文件管理概述
- 谈到
linux文件管理,首先我们需要了解的是,我们要对文件做些什么事情 - 其实无非就是对一个文件进行创建、复制、移动、查看、编辑、压缩、查找、删除等等
- 如:当我们想修改系统的主机名称,是否应该知道文件在哪,才能去做对应的修改?
系统目录结构
- 几乎所有的计算机系统都是使用目录结构组织文件,具体来说就是在一个目录中存放子目录和文件,而在子目录中又会进一步存放子目录和文件,以此类推形成一个树状的文件结构
- 由于其结构很像一棵树的分支,所以该结构又被称为"目录树"
- windows:已多根的方式组织文件
C:\ D:\ - Linux:以单根的方式组织文件 /
- windows:已多根的方式组织文件
命令相关目录 /bin
- 存放命令相关的目录
- /bin 普通用户使用的命令
/bin/ls,/bin/date - /sbin 管理员使用的命令
/sbin/service
- /bin 普通用户使用的命令
用户家相关目录 /home
- 存放用户相关数据的家目录,比如windows不同的用户登录系统显示的桌面背景不一样
/home普通用户的家目录,默认为/home/username/root超级管理员root的家目录,普通用户无权操作
系统文件目录 /usr
存放系统相关文件的目录
/usr相当于 C:\Windows/usr/local软件安装的目录,相当于 C:\Program/usr/bin普通用户使用的命令/usr/sbin管理员使用的命令/usr/lib库文件 Glibc 32bit/usr/lib64库文件 Glibc 64bit
系统启动目录 /boot
- 存放系统启动时内核与grub引导菜单
- /boot存放的系统启动相关文件,如:
kernel,grub(引导装载程序)
- /boot存放的系统启动相关文件,如:
# ls /boot/
config-3.10.0-1160.el7.x86_64
efi
grub
grub2
initramfs-0-rescue-dc3f7d1b1750432091e5d1f06b278e75.img
initramfs-3.10.0-1160.el7.x86_64.img
symvers-3.10.0-1160.el7.x86_64.gz
System.map-3.10.0-1160.el7.x86_64
vmlinuz-0-rescue-dc3f7d1b1750432091e5d1f06b278e75
vmlinuz-3.10.0-1160.el7.x86_64配置文件目录 /etc
- /etc存放系统配置文件目录,后续所有服务的配置都在这个目录中
/etc/sysconfig/network-script/ifcfg-,网络配置文件/etc/hostname系统主机名配置文件
设备相关目录 /dev
- /dev存放设备文件的目录,比如硬盘,硬盘分区,光驱,等待
-/dev/null黑洞设备,只进不出,类似于垃圾回收站/dev/random生成随机数的设备/dev/zero能源源不断的产生数据(摇钱树),类似于取款机,随时随地取钱
# ls /dev/vda*
/dev/vda /dev/vda1 /dev/vda2可变的目录 /var
- /var,存放一些变化文件,比如/var/log/下的日志文件
- /var/tmp,进程产生的临时文件
- /tmp,系统临时目录(类似于公共厕所)
虚拟系统目录 /proc
- 虚拟的文件系统(如对应的进程停止则/proc下对应目录则会被删除)
- /proc,反映当前系统正在运行进程的实时状态,类似于汽车在运行过程中的仪表板,能够看到汽车的油耗、时速、转向灯、故障等待
文件路径定位
为什么要进行定位
- 你要在哪个目录下创建文件
- 你要将文件复制到什么地方?
- 你要删除的文件在什么地方?
如何对文件进行定位
- 比如:
/etc/hostname整个文件中包含文件名称以及文件所在的位置,我们称这个叫做路径,也就是说我们是通过路径对文件进行定位
访问路径方式-绝对路径
- 绝对路径:只要从/开始的路径,比如:
/var/log/message
访问路径方式-相对路径
- 相对路径:相对于当前目录来说,比如:
a.txt ./a.txt ../var/
路径切换命令 cd
cd # change the working directory
# cd 绝对路径 cd /etc/hostname
# cd 相对路径 cd test/abc cd . cd ..
# cd #若参数dir省略,则默认为使用者的shell变量HOME
# cd - #当前工作目录将被切换到环境变量OLDPWD所表示的目录,也就是前一个工作目录
# cd ~ #切换回当前用户的家目录,注意:root和普通用户是不同的(直接cd就可以了)
# cd . #代表当前目录,一般在拷贝、移动等情况下使用 cp /etc/hostname ./
# cd .. #切换回当前目录的上级目录文件管理命令
文件操作类命令
touch文件创建
touch命令的功能是创建空文件与修改时间戳。如果文件不存在,则会创建一个空内容的文本文件;
如果文件已经存在,则会对文件的Atime(访问时间)和Mtime(修改时间)进行修改。
touch # change file timestamps
# touch file #无则创建,有则修改时间
# touch file2 file3
# touch /home/od/file4 file5
# touch file{a,b,c} #{}集合,等价touch a b c
# touch file{1..10}
# touch file{a..z}
# touch -d "2023-05-18 15:44" File.cfg #修改指定文件的访问时间和修改时间mkdir目录创建
mkdir # make directories
# 选项:-v,--verbose -p,--parents(make parent directories as needed)
# mkdir dir1
# mkdir /home/ob/dir1 /home/ob/dir2
# mkdir -v /home/ob/{dir3,dir4}
# mkdir -pv /home/ob/dir5/dir6
# mkdri -pv /home/{ob/{diu,but},boy}
# mkdir -m 700 dir 创建目录并设置700权限tree显示目录结构
tree # list contents of directories in a tree-like format
# 选项:-L level(Max display depth of the directory tree)
# tree /home/ # 显示目录下的结构
# tree -d # 只显示目录的层级关系cp文件或目录复制
cp # copy files and directories
# 选项: -v,--verbose(explain what is being done)
#-r,--recursive(copy directories recursively)递归复制所有子文件
#-p,--preserve(preserve the specified attributes default:mode,ownership,timestamps)
# cp file /temp/file_copy
# cp name /tmp/name # 不修改名称
# cp file /tmp/ # 不修改名称
# cp -p file /tmp/file_p
# cp -r /etc/ /tmp/
# cp -rv /etc/hosts /etc/hostname /tmp # 拷贝多个文件至一个目录
# cp -rv /etc/{hosts,hosts.bak}
# cp -rv /etc/hosts{,org}
# -d 复制链接文件时,将目标文件也建立为链接文件
# -a 功能等价于pdr参数组合
# -u 在源文件的更改时间较目标文件更新时或是名称相互对应的目标文件并不存在时,才复制文件;mv文件移动命令
mv # move (rename) files
# mv file file1 # 原地移动算改名称
# mv file1 /tmp/ # 移动文件至tmp目录
# mv /tmp/file1 ./ # 移动tmp目录的文件至当前目录
# mv dir/ /tmp/ # 移动目录至/tmp目录
# touch file{1..3}
# mv file1 file2 file3 /opt/ # 移动多个文件至同一个目录
# mkdir dir{1..3}
# mv dir1/ dir2/ dir3/ /opt # 移动多个目录至同一个目录rm文件或目录删除
rm # remove files or directories
# 选项: -r,--recursive(remove directories and their contents recursively)
#-f,--force(ignore nonexistent files, never prompt)
#-v,--verbose(explain what is being done)
# rm file.txt # 删除文件,默认rm存在alias别名,rm -i 所以会提示是否删除文件
# rm -f file.txt # 删除文件,不提醒
# rm -r dir/ # 递归删除目录,会提示
# rm -rf dir/ # 递归删除目录,不提醒(慎用)
# mkdir /home/dir10
# touch /home/dir10/{file2,file3,.file4}
# rm -f /home/dir10/* # 不包括隐藏文件
# ls /home/dir10/ -a
# touch file{1..10}
# touch {1..10}.pdf
# rm -rf file*
# rm -rf *.pdf文件查看类命令
cat # concatenate files and print on the standard output
cat命令
