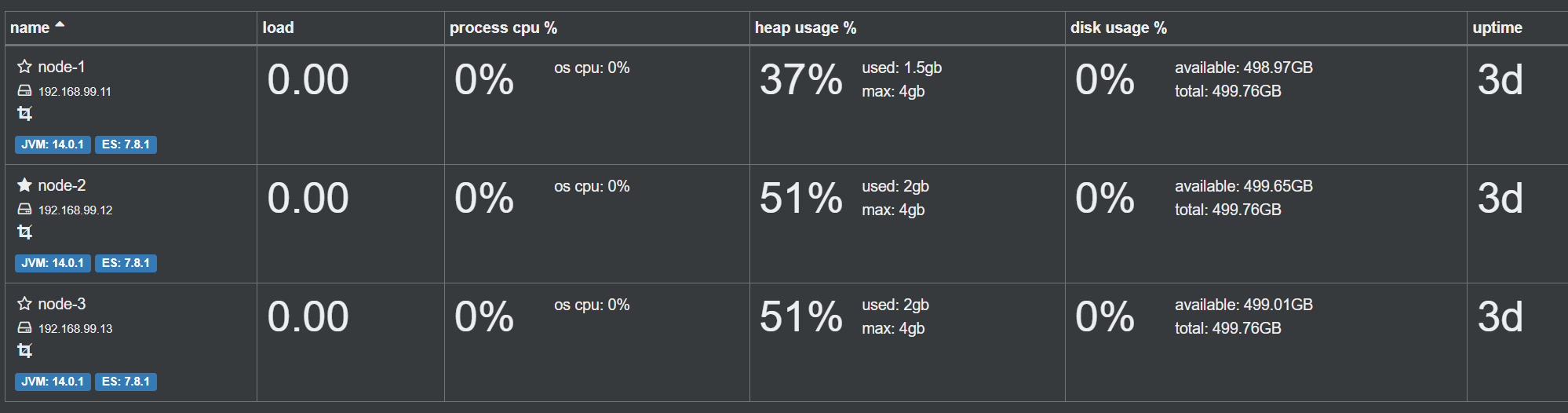
es集群节点类型
es集群中节点类型介绍cluster statemasterdatacoordinating
cluster state
cluster state:集群相关的数据称为cluster state;会存储在每个节点中,主要有如下信息:- 1.节点信息,比如节点名称、节点连接地址等
- 2.索引信息,比如索引名称、索引配置信息等
master
- 1.
es集群中只能有一个master节点,master节点用于控制整个集群的操作; - 2.
master主要维护cluster state,当有新数据产生后,master会将数据同步给其他node节点; - 3.
master节点是通过选举产生的,可以通过node.master:true指定为master节点。(默认为true)
当我们通过api创建索引PUT /test_index,cluster state则会发生变化,由master同步至其他node节点;
data
- 存储数据的节点即为
data节点,默认节点都是data累心,配置node.data:true(默认为true) - 当创建索引后,索引创建的数据会存储至某个节点,能够存储数据的节点,称为
data节点。
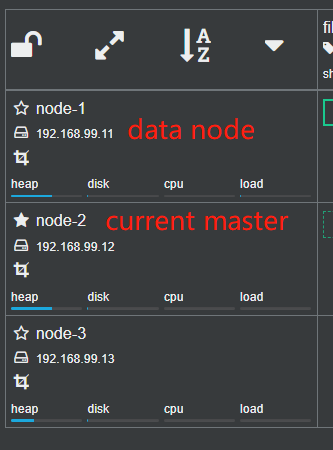
coordinating
- 处理请求的节点即为
