监控项
什么是监控项
监控项主要用于采集主机的指标数据,一个监控项是一个独立的指标
比如,监控当前主机cpu的1分钟的平均负载,可以使用system.cpu.load[avg1]来获取主机指标数据
如果需要监控cpu1分钟、5分钟、15分钟这三个指标,则需要定义三个监控项
系统中提供了很多模板,模板中有很多的监控项,需要我们对其进行了解
- 有一些监控项没有用,是不是就需要删除
- 有一些监控项的触发器,设定的不合理,是需要人为的调整的。
创建一个监控项
要在zabbix管理页面创建一个监控项,请执行以下操作:
- 进入到:配置-->主机
- 在主机所在的行单击监控项
- 点击右上角的创建监控项
- 输入表单中监控项的参数
你也可以打开一个已经存在的监控项,点击克隆按钮,然后重命名保存。
监控项的值映射
什么是值映射
为了接收到的值能更人性化的显示,可以通过值映射方式,将数字与字符串之间进行关系绑定
举个例子,一个监控项有值0和1,通过值映射,以人可读的形式表示值
0-->不可用1-->可用
或者,一组备份关系的值映射可以是
F-->全量备份D-->差异备份I-->增量备份
值映射配置实践
定义值映射
- 进入到:管理-->一般
- 从左上角下拉列表中选择 值映射
- 点击创建值映射(或点击一个现有值映射的名称)
自定义监控项(入门)
监控主机当前登录主机的总登录用户数,如何实现
- 1.本机执行
shell命令提取需要监控对象的值 - 2.通过
zabbix_agent2.conf配置文件将其定义为一个监控项(为这个值设定一个监控项的名称) - 3.使用
zabbix_get测试是否能获取对应的值 - 4.登录前端
web界面,为对应的主机添加对应的监控项
第一步:获取监控项指标数据
who | wc -l
第二步:自定义一个监控项
添加命令到zabbix_agent2.conf
因配置文件定义了Include=/etc/zabbix/zabbix_agent2.d/*.conf,为了和其他配置区分,可以添加到新配置文件/etc/zabbix/zabbix_agent2.d/default.conf
格式:UserParameter=<key名称>,<shell command>
# login.user作为key,key在一台主机中必须是唯一的
vim /etc/zabbix/zabbix_agentd.d/default.conf
UserParameter=login.user,who | wc -l通过使用zabbix_agent2 -t命令测试此用户自定义参数的执行
zabbix_agent2 -t login.user
login.user [s|2]
# 重启zabbix_agent2,Agent会重载配置文件
systemctl restart zabbix-agent2第三步:使用zabbix_get取值
服务端安装zabbix_get工具包
yum install http://repo.zabbix.com/zabbix/5.0/rhel/8/x86_64/zabbix-get-5.0.40-1.el8.x86_64.rpm
获取agent端自定义的监控项,确认是否能获取到指标
命令:zabbix_get -s IP -p port -k keyname
zabbix_get -s blue.yn.cn -p 10050 -k login.user
1第四步:为主机添加监控项目
在被监控主机中添加使用key值为login.user的新监控项
监控项类型必须为zabbix客户端或者zabbix客户端(主动式)
- 第一步:点击配置-->主机-->监控项-->创建监控项
- 第二步:点击监测-->最新数据-->...
自定义监控项(单位)
监控当前主机的内存使用百分比,以及剩余百分比;
- 1.本机执行
shell命令提取需要监控对象的值- 内存的使用百分比:
free -m | awk '/^Mem/ {print $3/$2*100}' - 内存的剩余百分比:
free -m | awk '/^Mem/ {print $NF/$2*100}'
- 内存的使用百分比:
- 2.通过
zabbix_agent2将其定义为一个监控项 - 3.使用
zabbix_get测试能否获取对应的值 - 4.登录前端
web,为对应的主机添加对应的监控项
第一步:获取项目指标数据
获取内存已用百分比(取出内存的以用空间/总内存空间=已占用空间百分比)
free -m | awk '/^Mem/ {print $3/$2*100}'
8.41391获取内存剩余百分比(取出内存的可用空间/总内存大小=实际可用的百分比)
free -m | awk '/^Mem/ {print $NF/$2*100}'
86.4373第二步:创建监控项
cat /etc/zabbix/zabbix_agent2.d/default.conf
UserParameter=Mem.Used,free | awk '/^Mem/ {print $3/$2*100}'
UserParameter=Mem.Ava,free | awk '/^Mem/ {print $NF/$2*100}'重启zabbix-agent2
systemctl restart zabbix-agent2
第三步:检查监控项
zabbix_get -s blue.yn.cn -k Mem.Used
8.38634
zabbix_get -s blue.yn.cn -k Mem.Ava
86.4643然后在web添加监控项,信息类型选浮点数,单位填 %
