基本概念
首先grafana是一个通用的可视化工具。可以实现全面定制面板,观察所有数据,达到把所有的数据进行可视化。grafana不绑定数据,可以和任何支持的数据源进行数据可视化。
grafana
grafana工具是直接支持prometheus时序数据库数据源,grafana通过对prometheus数据的查询加工和面板的设置,可以自定义出精美的数据可视化面板,所以在使用前我们要对grafana有个基本的概念。
数据源(data source)
对于grafana而言,prometheus这类为其提供数据的对象都称为数据源(data source)。对于grafana使用者而言,只需要对这些对象以数据源的形式添加到grafana中,grafana便可以轻松的实现对这些数据的可视化工作。
下面演示下添加数据源为例:
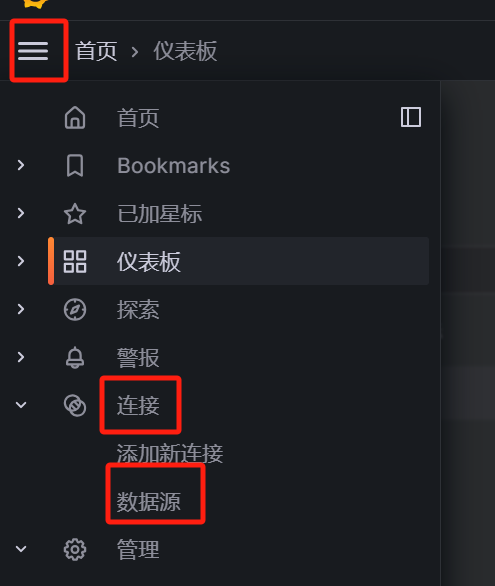
点击:菜单栏--> connections --> data source --> add data source,最后选择prometheus数据源。
配置prometheus数据源,如下所示:
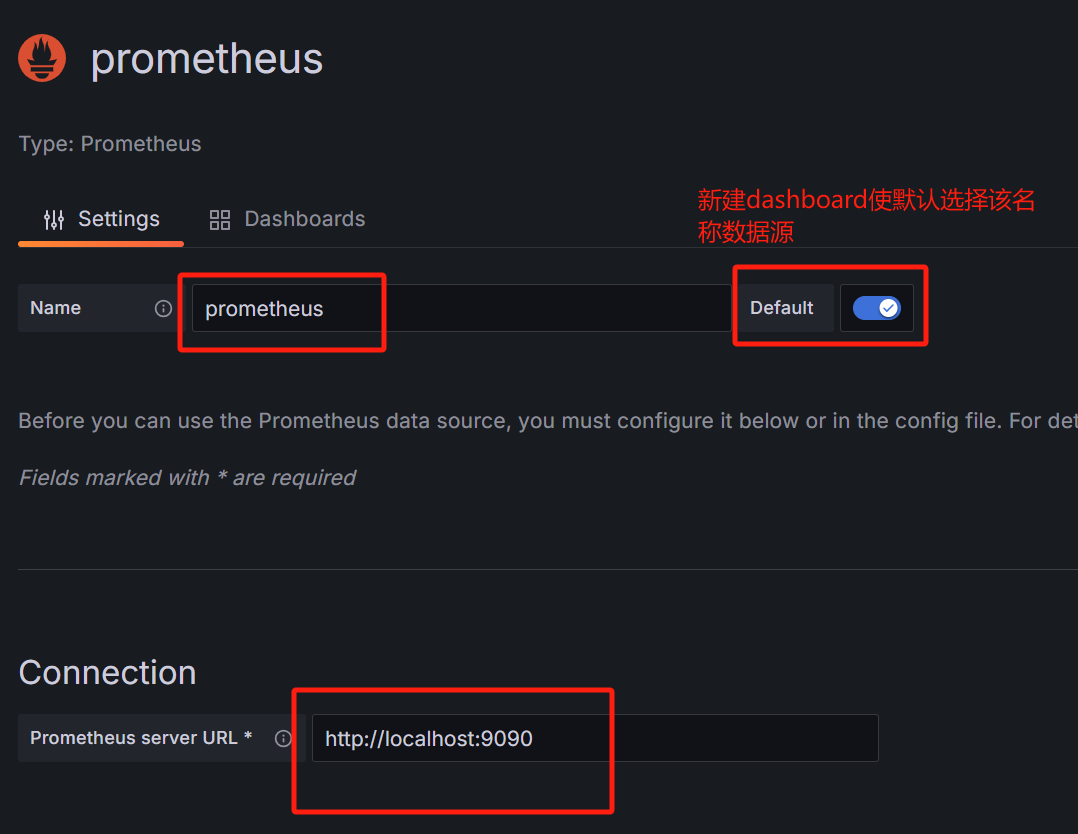

关于performance一般选择prometheus,版本安装你实际安装的版本选择。
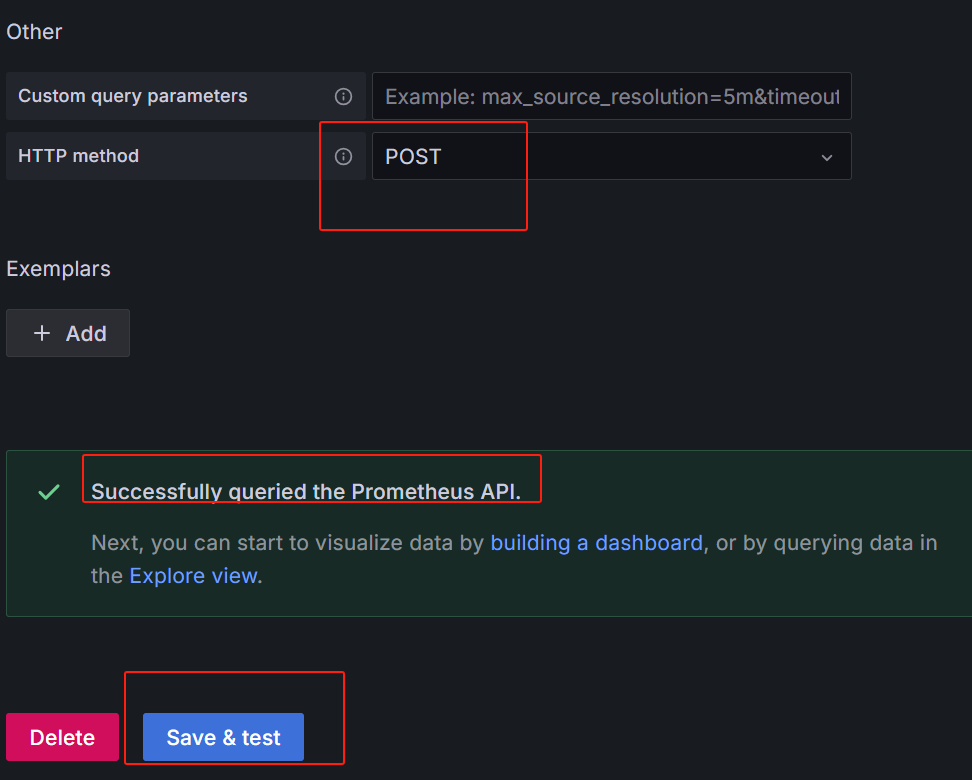
最后点击:保存并测试,如下所示,就代表数据源配置成功。
仪表板(dashboard)
上面添加好数据源后,对于grafana的使用者而言最重要的事情就是对这些数据实现数据可视化。数据可视化在grafana中有个统一的称呼就是dashboard,我们通过dashboard来组织和管理我们的数据可视化图表:

如上所示,在一个dashboard中一个最基本的可视化单元为一个panel(面板),panel通过如趋势图,热力图的形式展示可视化数据。
并且在dashboard中每一个panel是一个完全独立的部分,通过panel的query editor(查询编辑器)我们可以为每一个panel配置自己查询的数据源以及数据查询方式。
例如,如果以prometheus作为数据源,那么query editor中,我们实际上使用的是PromQL,而panel则会负责从特定的prometheus中查询出相应的数据,并且将其可视化。由于每个panel是完全独立的,因此在一个dashboard中,可以包含来自多个data source的数据。
grafana提供了很多panel的实现,常用的有:time series、gauge、pie chart、table、stat、text等待,grafana通过json数据结构管理整个dashboard的定义,所以共享很方便,同时也可以共享到社区中,grafana提供了一个仪表板共享社区,可以在上面找到别人定义分析的仪表板。
模板化Dashboard