coordinating节点,该节点为所有节点的默认角色,不能取消 coordinating节点主要将请求路由到正确的节点处理。比如创建所以的请求会由coordinating路由到master节点处理;当配置node.master:false、node.data:false则只作为coordinating节点
master-eligible node
在初始化时有资格选举的节点,在配置文件中定义
cluster.initial_master_nodes:
es集群分片副本
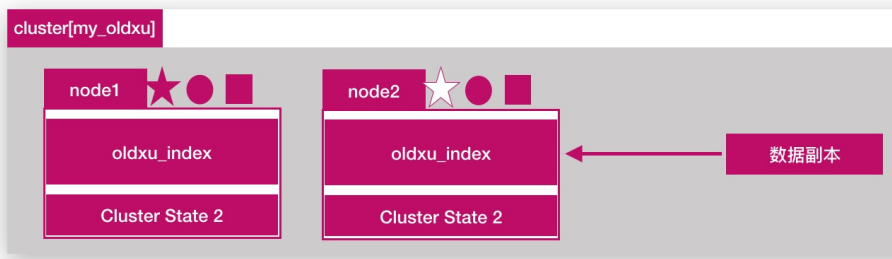
提高es集群可用性
- 如何提高es集群系统的可用性,由如下两个方面:
- 1.服务可用性:2个节点的情况下,允许其中1个节点停止服务;多个节点的情况下,坏的节点不能超过集群一半以上
- 2.数据可用性:通过副本
replication解决,这样每个节点都有完备的数据;如下所示,node2是oldxu_index索引的一个完整副本数据。
增大es集群的容量
-
如何增大
es集群系统的容量;我们需要项办法将数据均匀分布在所有节点上;- 引入分片
shard解决
- 引入分片
-
什么是分片,将一份完整数据分散为多个分片存储
- 分片是
es支持pb级数据的基石 - 分片存储了索引的部分数据,可以分布在任意节点上
- 分片存在主分片和副本分片之分,副本分片主要用来实现数据的高可用
- 副本分片的数据由主分片同步,可以有多个,用来提高读取数据性能的
- 注意:主分片数在索引创建时指定且后续不允许在更改;默认
es分片数为1个
- 分片是
-
如下图所示:在3个节点的集群中创建