自定义监控项(传参)
传参是为了让key接受对应的参数,从而完成多个监控项创建的一种方式,
UserParameter=key[*],command
简单传参示例
cat /etc/zabbix/zabbix_agent2.d/default.conf
UserParameter=ping[*],echo $1
systemctl restart zabbix-agent2.service
zabbix_get -s blue.yn.cn -k ping[hello]
hello复杂传参示例
vim /etc/zabbix/zabbix_agent2.d/default.conf
UserParameter=mariadb.ping[*],mysqladmin -u$1 -p$2 ping | grep -c alive这个用户自定义参数可以用来监控mysql数据库的状态。可以传入用户名和密码:
zabbix_get -s blue.yn.cn -k mariadb.ping[root,xxx]
1监控TCP状态实践
通过传参方式,创建监控项获取TCP状态指标数据
cat /etc/zabbix/zabbix_agent2.d/default.conf
UserParameter=tcp.status[*],netstat -ant | grep -c $1重启zabbix-agent2,加载配置文件
systemctl restart zabbix-agent2.service
服务端使用zabbix_get测试
zabbix_get -s blue.yn.cn -k tcp.status[LISTEN]
10
zabbix_get -s blue.yn.cn -k tcp.status[ESTABLISHED]
3
zabbix_get -s blue.yn.cn -k tcp.status[TIME_WAIT]
42登录web前端,为主机添加监控项,或导入监控模板
趋势|历史数据计算公式
100台主机,每个主机约100个监控项,每个监控项每间隔60s获取一次数据,每个监控项大小约90byte
历史数据:
days*(items/refresh rate)*24*3600*90bytes
90*(10000/60)*24*3600*90=116,640,000,000bytes/1024/1024/1024
约等于108GB
趋势
days*(items/3600)*24*3600*90bytes
365*(10000/3660)*24*3600*90=7,884,000,000bytes/1024/1024/1024
约等于7GB
事件
days*events*24*3600*170bytes
365*1*24*3600*170=,361,120,000bytes/1024/1024/1024
约等于5GB
合计:120GB
触发器
什么是触发器
当监控项的值发生变化后,对应的值不符合预期,则应该通过触发器来通知管理人员介入;
比如:监控tcp的80端口,如果存活则符合预期,如果不存活则不符合预期,应该通过触发器通知
比如:监控主机内存状态,当使用率达到80%,则应该通过触发器通知管理人员
比如:监控主机的cpu使用率,当持续5分钟,高于80%,则应该通过触发器通知管理人员
触发器严重性
触发器严重性定义了触发器的重要程度,zabbix支持下列触发器的严重程度
| 严重性 | 定义 | 颜色 |
|---|---|---|
| 未分类 | 未知严重性 | 灰色 |
| 信息 | 提示 | 浅蓝色 |
| 警告 | 警告 | 黄色 |
| 一般严重 | 一般问题 | 橙色 |
| 严重 | 发生重要的事情 | 浅红色 |
| 灾难 | 灾难,财务损失等 | 红色 |
- 通过不同的颜色代表不同的严重程度
- 报警音频,不同的音频代表不同的严重程度
- 用户媒介,不同的用户媒介(通知渠道)代表不同的严重程度。例如:
sms-高严重性,email-其他 - 通过触发器执行对应的条件动作
配置一个触发器
配置一个触发器,监控主机tcp80端口是否存活,如果不存活则通知,存活则不处理
- 菜单:配置-->主机
- 点击主机一行的触发器
- 点击右上角的创建触发器(或则点击触发器名称去修改一个已存在的触发器)
- 在窗口输入触发器的参数
触发器表达式
| 函数名称 | 作用 |
|---|---|
| avg() | 监控项的平均值: avg(#5)-->最新5个值的平均值 avg(1h)-->最近一小时的平均值 avg(1h,1d)-->一天前的一小时内的平均值 |
| min() | 监控项的最小值 示例:cpu使用率最近5分钟的最小值大于5:system.cpu.load.min(5m)>5 示例:cpu最近5次最小的值大于2:system.cpu.load.min(#5)>2 |
| max() | 监控项的最大值 max(#5)-->最新5个值的最大值 max(1h)-->最近一小时的最大值 |
| last() | 注意last的#num参数和其他函数中的作用不一样 last()通常等同于last(#1) last(#5)-->第五个最新值(不是五个最新值) last(#2)返回第二个最新值 |
| diff() | 比对上一次文件的内容 |
| nodate() | 监控一段时间内是否返回数据:时间不少于30秒,因为timer处理器每30秒调用一次 返回1-->指定评估期内没有接收到数据 返回0-->其他 |
触发器示例场景1
www.zabbix.com的处理器负载过高