当大部分查询写死以后,会遇到很多问题,比如:模板分享给其他人后,会因为 Dashboard 设置的源不通而导致数据无法查询,又或者需要动态切换条件,进行数据的切换展示,故 Grafana 提供了一个非常强大的工具: Dashboard Variables。
面板介绍
什么是面板
面板(panel)是grafana中最基本的可视化单元,每一种类型的面板都提供了相应的查询编辑器(query editor),让用户可从不同的数据源(如prometheus)中查询出相应的监控数,并且以可视化的方式展现,所以要在grafana上创建可视化的图表,面板是我们需要掌握的;
能创建哪些面板
grafana提供了各种可视化来支持不同的用例,目前内置支持的面板包括:
time series(时间序列)是默认的也是最主要的图形可视化面板
bar chart(条形图)
histogram(直方图)
heatmap(热力图)
pie chart(饼状图)
stat(统计数据)
gauge、bar gauge、table
dashboard list(仪表板列表)
alert list(报警列表)
text panel(文本面板,支持markdown和html)
面板创建
创建面板
-
创建一个
panel面板,选择对应的数据源为prometheus,输入查询cpu使用率的指标:(1-avg(rate(node_cpu_seconds_total{job="X10360S",mode="idle"}[5m])) by (instance))*100 -
再创建一个
panel面板,输入查询内存使用率的指标:(node_memory_MemTotal_bytes{job="X10360S"}-node_memory_MemAvailable_bytes{job="X10360S"})/node_memory_MemTotal_bytes{job="X10360S"}*100
面板属性修改
-
选择右侧的
panel option,通过title定义panel名称 -
默认指标展示的结果为单个序列的值;但是我们有多个序列,希望同时展示多个序列的结果,因此可以通过右侧的
tooltip来调整tooltip mode工具条显示的模式:single显示单个,all显示多个value sort order排序方式:ascending从小到大升序;descending从大到小降序
-
指标单位调整
对于cpu使用率,它所表示的是百分比,但目前显示的并非百分比,因此需要进行单位调整,通过standard options(标准选项)-->unit(单位)设定对应的单位为百分比模式misc-->percet(0-100);decimals(小数),2位小数。 -
当一个
panel有多个查询表达式时,无法直接通过序列,观察出该序列所表示的含义;再添加一个user模式的cpu使用率:avg(rate(node_cpu_seconds_total{job="X10360S",mode="user"}[5m])) by (instance)*100;因此,我们需要通过指标的option-->legend(图例)来对序列曲线进行别名设定。legend选择custom(定制的):{{instance}}cpu整体使用率 -