oldxu_index索引,指定3个分片,和1个副本;

# 创建索引,设定主分片数量和副本数量
PUT /test_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
# 动态修改副本数量
PUT /test_index/_settings
{
"number_of_replicas": 2
}增加节点能否提高容量
问题:目前一共有3个es节点,如果此时增加一个新节点能否提高oldxu_index索引数据容量
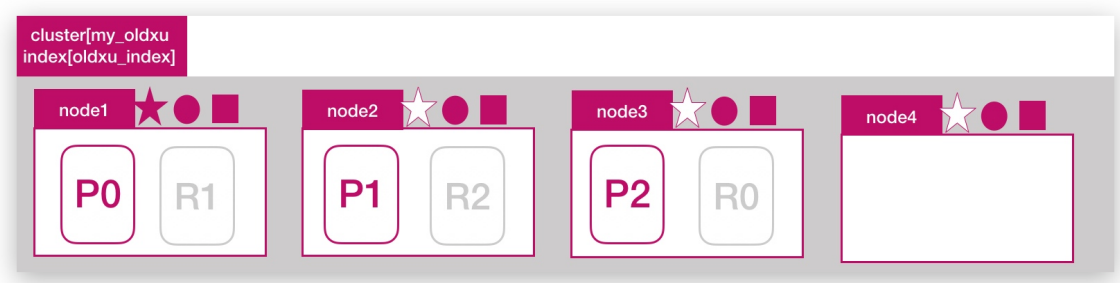
答案:不能,因为oldxu_index只有3个分片,已经分布在3台节点上,那么新增的第四个节点对于oldxu_index而言是无法使用到的。所以也无法带来数据容量的提升
增加副本能否提高读性能
问题:目前一共有3个es节点,如果增加副本数量是否能提高oldxu_index的读吞吐量
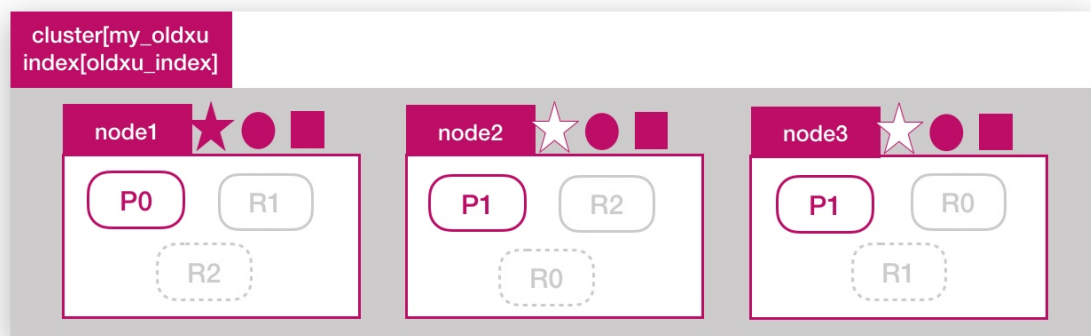
答案:不能,因为新增的副本还是会分布在node1、node2、node3这三个节点上,还是使用了相同的资源,也就意味着有读请求来时,这些请求还是会分配到node1、node2、node3上进行处理,也就意味着,还是利用了相同的硬件资源,所以不会提升读性能。
副本与分片总结
- 分片数量和副本数量的设定很重要,需要提前规划好
- 过小会导致后续无法通过增加节点实现水平扩容;
- 设置分片过大会导致一个节点上分布过多的分片,造成资源浪费。分片过多也会影响查询性能;