# cp /etc/passwd ./pass
# cat pass # 正常查看文件方式
# cat -n pass # -n,--number(number all output lines)
# cat -A pass # -A,--show-all(equivalent to -vET)等价于vET参数组合
# -E,--show-ends(display $ at end of each line)每行结束处显示$符号
# -T,--show-tabs(display TAB characters as ^I)将TAB字符显示为^I符号
# -v,--show-nonprinting(use ^ and M- notation, except for LFD and TAB)使用^和M-引用,LFD和TAB除外
# tac pass # concatenate and print files in reverse
# cat /dev/null > anaconda-ks.cfg # 搭配空设备文件和输出重定向操作符,清空指定文件的内容
# cat >hello.txt << EOF # 持续写入文件内容,直到碰到EOF终止符结束并保存less-more命令
# less /etc/services # 使用光标上下翻动,空格进行翻页,q退出
# more /etc/services # 使用回车上下翻动,空格进行翻页,q退出less命令的功能是分页显示文件内容。more命令只能从前往后浏览文件内容,而less命令可以从后向前浏览(按向上箭)。
less -N /etc/zabbix/zabbix_server.conf 分页时显示行号
history | less 分页显示历史命令的输出结果
head-tail命令
head # output the first part of files
tail # output the last part of files
# head /etc/passwd # 查看头部内容,默认前十行
# head -n5 /etc/passwd # 查看头部5行,使用-n指定或者-5
# tail /etc/passwd
# tail -20 /etc/passwd
# tail -f /var/log/messages # 持续显示文件尾部最新内容
# -f,--follow(output appended data as the file grows)
# tailf /var/log/messages # 查看文件尾部的变化grep过滤数据
grep # print lines matching a patter / global search regular expression and print out the line
# grep "^root" /etc/passwd # 匹配以root开头的行
# grep "bash$" /etc/passwd # 匹配以bash结尾的行
# grep -v "ftp" /etc/passwd # 显示不包含匹配文本的所有行
# -v,--invert-match(Invert the sense of matching, to select non-matching lines)
# grep -i "ftp" /etc/passwd # 忽略关键词大小写
# -i,--ignore-case(Ignore case distinctions in both the PATTERN and the input files)
# grep -Ei "sync$|ftp" /etc/passwd # 匹配文件中包含syn结尾或ftp字符串-E启用扩展正则表达式 # 支持扩展正则表达式
# grep -n -A 2 "failed" /var/log/secure # 匹配文件中failed字符串,并打印它的下2行
# grep -n -B 2 "failed" /var/log/secure # 匹配文件中failed字符串,并打印它的上2行
# grep -n -C 2 "failed" /var/log/secure # 匹配文件中failed字符串,并打印它的上下2行
# -n 显示所有匹配行及其行号
# -c 显示包含某个关键词的行数量
# grep -c ^$ /etc/zabbix/zabbix_server.conf # 文件中空行的数量文件下载类命令
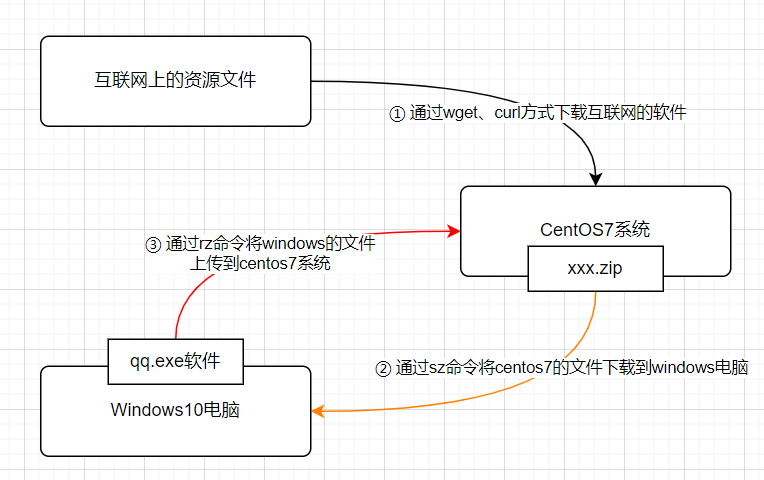
wget命令
wget # The non-interactive network downloader
centos7 系统最小化安装默认没有wget命令,需要进行安装
# 下载互联网上的文件至本地
# wget http://mirrors.aliyun.com/repo/Centos-7.repo
# 将阿里云的centos-7.repo下载到/etc/yum.repos.d/并改名为Centos-Base.repo -O参数指定
# wget -O /etc/yum.repos.d/Centos-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# -O,--output-document 设置本地文件名
# -b 启动后转入后台执行curl命令
仅查看这个url地址的文件的内容
curl # transfer a URL / commandline url
curl http://mirrors.aliyun.com/repo/Centos-7.repo
# 将阿里云的centos-7.repo下载到/etc/yum.repos.d/并改名为Centos-Base.repo -o参数指定
# curl -o /etc/yum.repos.d/Centos-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# -o,--output <file> 设置新的本地文件名
# -I 显示网站的响应头信息rz-sz命令
rz # file receive,sz # file send
# yum install lrzsz # 不安装软件则无法执行该命令
# rz # 只能上传文件,不支持上传文件夹,不支持大于4G文件上传,也不支持断点续传
# sz /path/file # 只能下载文件,不支持下载文件夹文件查找类命令
which命令
which # locate a command
# which ls # 查找ls命令的绝对路径
# type -a ls # 查看命令的绝对路径(包括别名)whereis命令
whereis # locate the binary, source, and manual page files for a command
# whereis ls # 查找命令的路径、帮助手册等
# whereis -b ls # 仅显示命令所在的路径字符处理类命令
sort命令
在有些情况下,需要对一个无序的文本文件进行数据的排序,这时就需要使用sort进行排序了
sort [OPTION]... [FILE]...