legend部分的展示会带上:9100端口号,但这对于展示来说没有太大的意义,因此可以去掉该端口。点击transform选项,添加rename filed by regex转换器,该转换器可以通过正则的方式对结果进行重命名。match:(.*):9100(.*)replace:$1$2
MSR3600监控面板
变量设置
Job变量
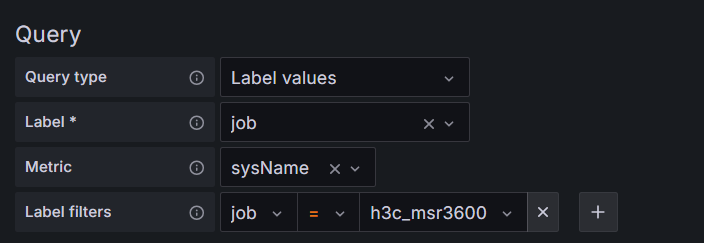
把sysname指标中的job标签值为h3c_msr3600的job标签值赋值给Job变量,即$Job=h3c_msr3600
IP变量
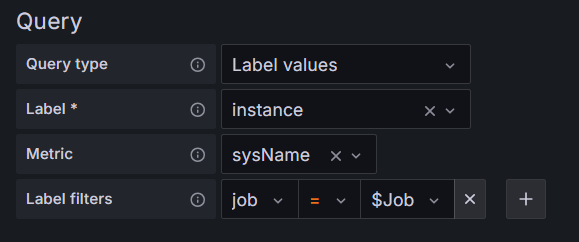
把sysname指标中的job标签值为$Job的instance标签值赋值给IP变量
Interface变量
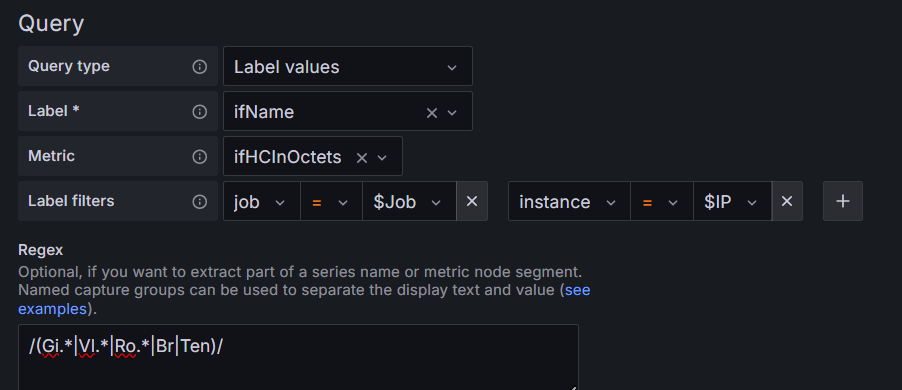
把ifHCInOctets指标中的job标签值为$Job,instance标签值为$IP的ifname标签值赋值给Interface变量。
用正则表达式/(Gi.*|Vl.*|Ro.*|Br|Ten)/,过滤出接口名称含GigabitEthernet、Vlan-interface、Route-Aggregation、Bridge-Aggregation、Ten-GigabitEthernet的接口
Uplink变量
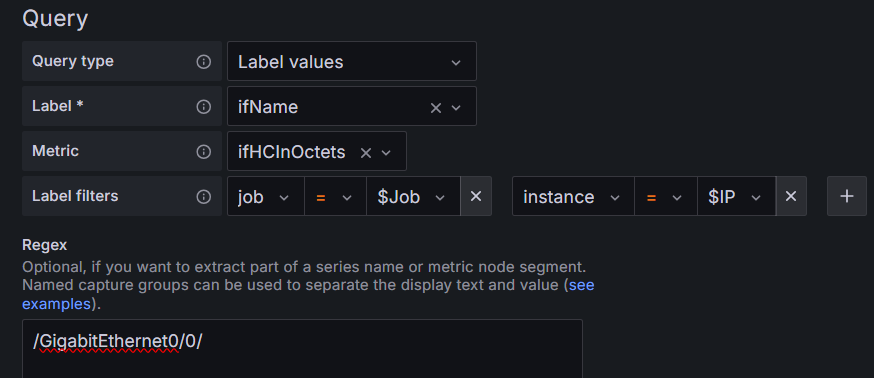
把ifHCInOctets指标中的job标签值为$Job,instance标签值为$IP的ifname标签值赋值给Uplink变量。
用正则表达式/GigabitEthernet0/0/,过滤出上行接口GigabitEthernet0/0
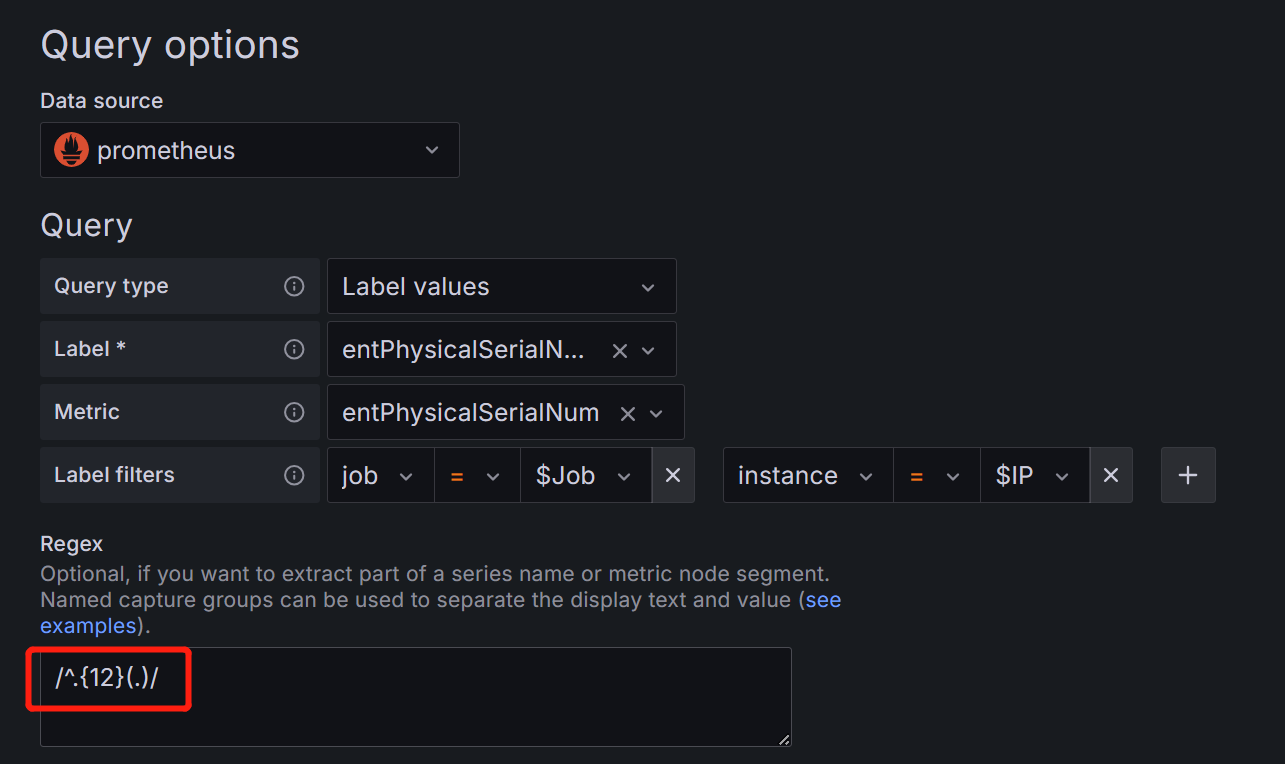
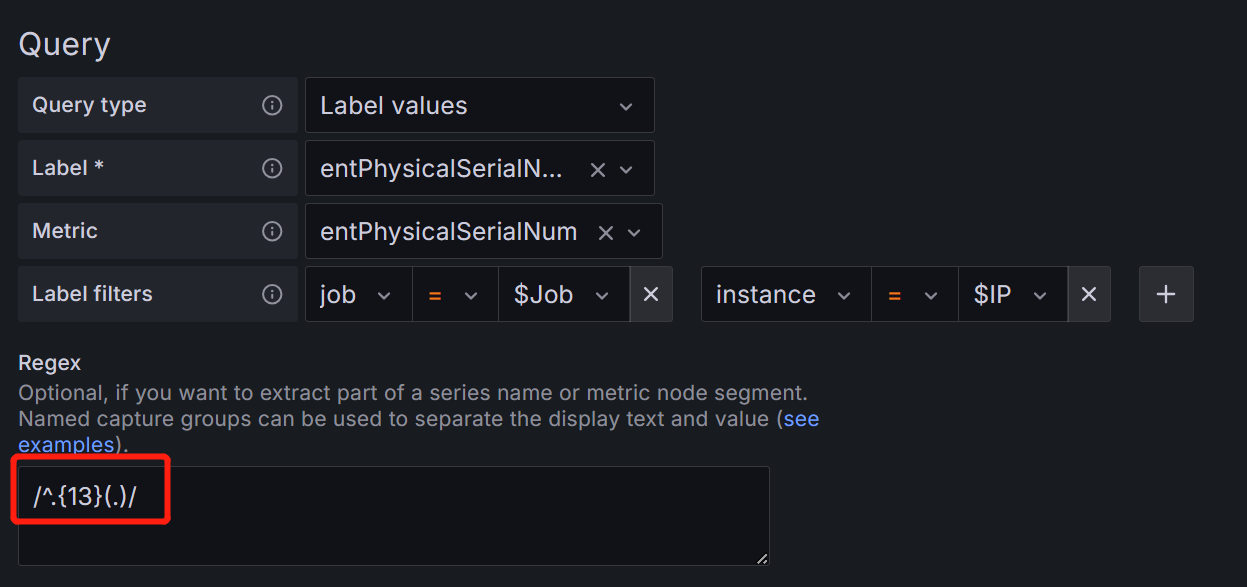
SN变量(序列号)

把entPhysicalName指标中的job标签值为$Job,instance标签值为$IP,entPhysicalName标签值为RPU的entPhysicalSerialNum标签值赋值给SN变量。
MFD_year变量(制造年份)
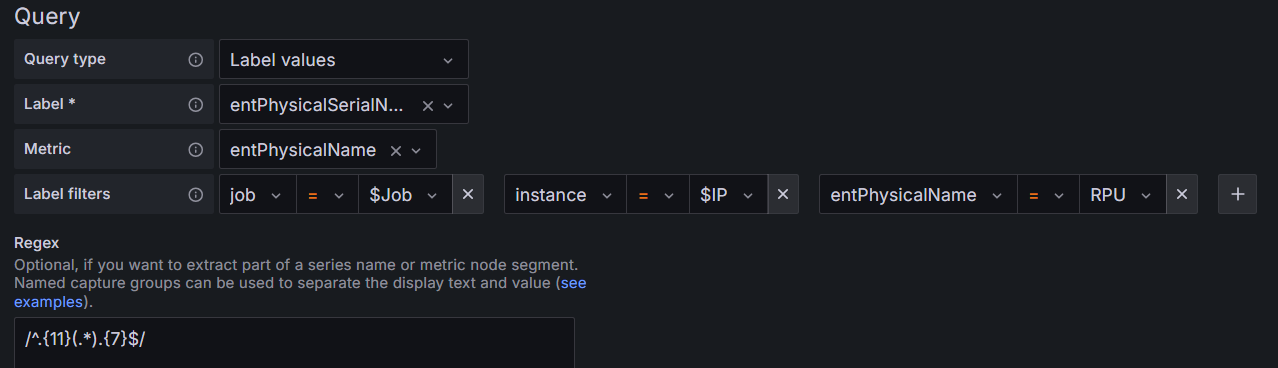
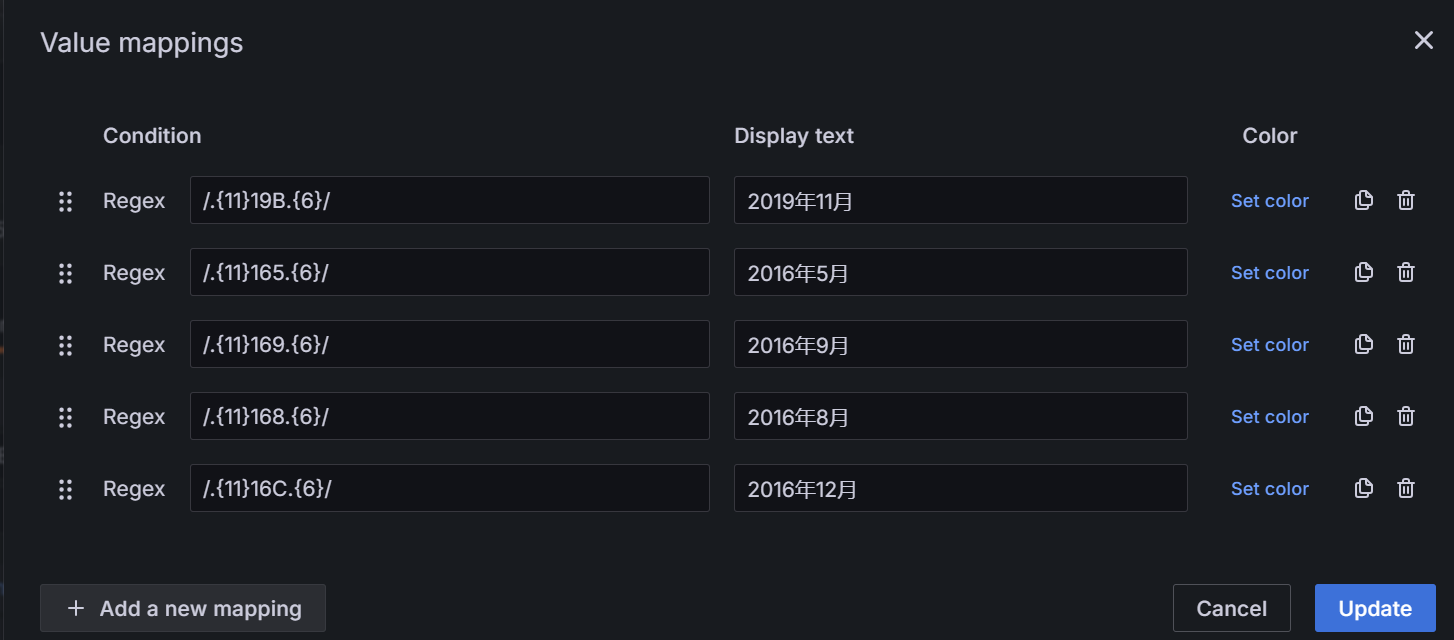
用正则表达式/^.{11}(.*).{7}$/,过滤出第12和第13位
MFD_month变量(制造月份)
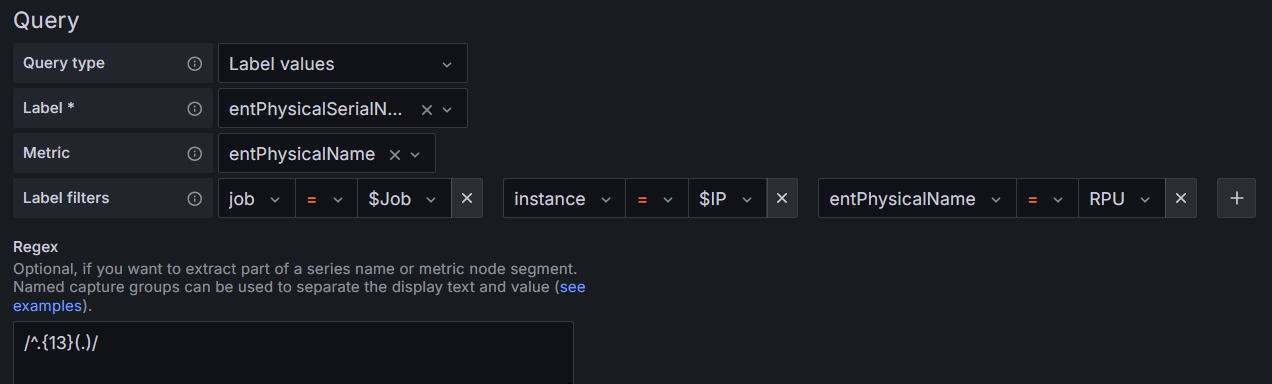
用正则表达式/^.{13}(.)/,过滤出第14位
Node_total变量(节点数量)
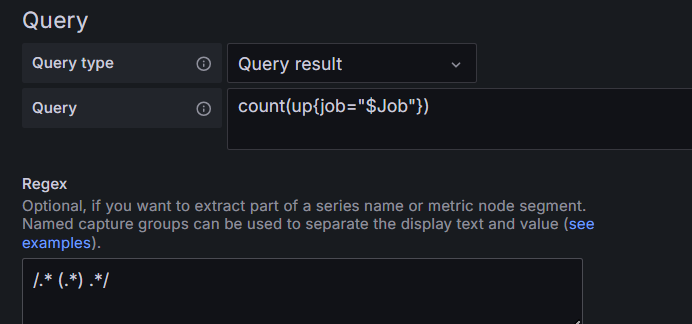
用正则表达式/.* (.*) .*/,过滤出数量
面板设置
- 节点在线数面板