es集群故障转移
什么是故障转移
所谓故障转移指的是,当集群中有节点发生故障时,这个集群是如何进行自动修复的。
es集群目前是由3个节点组成,如下所示,此时集群状态是green
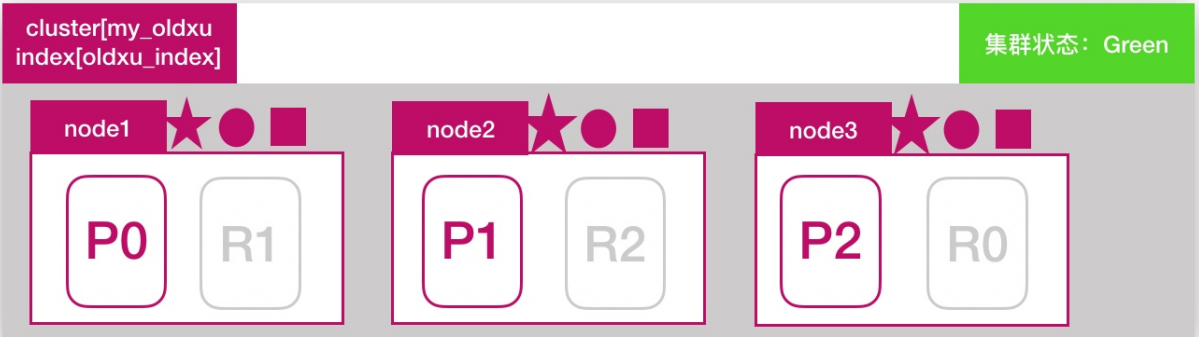
模拟节点故障
- 假设:
node1所在机器宕机导致服务终止,此时集群会如何处理;大体分为三个步骤:- 1.重新选举
- 2.主分片调整
- 3.副分片调整
重新选举
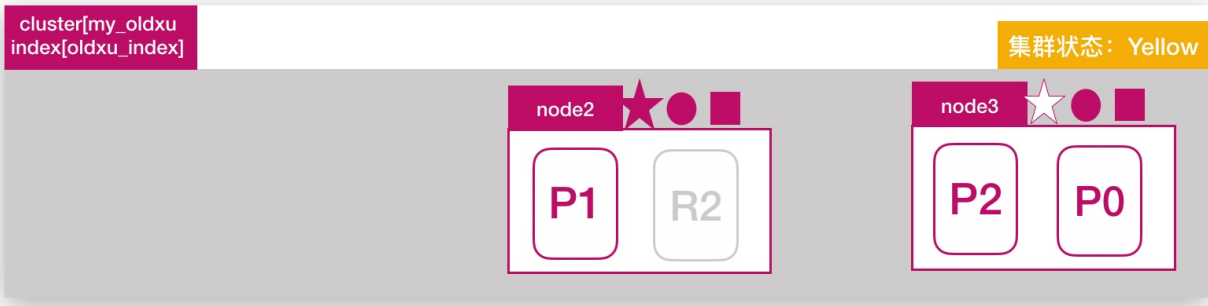
node2和node3发现node1无法响应;一段时间后会发起master选举,比如这里选择node2为master节点,此时集群状态变为red状态

主分片调整
node发现主分片p0未分配,将node3上的r0提升为主分片;此时所有的主分片都正常分配,集群状态变为yellow状态;
副本分片调整
node2将p0和p1主分片重新生成新的副本分片r0、r1,此时集群状态变为green
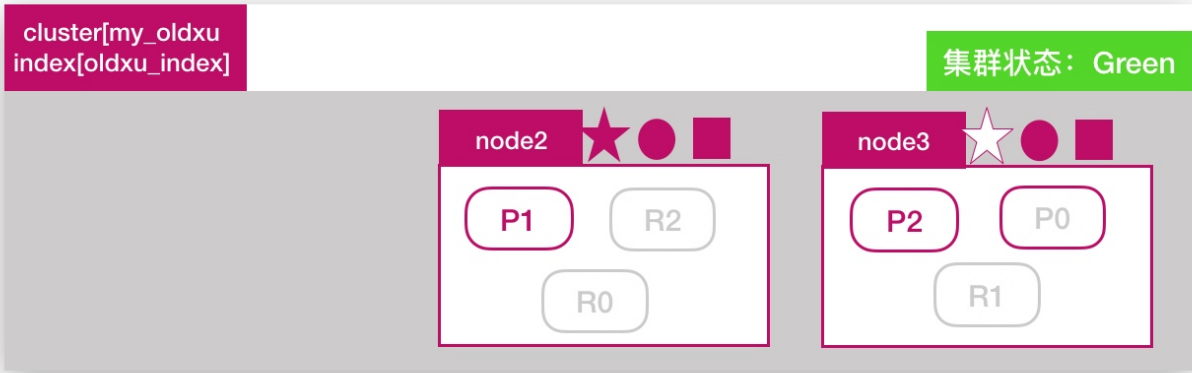
es文档路由原理
es文档分布式存储,当一个文档存储至es集群时,存储的原理是什么样的?
如下所示,当我们想一个集群保存文档时,document1是如何存储到分片p1的?选择p1的依据是什么?
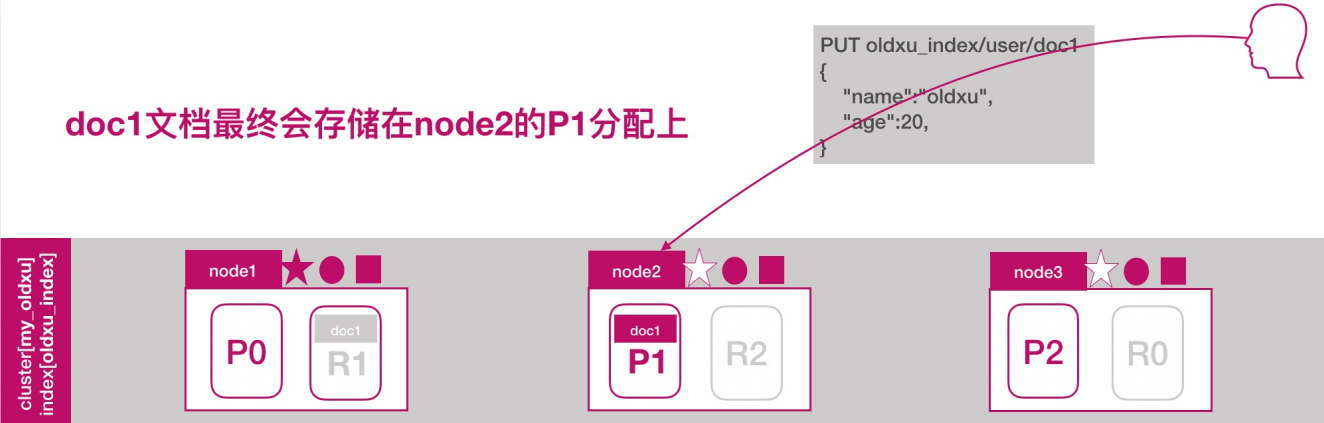
其实是有一个文档到分片的映射算法,其目的是使所有文档均匀分布在所有的分片上,那么是什么算法呢?