# -r:以相反的顺序排序
# -n:依据数值大小排序
# -t:设置排序时所用的栏位分隔符(默认空格)
# -k:设置需要排序的列号
# 首先创建一个文件,写入一些无序的内容
cat > file.txt <<EOF
b:3
c:2
a:4
e:5
d:1
f:11
EOF
# 使用sort对输出的内容进行排序
# sort file.txt
# 结果并不是按照数字排序,而是按字母排序
# 可以使用-t指定分隔符,使用-k指定需要排序的列
sort -t ":" -k2 file.txt
d:1
f:11 # 第二行为什么是11?不应该按照顺序排列?
c:2
b:3
a:4
e:5
# 按照排序的方式,只会看到第一个字符,11的第一个字符是1,按照字符来排序确实比2小
# 如果想要按照数字的方式进行排序,需要使用-n参数
# sort -t ":" -k2 -n file.txt
d:1
c:2
b:3
a:4
e:5
f:11uniq命令
如果文件中有多行完全相同的内容,当前是希望能删除重复的行,同时还可以统计出完全相同的行出现的总次数,那么就可以使用uniq命令解决这个问题(但是必须配合sort使用)
uniq [OPTION]... [INPUT [OUTPUT]]
# 选项:-c 计算重复的行
# 创建一个file.txt文件:
cat >>file.txt <<EOF
abc
123
abc
123
EOF
# uniq需要和sort一起使用,先使用sort排序,让重复内容连续在一起
# sort file.txt
# 使用uniq去除相邻重复的行
# sort file.txt | uniq
123
abc
# -c参数能统计出文件中每行内容重复的次数
# sort file.txt | uniq -c
2 123
2 abccut命令
cut命令的功能是按列提取文件内容。
cut OPTION... [FILE]...
# 选项:-d 设置分隔符
# -f 数字,显示指定列数的内容
# -c 以字符为单位进行分割
# echo "Im yujing, QQ is 67481157" >file.txt
# 过滤出文件里yujing以及67481157
# cut -d " " -f 2,5 file.txt
yujing, 67481157
# cut -d " " -f 2,5 file.txt | sed 's#,##g'
yujing 67481157
# sed 's#,##g' file.txt | awk -F " " '{print $2 " " $5}'
yujing 67481157
# awk -F "[, ]" '{print $2,$6}' file.txt
yujing 67481157
# awk -F "[, ]+" '{print $2,$5}' file.txt
yujing 67481157
# cut -c 1-4 /etc/passwd # 仅提取指定文件中的前4个字符wc命令
wc命令来自英文词组word count的缩写,其功能是统计文件的字节数、单词数、行数等信息。
wc [OPTION]... [FILE]...