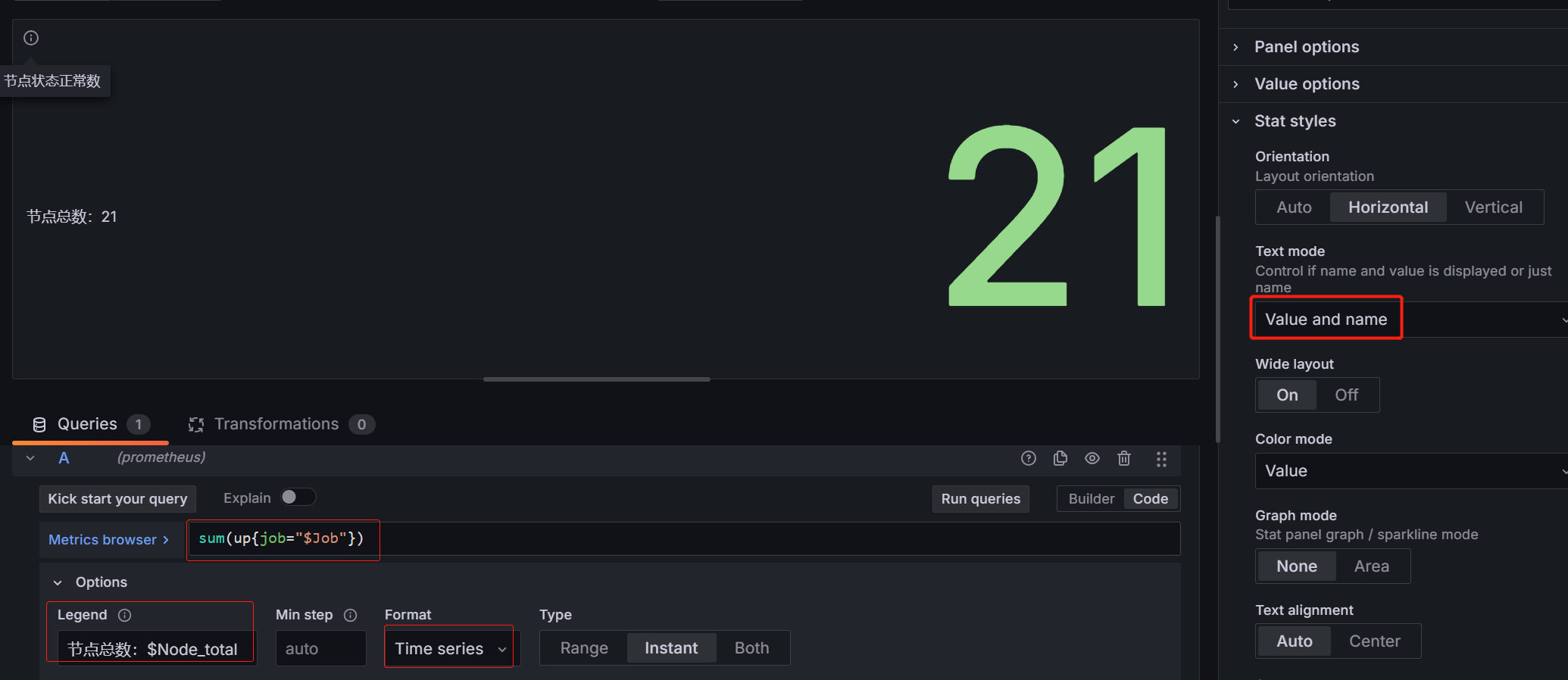
指标:sum(up{job="$Job"})
图例(legend):节点总数:$Node_total(变量)
选择Time series才有图例
Text mode:选择value and name
- 下行总流量面板
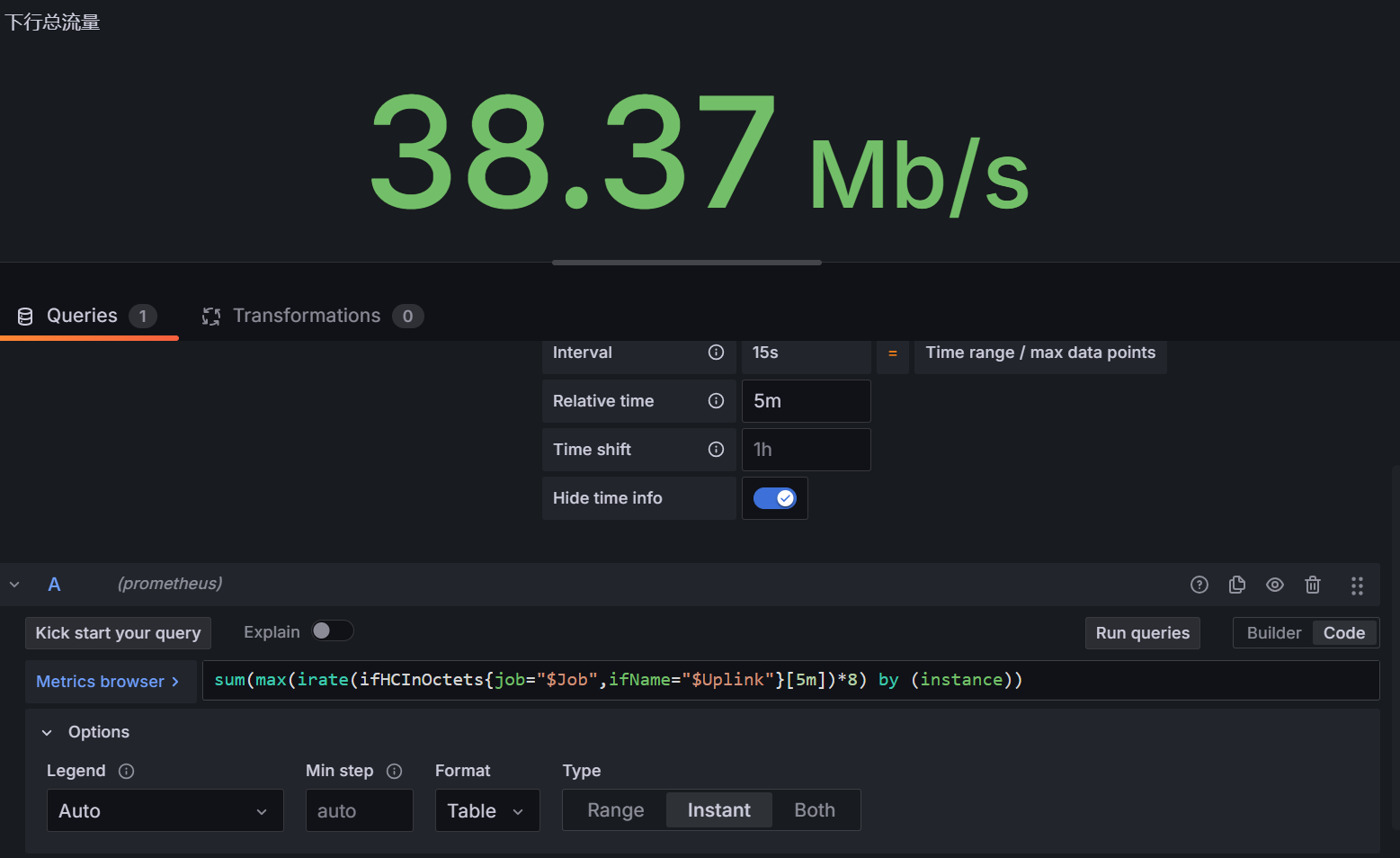
指标:sum(max(irate(ifHCInOctets{job="$Job",ifName="$Uplink"}[5m])*8) by (instance))
query option:relative time:5m hide time info
- 最大下行流量(单个节点)面板
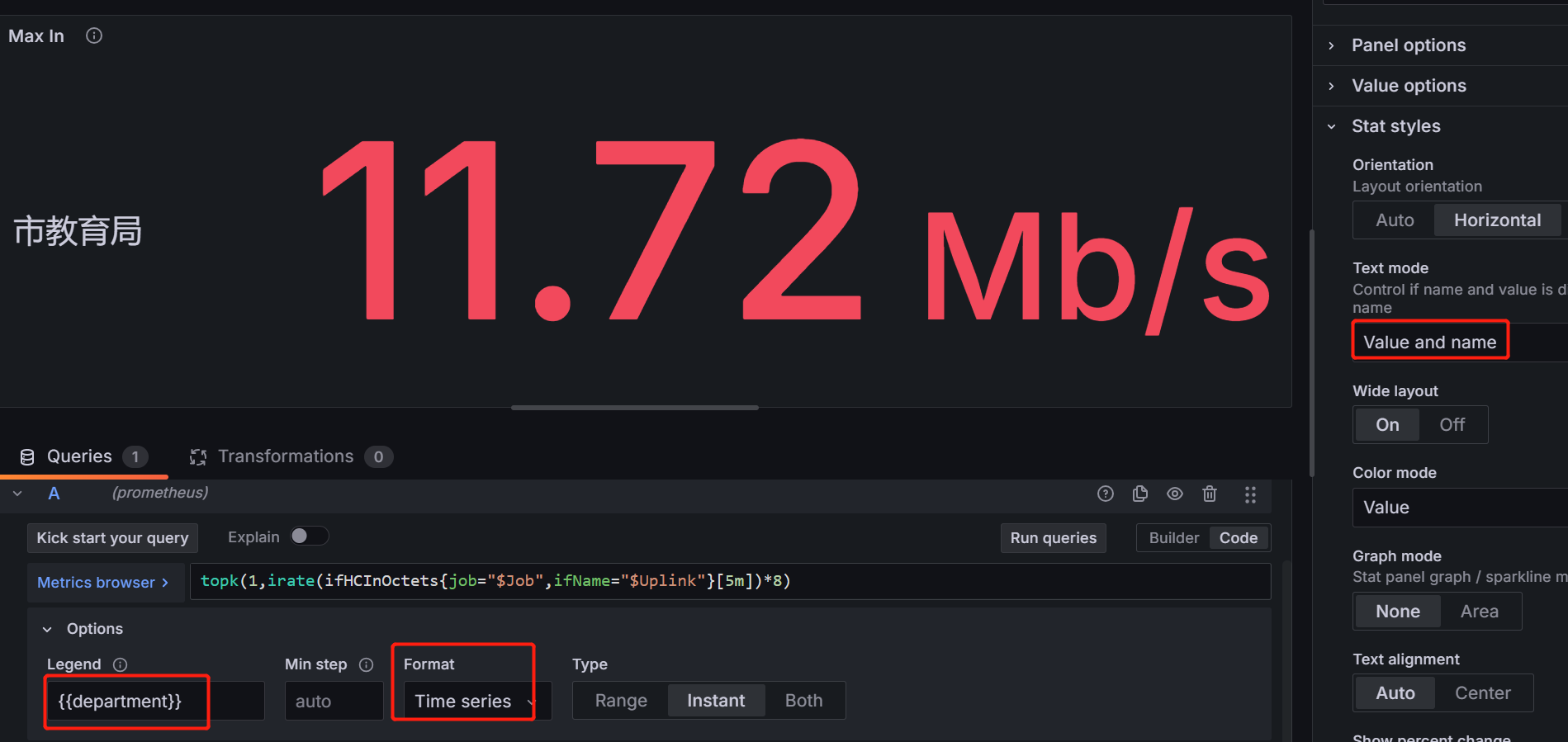
指标:topk(1,irate(ifHCInOctets{job="$Job",ifName="$Uplink"}[5m])*8)
query option:relative time:5m hide time info
legend:{{department}}
formate:time series
router name面板
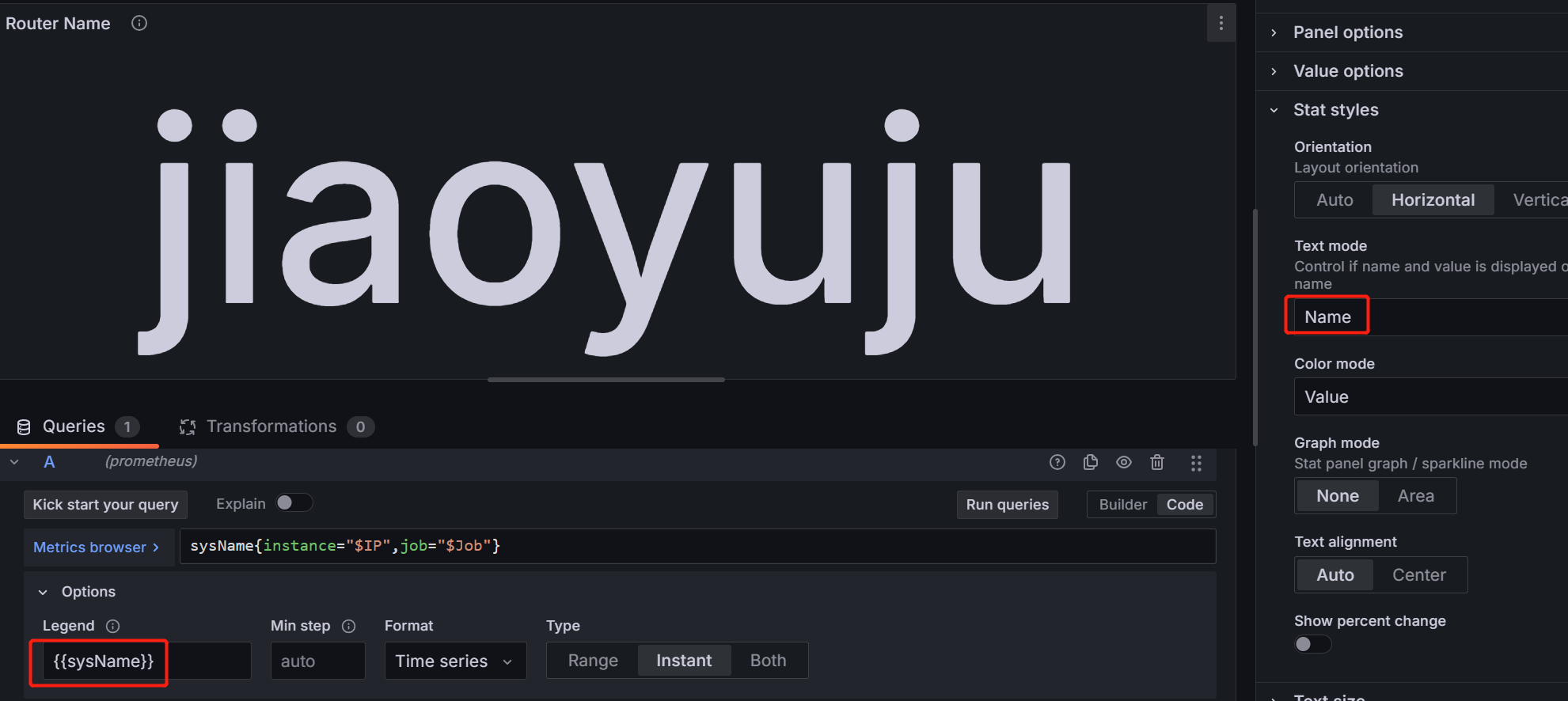
指标:sysName{instance="$IP",job="$Job"}
legend:{{sysName}}
formate:time series
text mode:name
- 电源1状态面板
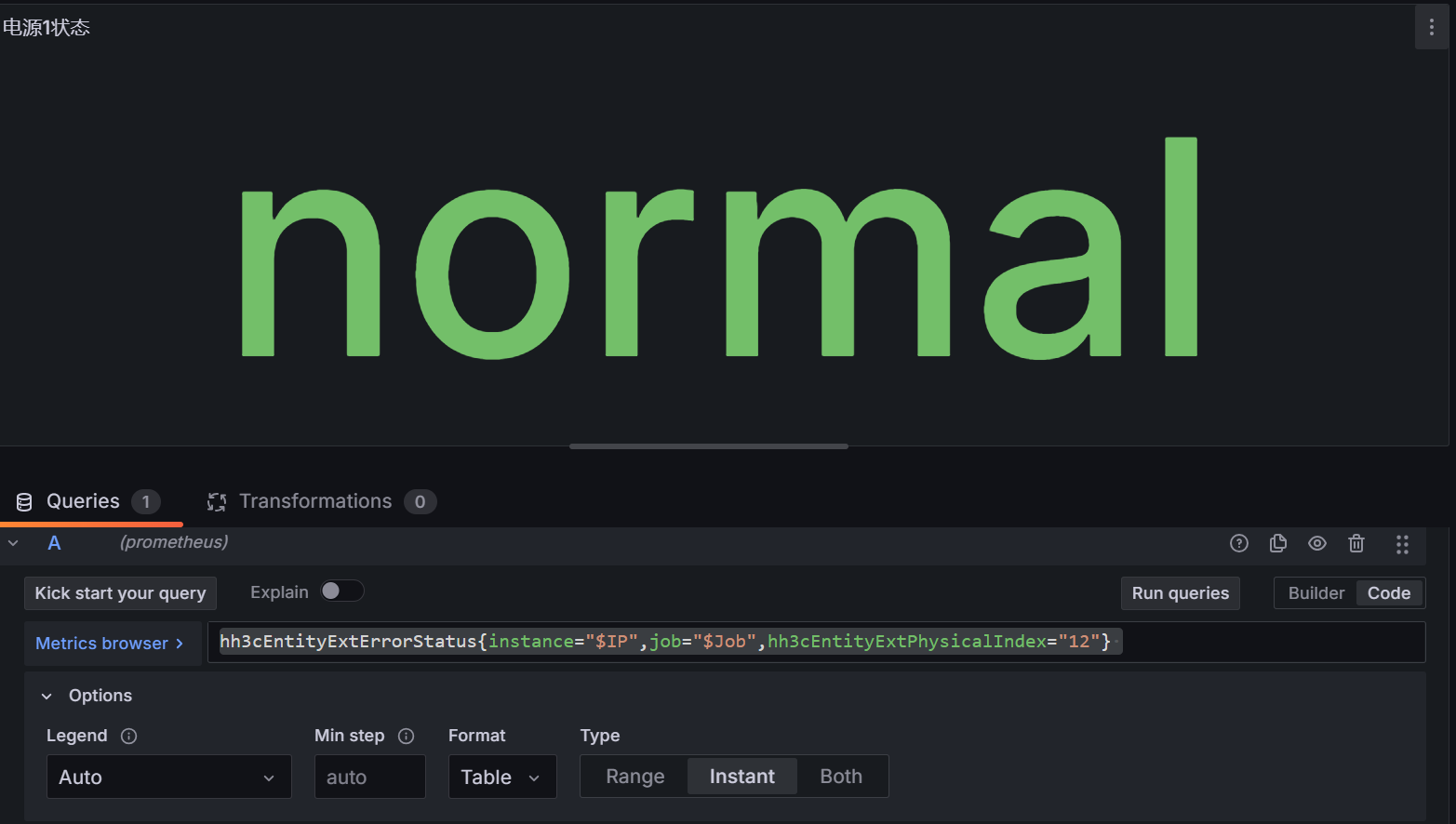
指标:hh3cEntityExtErrorStatus{instance="$IP",job="$Job",hh3cEntityExtPhysicalIndex="12"}
- 风扇状态面板
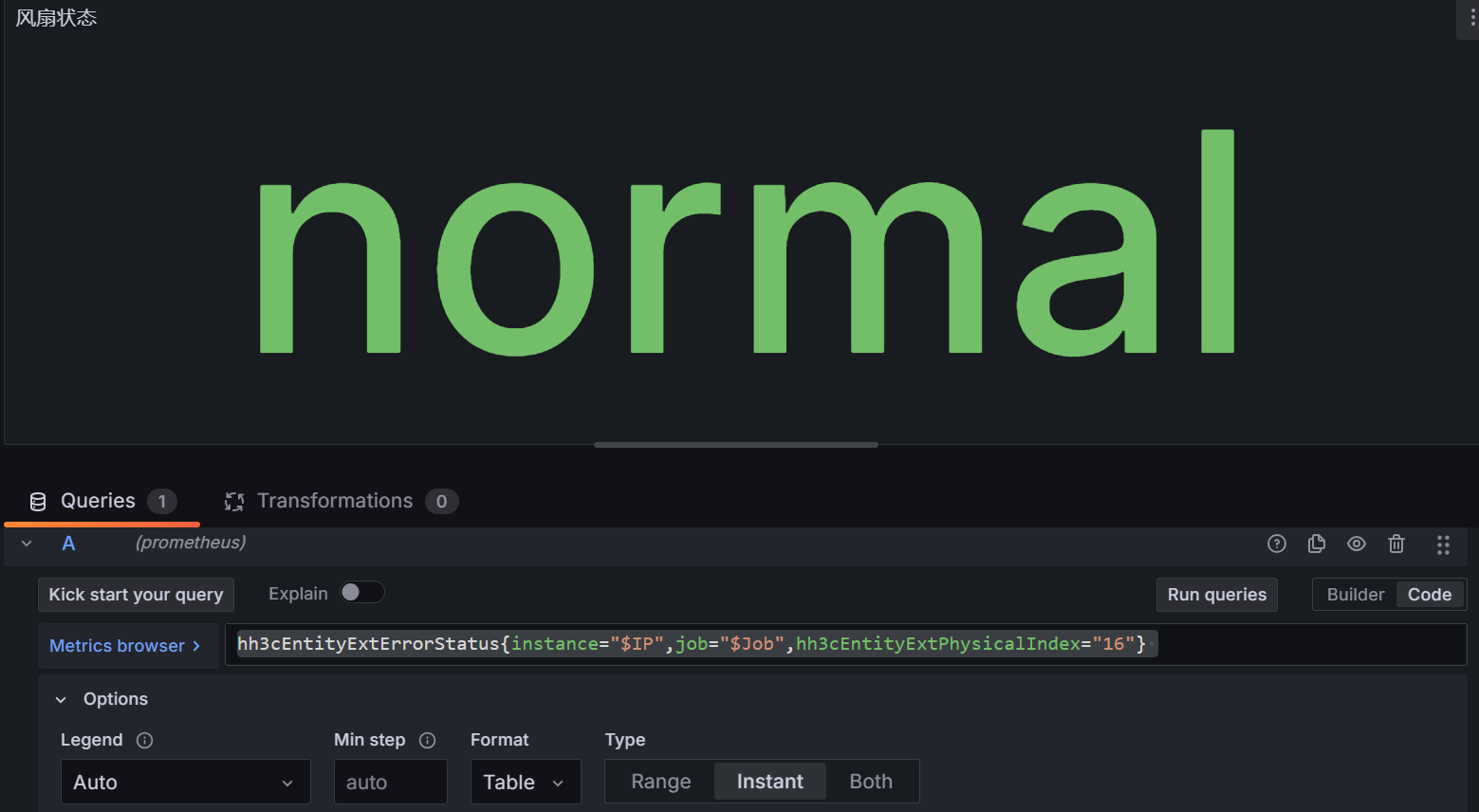
指标:hh3cEntityExtErrorStatus{instance="$IP",job="$Job",hh3cEntityExtPhysicalIndex="16"}
- 运行时间面板
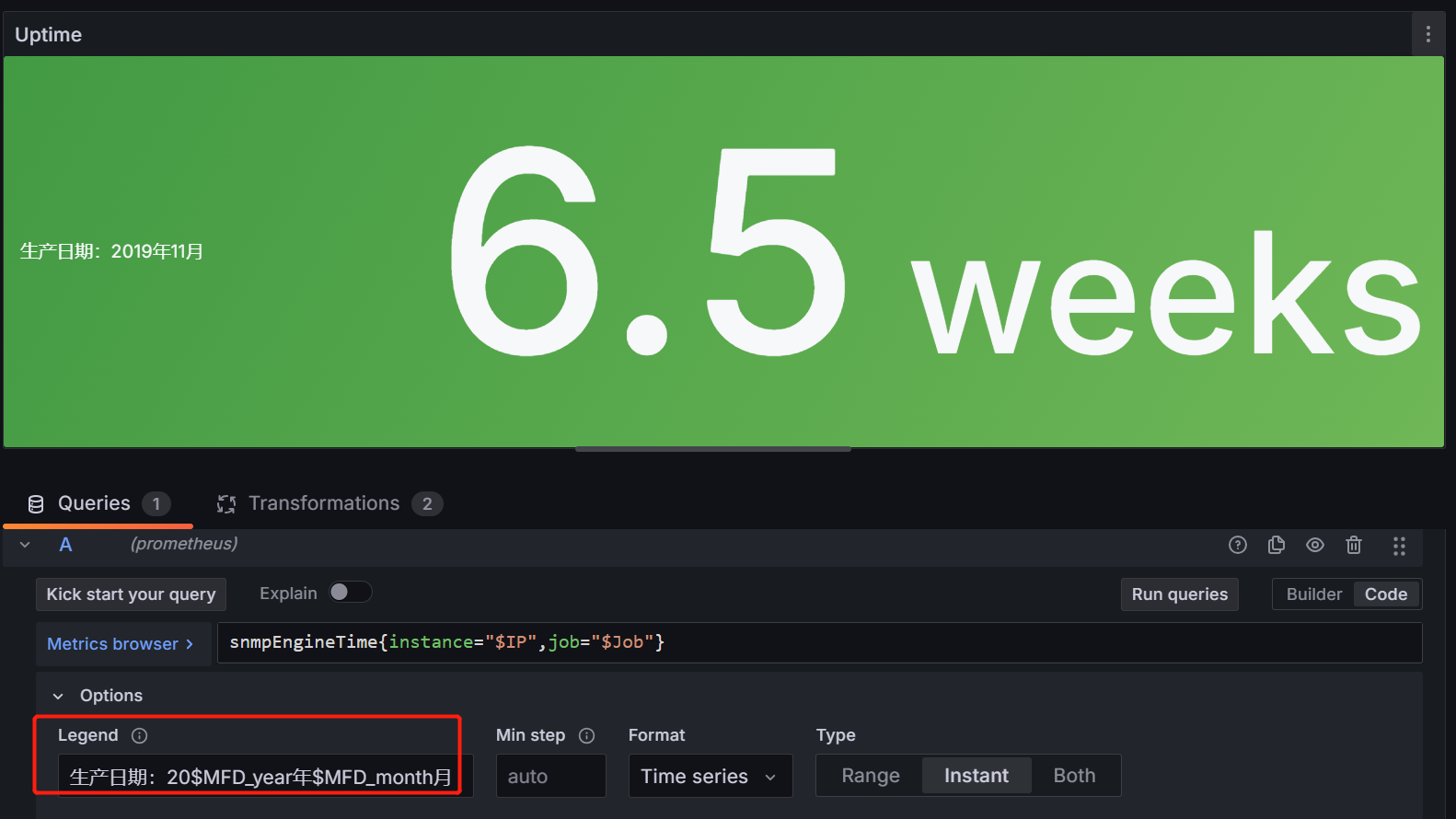
legend:生产日期:20$MFD_year年$MFD_month月
formate:tiem series
text mode:value and name
- 节点概述表格
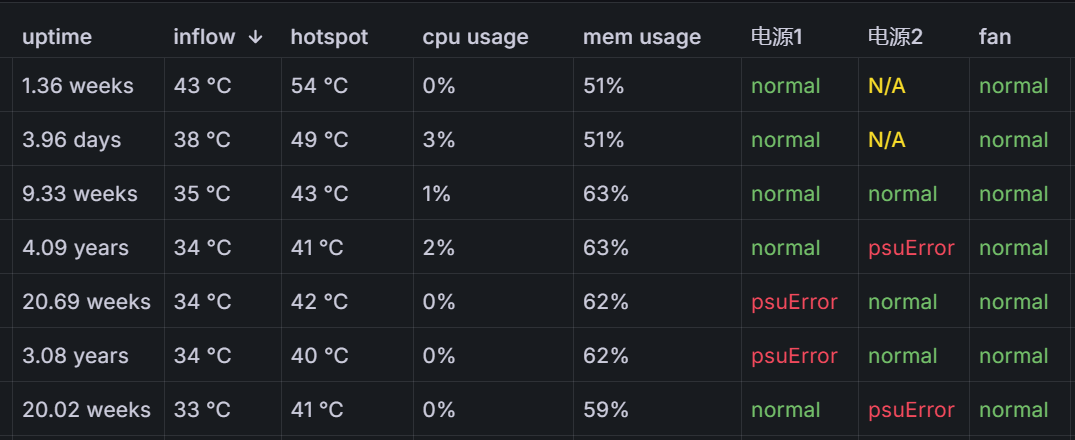
-
A查询:snmpEngineTime { job="$Job" }取运行时间 -
B查询:hh3cEntityExtTemperature{ job="$Job",hh3cEntityExtPhysicalIndex="89"}取inflow处的温度 -
C查询:hh3cEntityExtTemperature{ job="$Job",hh3cEntityExtPhysicalIndex="90"}取hotspot处的温度 -