随机还是轮询?这种是不可取的,因为数据存储后,还需要读取,那这样的话如何读取呢?
实际上,在es中,通过如下的公式计算文档对应的分片存储到哪个节点,计算公式如下:
shard = hash(routing) % number_of_primary_shards
# hash 算法保证将数据均匀分散在分片中
# routing 是一个关键参数,默认是文档id,也可以自定义
# number_of_primary_shards 主分片数量
# 注意:该算法与主分片数量相关,一旦确定后便不能更改主分片数量
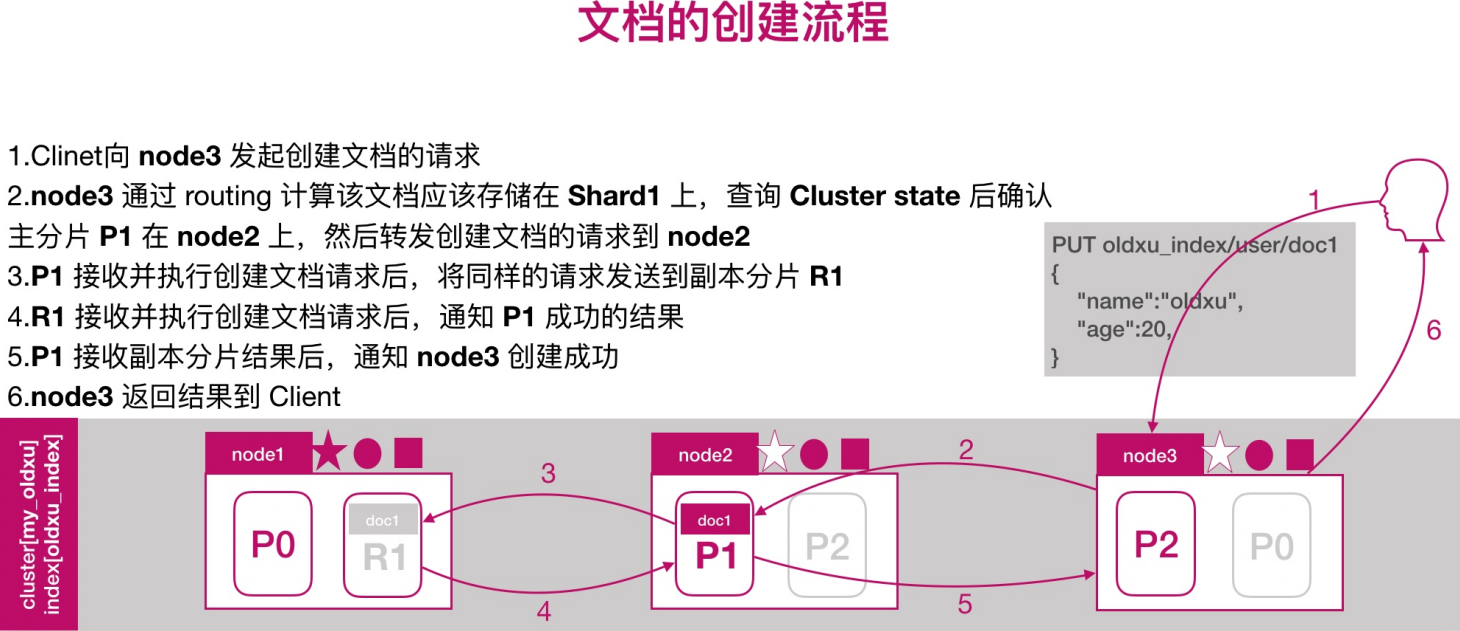
# 因为一旦修改主分片数量后,shard的计算结果就完全和修改前的完全不一样了文档的创建流程
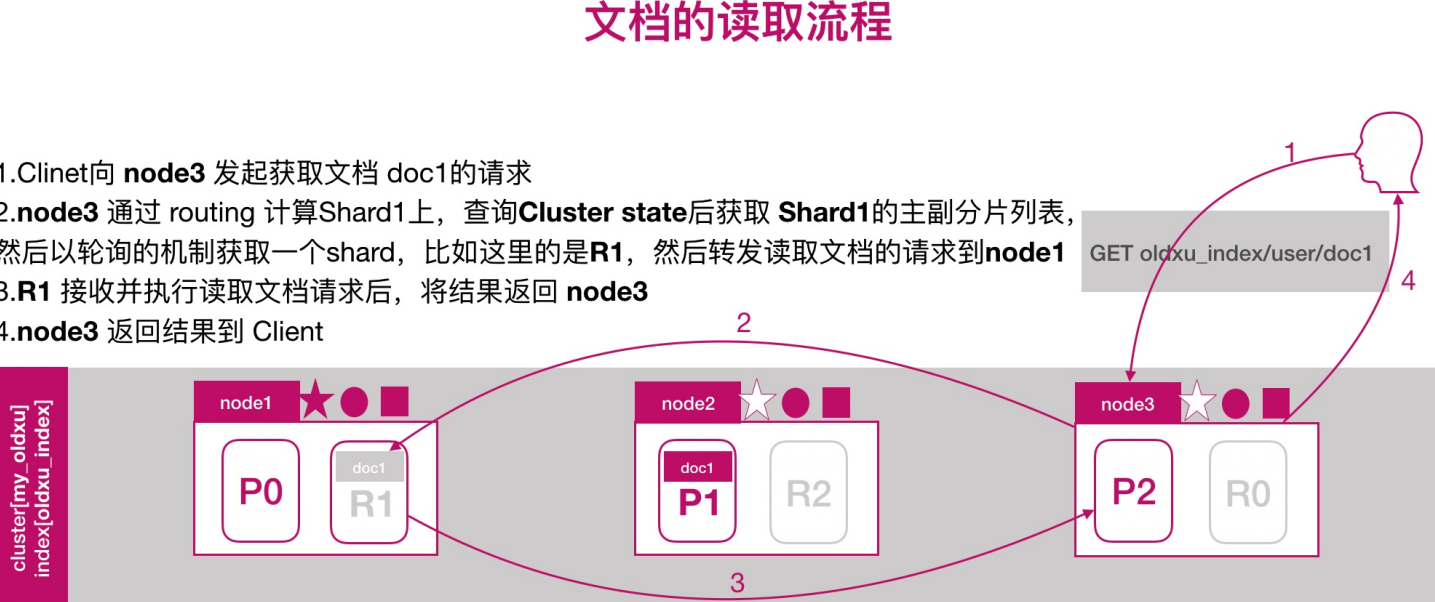
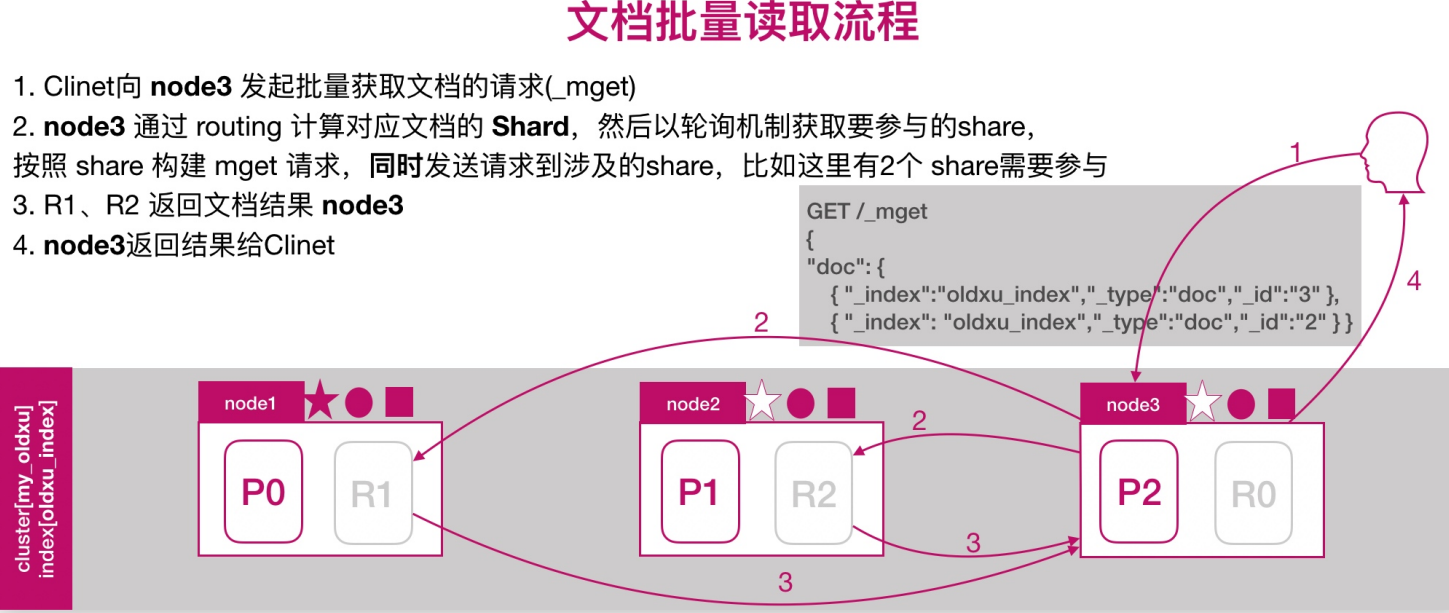
文档的读取流程
文档批量创建的流程
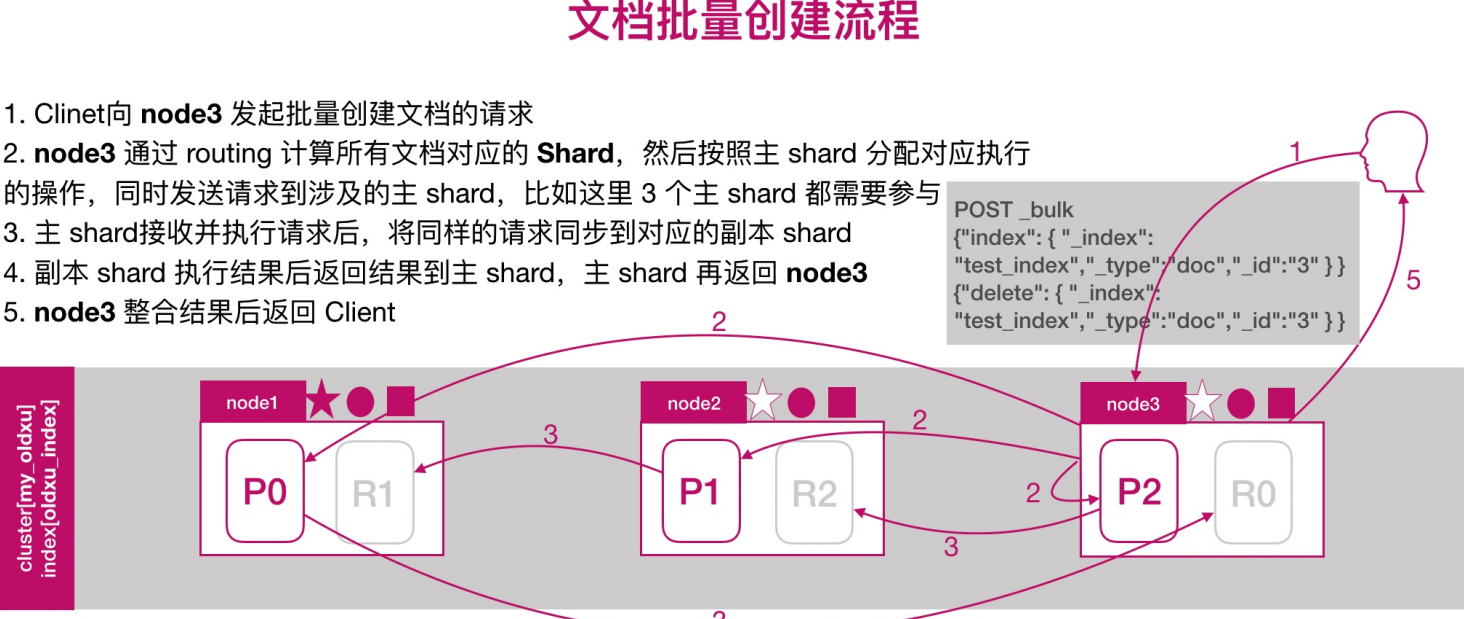
文档批量读取的流程
es扩展集群节点
节点扩展环境准备
| 主机名称 | ip地址 |
|---|---|
| es-node4 | 192.168.99.14 |
| es-node5 | 192.168.99.15 |
节点扩展配置
grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: node-4
path.data: /elkstorage