# 选项:-l显示文件行数 -c显示文件字符 -w显示文件单词
# wc -l /etc/passwd # 统计文件有多少行
28 /etc/passwd
# wc -l /etc/services
11176 /etc/services
# 过滤出/etc/passwd以nologin结尾的内容,并统计有多少行
grep "nologin$" /etc/passwd | wc -l
# 扩展统计文件行号的方法
# grep -n ".*" /etc/services | tail -1
# cat -n /etc/services | tail -1
# awk '{print NR $0}' /etc/services | tail -1练习题
- 分析如下日志,统计每个域名被访问的次数
# cat web.log
http://www.123.com/index.html
http://www.123.com/1.html
http://post.123.com/index.html
http://mp3.123.com/index.html
http://www.123.com/3.html
http://post.123.com/3.html
# awk -F '/' '{print $3}' web.log | sort -rn | uniq -c
3 www.123.com
2 post.123.com
1 mp3.123.com
# cut -d / -f3 web.log | sort -rn | uniq -c
3 www.123.com
2 post.123.com
1 mp3.123.com文件扩展知识
文件属性
- 当我们使用
ls -l列出目录下所有文件时,通常会以长格式的方式显示,其实长格式显示就是我们windows下看到的文件详细信息,我们将其称为文件属性,整个文件的属性分为十列
ls -l latest-zh_CN.tar.gz
-rw-r--r-- 1 root root 25311313 1月 31 14:00 latest-zh_CN.tar.gz
-rw-r--r-- ①:第一个字符是文件类型,其他则是权限
1 ②:硬链接次数
root ③:文件属于哪个用户
root ④:文件属于哪个组
25311313 ⑤:文件大小
1月 31 14:00 ⑥⑦⑧:最新修改的时间与日期
latest-zh_CN.tar.gz ⑨:文件或目录名称文件类型
- 通常我们使用颜色或者后缀名称来区分文件类型,但很多时候不是很准确
- 我们可以通过
ls -l以长格式显示一个文件的属性,通过第一列的第一个字符来进一步的判断文件具体的类型,ll -d以长格式显示一个文件夹的属性 - 文件类型说明
| 文件类型字母 | 类型含义 |
|---|---|
| - | 普通文件(文本,二进制,压缩,图片,日志等 |
| d | 目录文件 |
| b | 设备文件(块设备)存储设备硬盘/dev/sda,/dev/sr0 |
| c | 设备文件(字符设备),终端/dev/tty1 |
| s | 套接字文件,进程与进程间的一种通信方式(socket插座) |
| l | 链接文件 |
- 但有些情况下,我们无法通过ls -l确定文件的类型,比如:一个文件,它可能是普通文件,也可能是压缩文件,或者是命令文件等,那么此时就需要使用
file来更加精确的判断这个文件的类型
# file /etc/hosts
/etc/hosts: ASCII text
# file /bin/ls
/bin/ls: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=aaf05615b6c91d3cbb076af81aeff531c5d7dfd9, stripped
# file /dev/vda
/dev/vda: block special
# file /dev/tty1
/dev/tty1: character special