D查询:hh3cEntityExtCpuUsage { job="$Job" }取cpu使用率 -
E查询:hh3cEntityExtMemUsage { job="$Job" }取内存使用率 -
F查询:hh3cEntityExtErrorStatus{job="$Job",hh3cEntityExtPhysicalIndex="12"}取电源1状态 -
G查询:hh3cEntityExtErrorStatus{job="$Job",hh3cEntityExtPhysicalIndex="13"}取电源2状态 -
H查询:hh3cEntityExtErrorStatus{job="$Job",hh3cEntityExtPhysicalIndex="16"}取风扇状态 -
I查询:entPhysicalName{job="$Job"}取该指标的标签entPhysicalSerialNum即序列号 -
I查询:entPhysicalName{job="$Job"}取该指标的标签entPhysicalSerialNum经匹配正则表达式后获取生产日期 -
两个表格转换
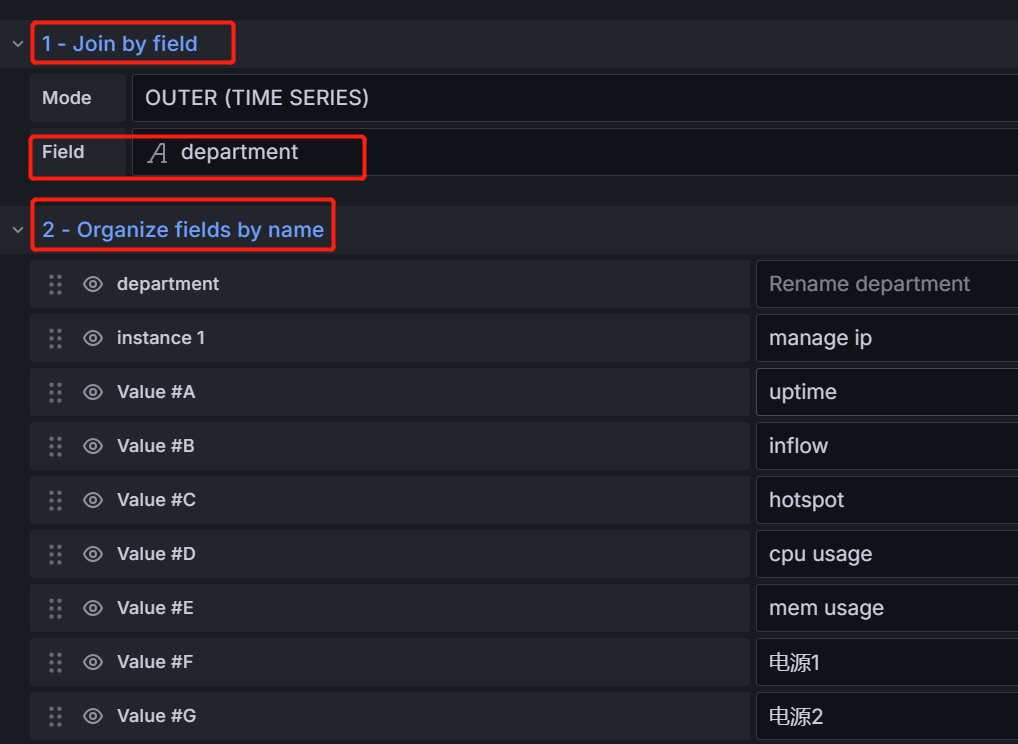
join by field依据department字段合并表格
organize fields by name改字段名和隐藏字段。
- 生产日期的正则
- 接口
ip地址表格

A查询:ipAdEntAddr{job="$Job",instance="$IP"}- 表格转换:
Organize fields by name
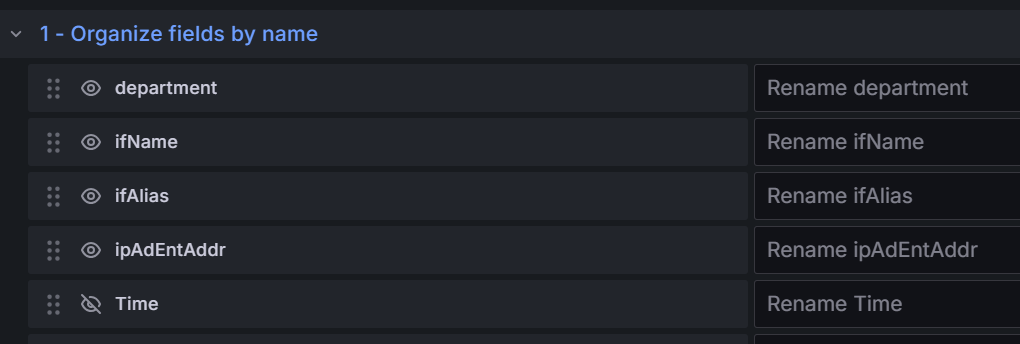
- 选定接口详情表格
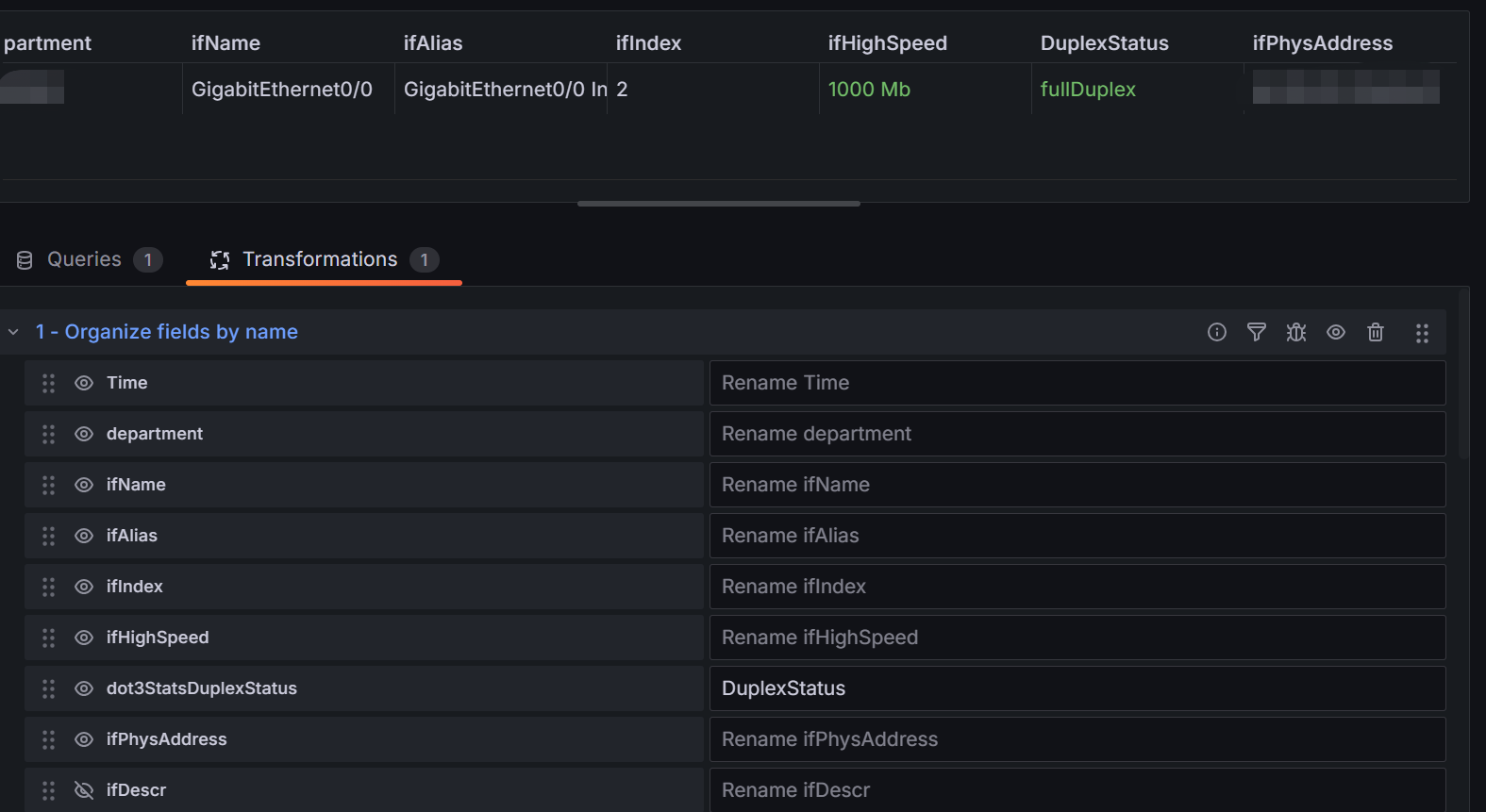
A查询:irate(ifHCOutOctets{job="$Job",instance="$IP",ifName=~"$Interface"}[5m])*8- 表格转换:
Organize fields by name
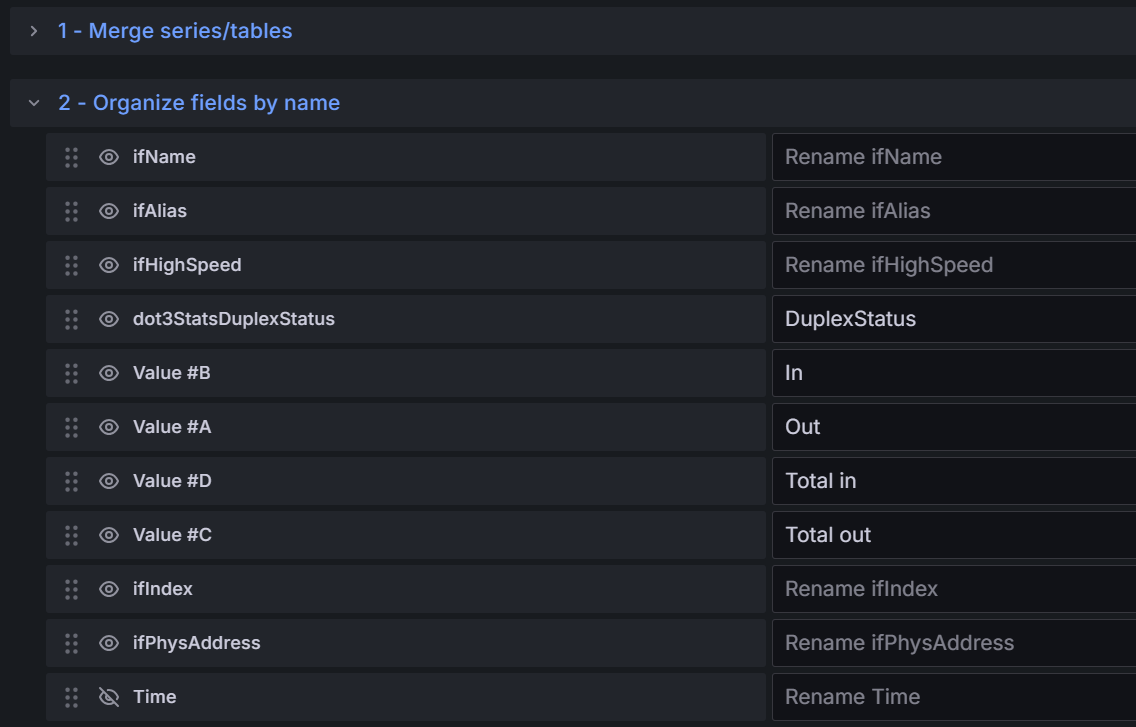
- 所有接口详情表格
A查询:irate(ifHCOutOctets{job="$Job",instance="$IP"}[5m])*8B查询:irate(ifHCInOctets{job="$Job",instance="$IP"}[5m])*8C查询:delta(ifHCOutOctets{job="$Job",instance="$IP"}[$__range]) * 8D查询:delta(ifHCInOctets{job="$Job",instance="$IP"}[$__range]) * 8- 表格转换:
merge series/tables和Organize fields by name
华为9306监控面板
变量设置
-
Job、IP变量和上面的msr3600一样 -
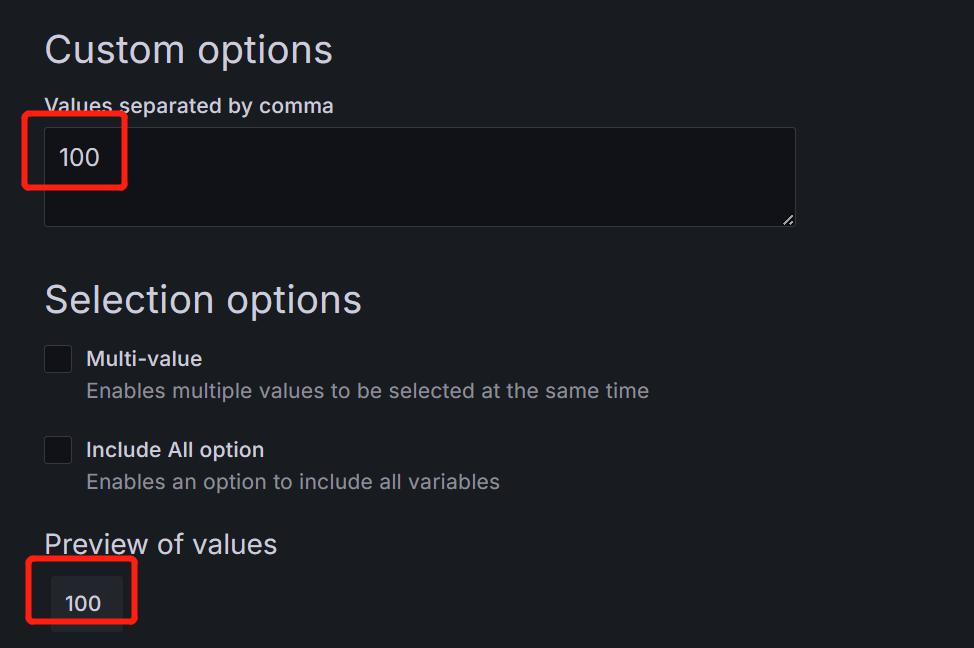