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.99.14
http.port: 9200
discovery.seed_hosts: ["192.168.99.11", "192.168.99.12","192.168.99.13"]
node.data: true # data节点
node.master: false # 不参与master选举grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: node-5
path.data: /elkstorage
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.99.15
http.port: 9200
discovery.seed_hosts: ["192.168.99.11", "192.168.99.12","192.168.99.13"]
node.data: true # data节点
node.master: false # 不参与master选举节点扩展检查
通过cerebro检查集群扩展后的状态;如果出现集群无法加入、或者集群被拒绝
尝试删除/var/lib/elasticsearch下的文件,然后重启es
如果要将data节点修改为coordinating节点;需要清理数据,否正无法启动
# repurpose 重新调整
/usr/share/elasticsearch/bin/elasticsearch-node repurposes集群调优建议
内核参数优化
# 对于操作系统,需要调整几个内核参数
vim /etc/sysctl.conf
fs.file-max = 655360 # 设定系统最大打开文件描述符数,建议修改655360或者更高
vm.max_map_count = 262144 #用于限制一个进程可以拥有的虚拟内存大小,建议修改成262144或者更高
net.core.somaxconn = 32768
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1000 65535
net.ipv4.tcp_max_tw_buckets = 400000
sysctl -p
# 调整最大用户进程数(nproc),调整进程最大打开文件描述符(nofile)
rm -f /etc/security/limits.d/20-nproc.conf # 删除默认nproc设定文件
vim /etc/security/limits.conf
* soft nproc 20480
* hard nproc 20480
* soft nofile 65536
* hard nofile 65536配置参数优化
# 锁定物理内存地址,避免es使用swap交换分区,频繁的交换,会导致iops变高
vim /etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: true
# 配置elasticsearch启动参数
vim /usr/lib/systemd/system/elasticsearch.service