# file /etc/grub2.cfg
/etc/grub2.cfg: symbolic link to `../boot/grub2/grub.cfg'
file -L /etc/grub2.cfg
/etc/grub2.cfg: ASCII text
# file /home
/home: directory
# file -b /home 不显示文件名
directorylinux文件扩展名不代表任何含义,仅为了我们人能更好的识别该文件是什么类型
连接文件
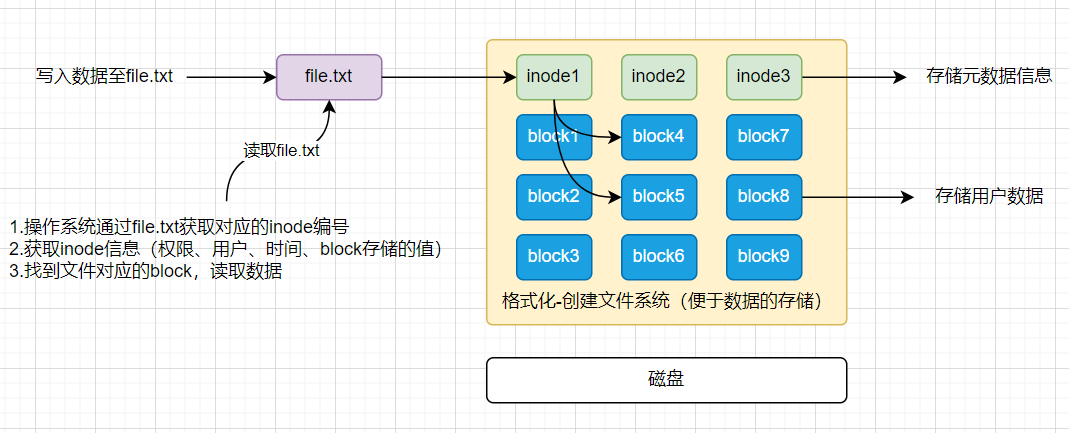
Inode与Block
- 文件有文件名与数据,在
Linux上被分成两个部分:数据data与文件元数据metadata- 数据
data block,数据是用来记录文件真实内容的地方,我们将其称为block - 元数据
metadata用来记录文件大小、创建时间、所有者等信息,我们称其为inode - 需要注意,
inode不包含文件名称,inode仅包含文件的元数据信息,具体来说有以下内容 - 文件的字节数
- 文件的
user id group id - 文件的读、写、执行权限
- 文件的时间戳
- 链接数,即有多少文件名指向这个
inode - 文件数据
block的位置
- 数据
- 每个
inode都是一个编号,操作系统通过inode来识别不同的文件- 对于系统来说,文件名只是
inode便于识别的别名,或者绰号。(便于我们人识别) - 表面上,用户是通过文件名打开的文件,实际上系统内部这个过程分为如下三步:
- 首先,系统找到这个文件名对应的
inode编号 - 此次,通过
inode编号,获取inode信息 - 最后,根据
inode信息,找到文件数据所在的block,读出数据
- 首先,系统找到这个文件名对应的
- 对于系统来说,文件名只是
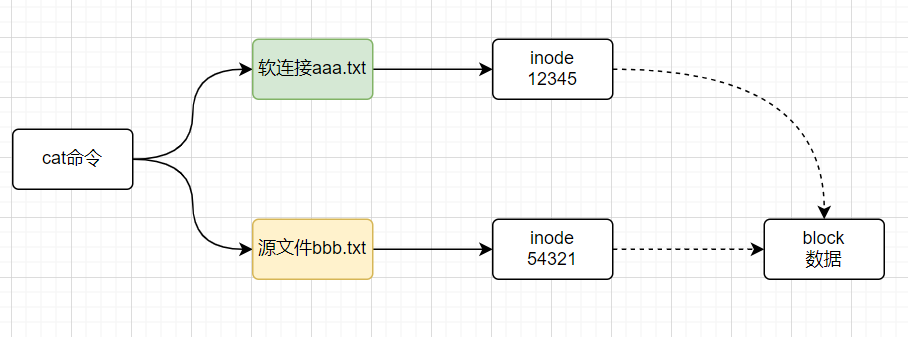
软连接
- 什么是软连接:软连接相当于
windows的快捷方式 - 软连接实现原理:
- 软连接文件会将
inode指向源文件的block - 当我们访问这个软连接文件时,其实访问的是源文件本身
- 软连接文件会将
- 软连接使用场景
- 软件升级
- 代码发布
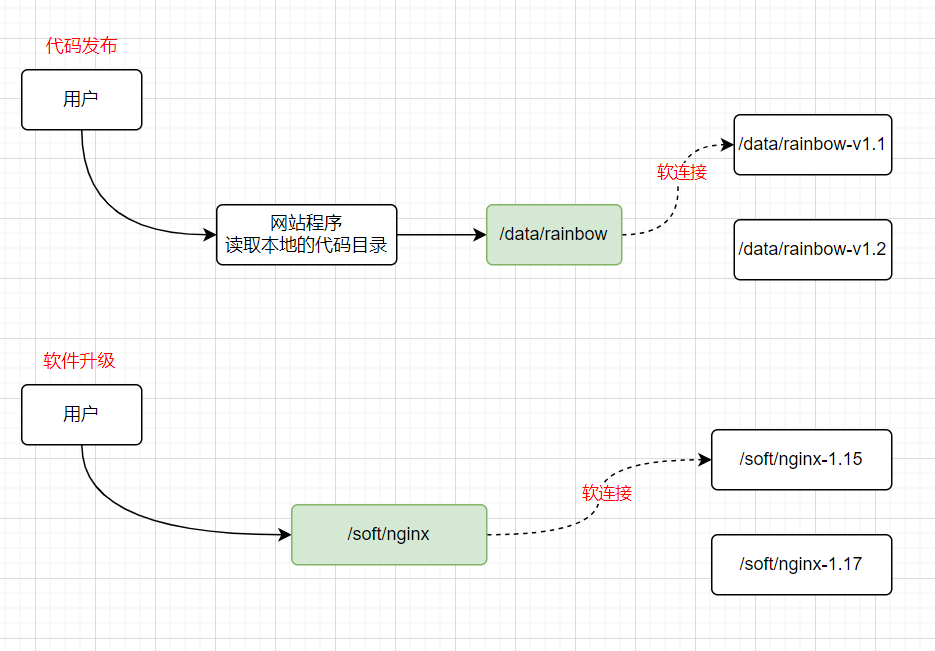
- 软连接场景实践
# 准备网站1.1版本代码
# mkdir /data/rainbow-v1.1 -p
# echo "123" > /data/rainbow-v1.1/index.html
# 创建软连接
# ln -s /data/rainbow-v1.1/ /data/rainbow
# ll /data/
lrwxrwxrwx 1 root root 19 3月 31 10:55 rainbow -> /data/rainbow-v1.1/
drwxr-xr-x 2 root root 24 3月 31 10:55 rainbow-v1.1
# 检查网站程序
# cat /data/rainbow/index.html
123
# 更新一个网站的程序代码
# mkdir /data/rainbow-v1.2
# echo "456" > /data/rainbow-v1.2/index.html
# 升级
# rm -f /data/rainbow && ln -s /data/rainbow-v1.2/ /data/rainbow
# cat /data/rainbow/index.html
456硬连接
- 硬连接类似于超市有多个门,无论从哪个门进入,看到的内容都是一样的,不会影响进入超市
- 回到系统中,我们对硬连接的解释:不同的文件名指向同一个
inode,简单的说就是指向同一个真实的数据源
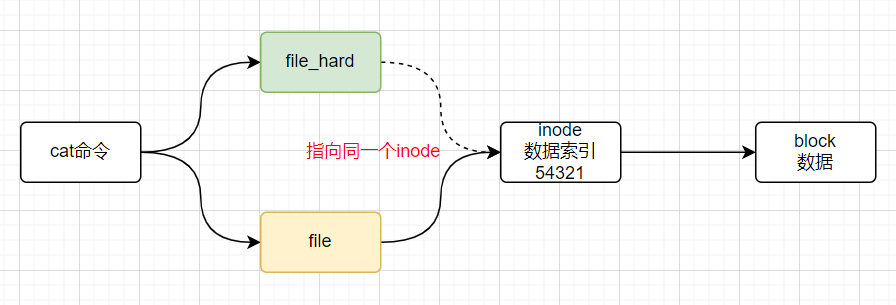
- 硬连接与软连接区别:
- 1.ln命令创建硬连接,ln -s命令创建软连接
- 2.目录不能创建硬连接,并且硬连接不可以跨越分区系统
- 3.软连接支持对目录创建,同时也支持跨越分区系统
- 4.硬连接文件与源文件的