Hundred变量:Select variable type:Custom,接收功率告警阈值要除以100才是实际的数值
-
SN变量:

-
MFD_year变量:制造年份取序列号的第13位
-
MFD_month变量:取序列号的第14位
面板设置
Sysname面板:
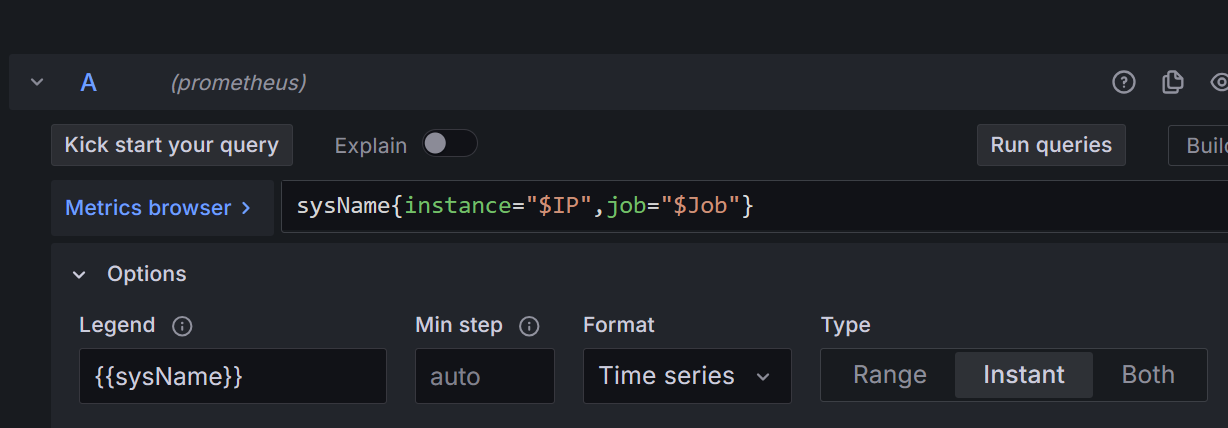
legend:{{sysName}}
formate:time series
text mode:name
Uptime面板:
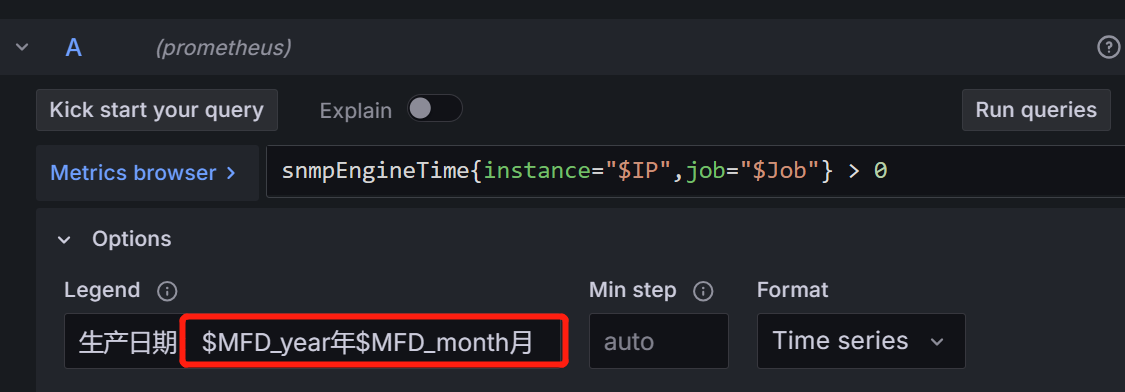
legend:生产日期:$MFD_year年$MFD_month月
formate:tiem series
text mode:value and name
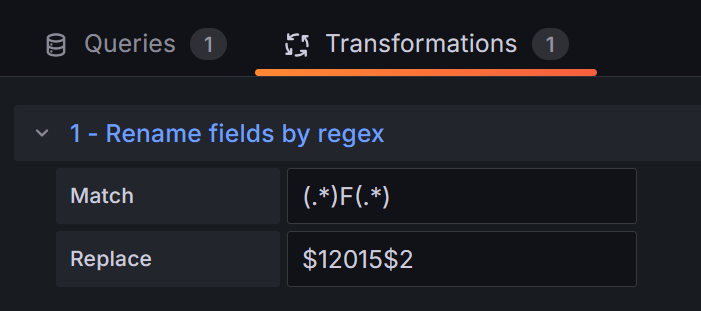
因为生成年份变量$MFD_year为16进制F,需要通过正则重命名Rename fields by regex
Match (.*)F(.*)
Replace $12015$2
- 电源状态面板

指标:hwEntityPwrState{hwEntityPwrSlot="40", hwEntityPwrSn="1", job="$Job"}
- 风扇状态面板
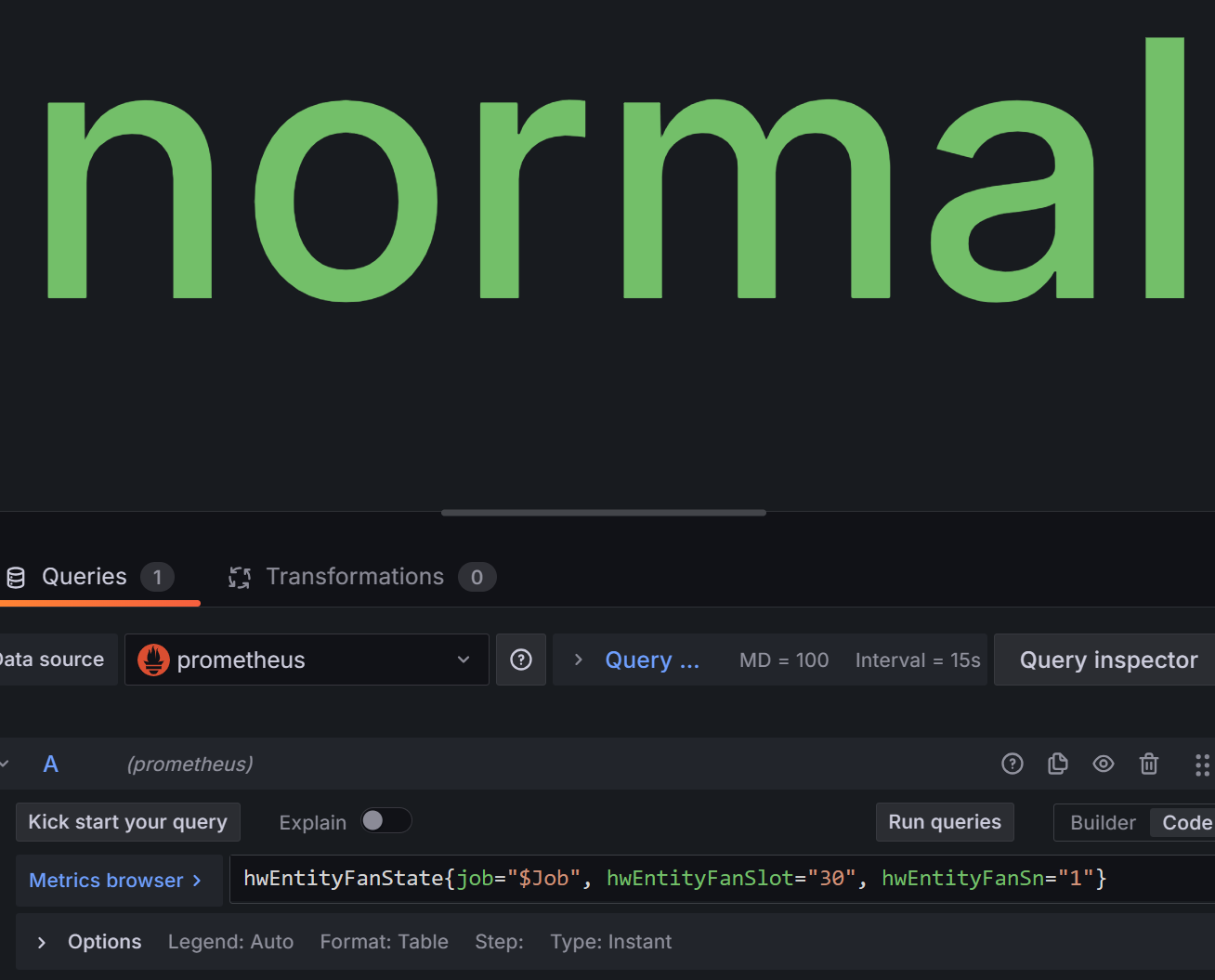
指标:hwEntityFanState{job="$Job", hwEntityFanSlot="30", hwEntityFanSn="1"}
- 已使用功率面板
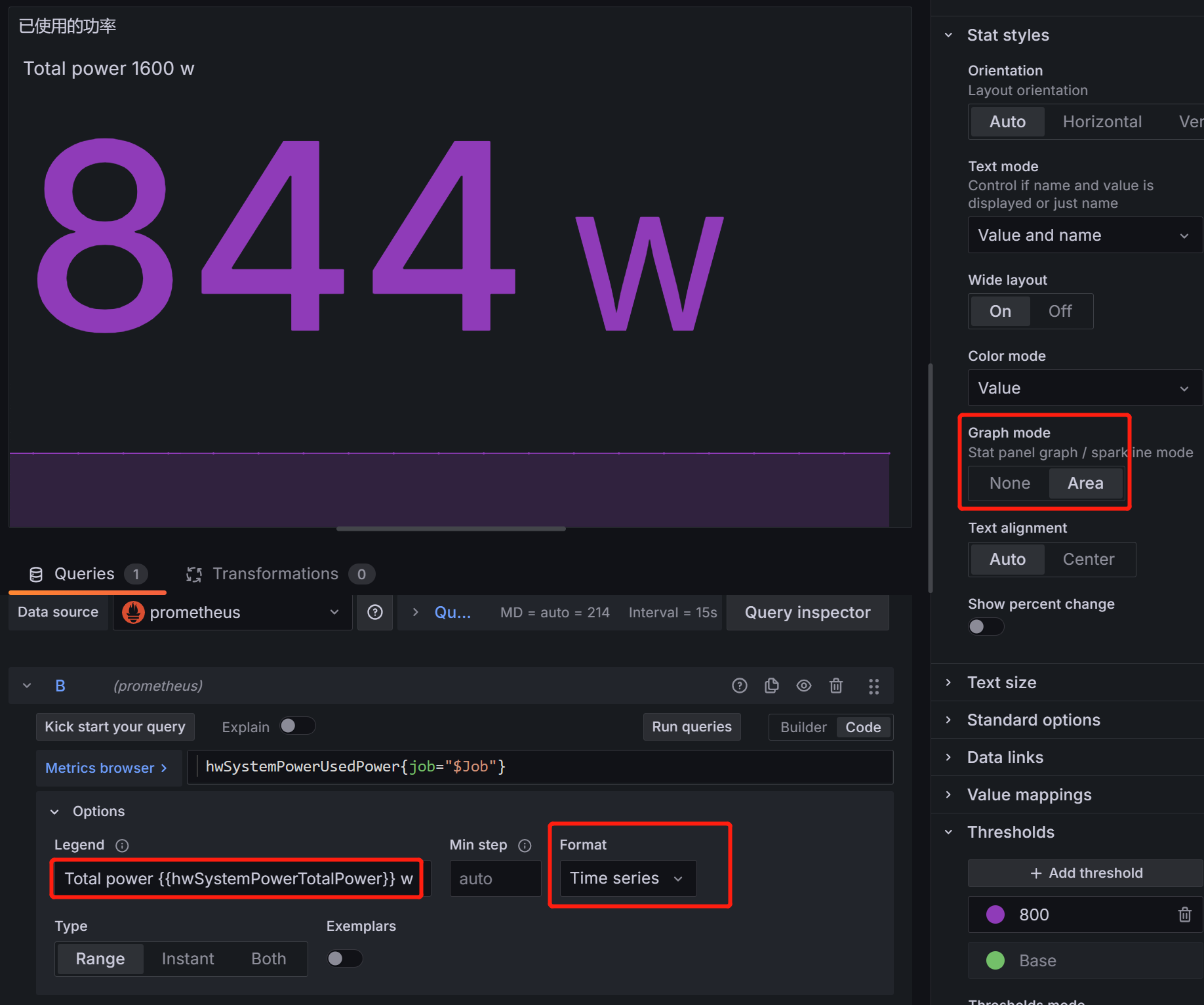
指标: hwSystemPowerUsedPower{job="$Job"}
总功率可以从 上面的指标的标签 {{hwSystemPowerTotalPower}} 获取
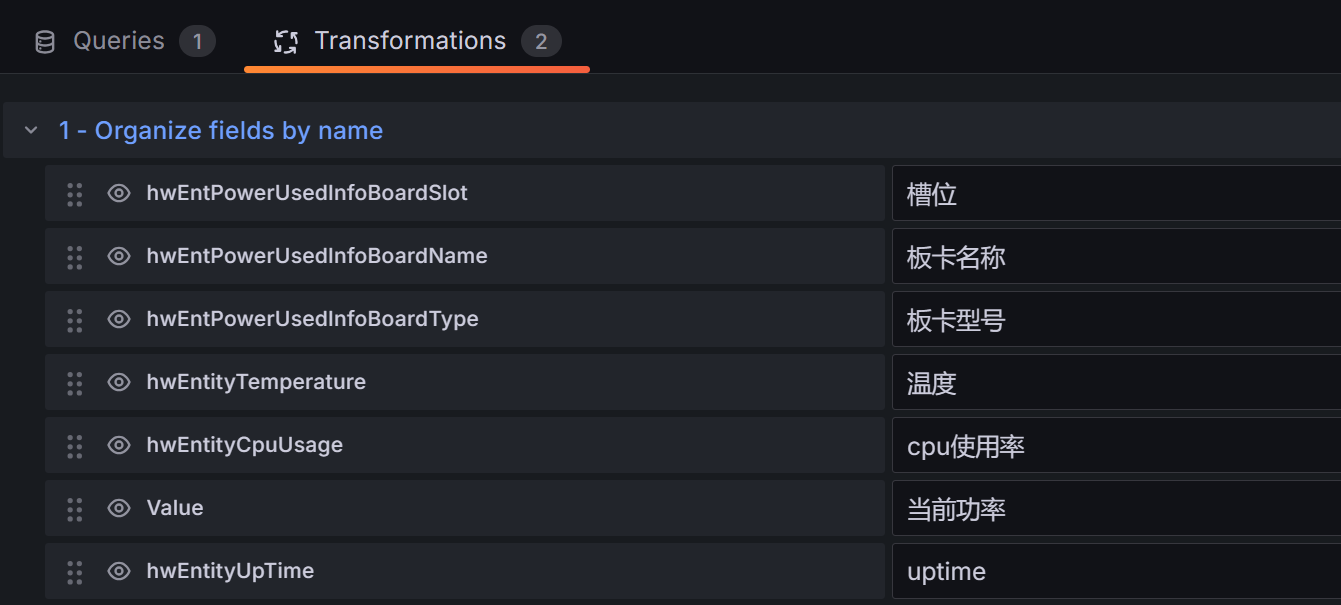
- 板卡信息表格面板
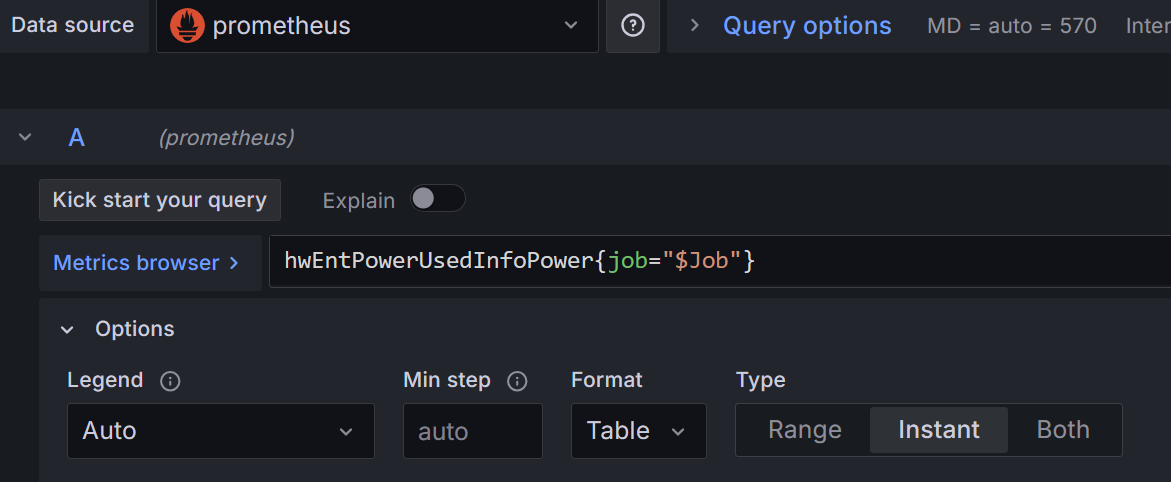
指标:hwEntPowerUsedInfoPower{job="$Job"}
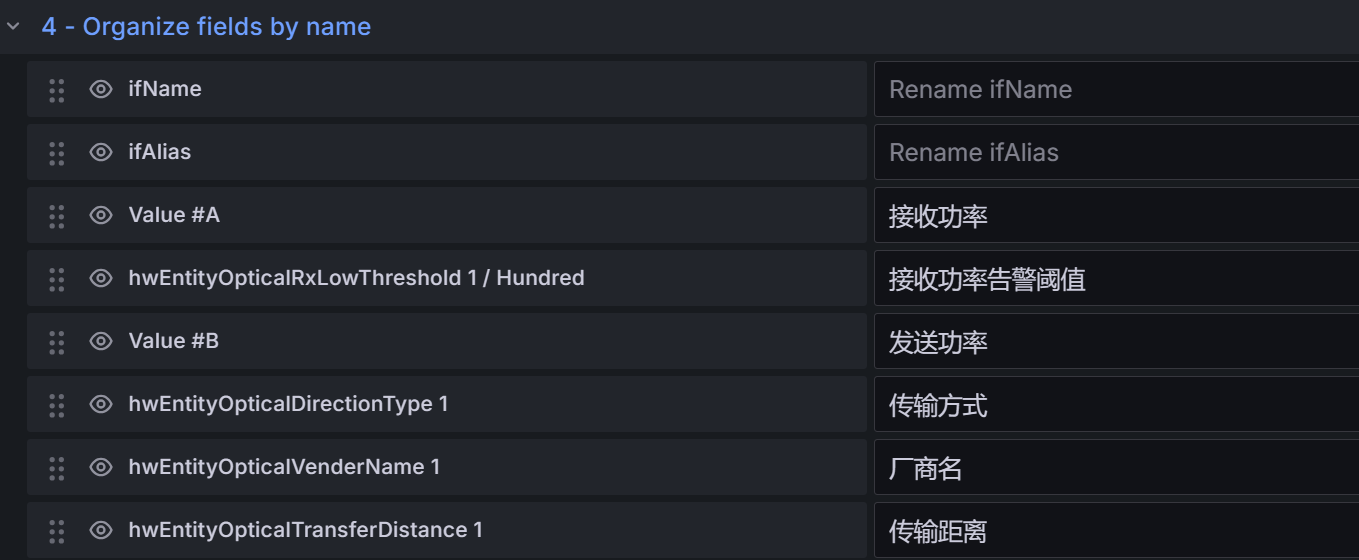
- 光模块信息面板
查询A:log10((hwEntityOpticalRxPower{job="$Job"} > 0 and hwEntityOpticalRxPower{job="$Job"} < 1000)/1000)*10
查询B:log10((hwEntityOpticalTxPower{job="$Job"} > 0 and hwEntityOpticalTxPower{job="$Job"} < 1000)/1000)*10
查询C:ifName{job="$Job"}

linux主机开放端口面板
linux节点相关配置
因为node_exporter原生没有linux主机侦听tcp、udp的相关指标,所以我们自能通过自己编写shell脚本获取linux侦听的监控然后按prometheus指标格式写入一个文件。