在[Service]下加多一行
LimitMEMLOCK=infinity
sed -i '/\[Service\]/a LimitMEMLOCK=infinity' /usr/lib/systemd/system/elasticsearch.service
systemctl daemon-reload
systemctl restart elasticsearch.servicejvm参数优化
jvm内存具体要根据node存储的数据量来估算,为了保证性能,在内存和数据间有一个建议的比例:
像一般日志类文件,1G内存能够存储48G~96GB数据;
jvm堆内存最大不要超过31G;
其次就是主分片的容量,单个控制在30~50GB;
假设每天总数据量为xGB;3个node节点,1个副本;
那么实际要存储的大小为2xGB,因为由一个副本的存在;
2xGB / 3 / 0.8 = 0.8xGB,因为每个节点需要预留约20%的空间,意味着每个node要存储大约0.8xGB的数据;
安装内存与存储数据的比率计算(假设每个node的内存为8G):
0.8xGB / 48 = 8GB,得出x = 480GB,(8G内存可以满足每天480GB的日志量)
所以目前node节点的配置为内存8G,挂在存储目录/elkstorage为500GB
还要尽量控制主分片的大小为30~50GB
vim /etc/elasticsearch/jvm.options
-Xms8g
-Xmx8g
# 根据服务器内存8G,修改为4G。一般设置为服务器物理内存的一半为最佳,但最大不能超过32G
留言