inode相同,软连接文件与源文件inode不同 - 5.删除软连接文件,对源文件及硬连接文件无任何影响
- 6.删除文件的硬连接文件,对源文件及连接文件无任何影响
- 7.删除连接文件的源文件,对硬连接无影响,会导致软连接失效
- 8.删除源文件及其硬连接文件,整个文件会被真正的删除
文件时间
linux下文件有3个时间,分别是atime、mtime、ctime
| 简名 | 全名 | 中文名 | 含义 |
|---|---|---|---|
| atime | access time | 访问时间 | 文件中的数据最后被访问的时间 |
| mtime | modify time | 修改时间 | 文件内容被修改的最后时间 |
| ctime | change time | 变化时间 | 文件的元数据发生变化。比如权限,所有者等 |
环境准备
# echo "hello boy" >> new_file
# stat new_file
文件:"new_file"
大小:10 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:67224667 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2024-03-31 11:25:24.696156853 +0800
最近更改:2024-03-31 11:25:24.696156853 +0800
最近改动:2024-03-31 11:25:24.696156853 +0800
创建时间:-atime
# cat new_file
hello boy
# stat new_file
文件:"new_file"
大小:10 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:67224667 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2024-03-31 11:27:15.281641508 +0800 # 访问时间发生变化
最近更改:2024-03-31 11:25:24.696156853 +0800
最近改动:2024-03-31 11:25:24.696156853 +0800
创建时间:-mtime
# echo "hello word" >>new_file
[root@wordpress ~]# stat new_file
文件:"new_file"
大小:21 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:67224667 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2024-03-31 11:27:15.281641508 +0800
最近更改:2024-03-31 11:28:23.718960735 +0800 # 内容被修改后,mtime会变化
最近改动:2024-03-31 11:28:23.718960735 +0800 # 变化
创建时间:-
# ctime时间发生变化的原因是,内容变化了,inode所记录的大小也发生了变化,所以时间发生了变化ctime
# chown adm new_file
# stat new_file
文件:"new_file"
大小:21 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:67224667 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 3/ adm) Gid:( 0/ root)
最近访问:2024-03-31 11:27:15.281641508 +0800
最近更改:2024-03-31 11:28:23.718960735 +0800
最近改动:2024-03-31 11:31:54.699214193 +0800 # 只有ctime变化
创建时间:-
留言