- 这个文件的路径(
/etc/node_exporter/)在/usr/lib/systemd/system/node_exporter.service配置文件中定义如下:
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
ExecStart=/etc/node_exporter/node_exporter \
# 定义文件路径
--collector.textfile.directory=/etc/node_exporter \
--web.listen-address=:9100 \
--web.max-requests=40 \
--collector.mountstats \
--collector.systemd \
--collector.ethtool \
--collector.tcpstat
ExecReload=/bin/kill -HUP
TimeoutStopSec=20s
Restart=always
[Install]
WantedBy=multi-user.target然后加载配置:systemctl daemon-reload、systemctl restart node_exporter.service
- 编写
shell脚本抓取tcp侦听端口:
vim collect_tcp_listening_ports.sh
#!/bin/bash
# 定义收集的指标的名称前缀,可根据需求修改
METRIC_PREFIX="tcp_listening_ports"
# 定义输出文件路径,这是textfile collector会读取的文件,可按需调整路径
OUTPUT_FILE="/etc/node_exporter/tcp_listening_ports.prom"
# 先清空之前的文件内容(如果有),确保每次都是最新准确的信息
> $OUTPUT_FILE
# 使用netstat命令获取TCP监听端口信息,并进行格式化输出
netstat -lnpt | grep -E 'tcp' | while read line; do
# 获取端口部分,提取第4个字段(以空格分隔)作为端口信息,去除最后的冒号和可能的IP地址部分
port=$(echo $line | awk '{print $4}' | sed 's/.*://')
# 获取进程名称部分,取最后一个字段(以空格分隔)作为进程名
process=$(echo $line | awk -F '/' '{print $NF}')
# 按照Prometheus的文本格式输出指标信息到文件
echo "${METRIC_PREFIX}{port=\"${port}\",process=\"${process}\",protocol=\"tcp\"} 1" >> $OUTPUT_FILE
done- 编写
shell脚本抓取udp开放端口:
vim collect_udp_listening_ports.sh
#!/bin/bash
# 定义收集的指标的名称前缀,可根据需求修改
METRIC_PREFIX="udp_listening_ports"
# 定义输出文件路径,这是textfile collector会读取的文件,可按需调整路径
OUTPUT_FILE="/etc/node_exporter/udp_listening_ports.prom"
# 先清空之前的文件内容(如果有),确保每次都是最新准确的信息
> $OUTPUT_FILE
# 使用netstat命令获取TCP监听端口信息,并进行格式化输出
netstat -lnpu | grep -E 'udp' | while read line; do
# 获取端口部分,提取第4个字段(以空格分隔)作为端口信息,去除最后的冒号和可能的IP地址部分
port=$(echo $line | awk '{print $4}' | sed 's/.*://')
# 获取进程名称部分,取最后一个字段(以空格分隔)作为进程名
process=$(echo $line | awk -F '/' '{print $NF}')
# 按照Prometheus的文本格式输出指标信息到文件
echo "${METRIC_PREFIX}{port=\"${port}\",process=\"${process}\",protocol=\"udp\"} 1" >> $OUTPUT_FILE
done- 编写
crontab定时任务:
crontab -l
# 每隔5分钟获取本机tcp,udp侦听端口;
*/5 * * * * bash -x /etc/node_exporter/collect_tcp_listening_ports.sh &> /tmp/collect_tcp.log
*/5 * * * * bash -x /etc/node_exporter/collect_udp_listening_ports.sh &> /tmp/collect_udp.logprometheus上测试相关指标
tcp_listening_ports{job="运维linux",instance="192.168.99.3:9100"}
udp_listening_ports{job="运维linux",instance="192.168.99.3:9100"}
grafana面板配置
效果如下:
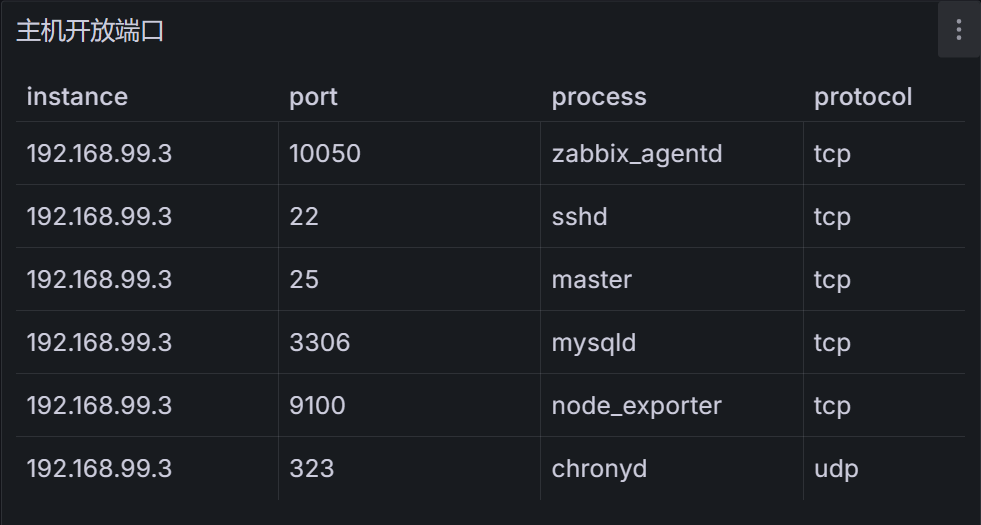
- 建立2个查询:
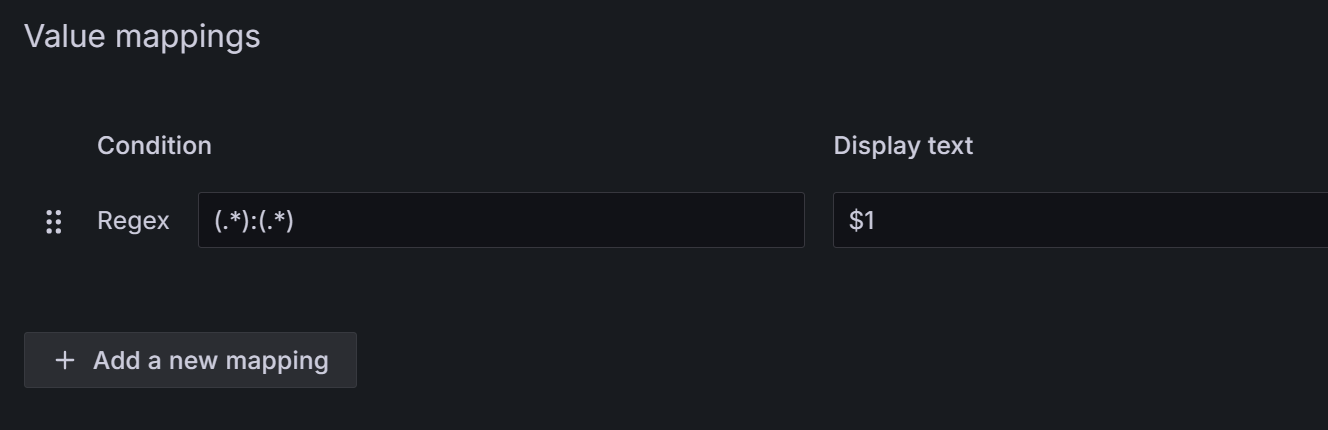
tcp_listening_ports{job="$Job",instance="$IP"} -0和udp_listening_ports{job="$Job",instance="$IP"} -0 - 表格转换:选择
Merge series/tables Organize fields by name:隐藏相关字段override配置:把instance字段的端口号去掉,value mappinigs配置如下:
留言