www.zabbix.com:system.cpu.load[all,avg1].last()} > 5
它指定了服务器是www.zabbix.com,监控项的键值是system.cpu.load[all,avg1]
通过使用函数last()获取最新的值。最后,>5意味着当www.zabbix.com最新获取的处理器负载值大于5时触发器就会处于异常状态
触发器示例场景2
当前处理器负载大于5或者最近10分钟内最小值大于2,表达式为true
{www.zabbix.com:system.cpu.load[all,avg1].last()} > 5 or
{www.zabbix.com:system.cpu.load[all.avg1].min(10m)} > 2触发器示例场景3
监控/etc/passwd文件是否被修改,当文件/etc/passwd的checksum值与最近的值不同时,表达式为true
www.zabbix.com:vfs.file.cksum[/etc/passwd].diff()} = 1
触发器示例场景4
最近5分钟,如果eth0上接收字节数大于100kb时,则表达式为真
{www.zabbix.com:net.if.in[eth0,bytes].min(5m)} > 100k
触发器示例场景5
当主机www.zabbix.com在30分钟内超过5次的不可达(值为0状态),则表达式为真
www.zabbix.com:icmpping.count(30m,0)} > 5
触发器示例场景6
比较今天的平均负载和昨天同一时间的平均负载(使用第二个时间偏移参数)
{server:system.cpu.load.avg(1h)}/{server:system.cpu.load.avg(1h,1d)} > 2
如果最近一小时平均负载超过昨天相同小时负载的2倍,触发器将触发
触发器示例场景7
如果表达式中至少有两个触发器大于5,触发器将触发
({server1:system.cpu.load[all,avg1].last()} > 5) + ({server2:system.cpu.load[all,avg1].last()} > 5) + ({server3:system.cpu.load[all,avg1].last()} > 5) >= 2
触发器示例场景8
使用nodata()函数:如果在180秒内没有接收到数据,则触发器变为异常状态
{www.zabbix.com:tick.nodata(3m)} = 1
触发器滞后
有时我们需要触发器处于OK和问题状态之间的区间,而不是一个简单阈值报警就完事了
例如,我们希望定义一个触发器,当机房温度超过20°时,触发器会出现异常,我们希望它保持这种状态,直到温度下降到15°以下,为了做到这一点,我们首先定义问题事件的触发器表达式,然后再定义事件成功迭代中选择恢复表达式并为OK事件输入恢复表达式
滞后示例1
机房温度过高
问题表达式:当机房温度大于20°
{server:temp.last()}>=20
恢复表达式:当机房温度小于或等于15°
{server:temp.last()}<=15
滞后示例2
磁盘剩余空间过低
问题表达式:在最近5分钟内最大的值小于10G
{server.vfs.fs.size[/,free].max(5m)}<10G
恢复表达式:在最近10分钟内最小的值大于40G
{server.vfs.fs.size[/,free].min(10m)}>40G
自定义触发器场景
配置单条件触发器
- 自定义单条件触发器:设置内存低于30%进行告警,点击对应主机-->创建触发器
- 1.获取内存还剩余的百分比:
- 剩余30%可用,则需要告警通知
- 剩余50%可用,就算恢复
- 编辑触发器表达式
- 问题表达式:
web:Mem_pre.last()}<30 - 恢复表达式:
web:Mem_pre.last()}>50
- 问题表达式:
- 使用
dd if=/dev/zero of=/dev/null bs=500M count=1024压低内存
配置多条件触发器
- 自定义多条件触发器:设置内存低于30%并且
swap使用大于1%进行告警 - 增加
swap的监控UserParameter=Swap_pre,free -m | awk '/^Swap/{print $3*100/$2}' - 编辑触发器表达式
- 问题表达式:
{web:Mem_pre.last()}<30 and {web:Swap_pre.last()}>1 - 恢复表达式:
{web:Mem_pre.last()>30
- 问题表达式:
- 使用命令压测
dd if=/dev/zero of=/dev/null bs=300M count=1024只满足内存低于30%,所以不会告警dd if=/dev/zero of=/dev/null bs=800M count=1024内存低于30%,并且swap使用超过1%
触发器依赖关系
什么是触发器依赖
有时候一台主机的可用性依赖于另一台主机,如果一台路由器宕机,则路由器后端的服务器将变得不可用。如果这两者都设置了触发器,你可能会收到关于两个主机宕机的通知,然而只有路由器是真正故障的。
这就是主机之间的依赖关系,设置依赖关系的通知会被抑制,而只发送根本问题的通知
触发器依赖关系示例
例如:主机位于路由器2后面,路由器2在路由器1后面
zabbix --> 路由器1 --> 路由器2 --> 主机
如果路由器1宕机,显然主机和路由器2也不可达,然后我们不想收到主机、路由器1和路由器2都宕机的3条通知。因此,在这种情况下我们定义了两个依赖关系:
“主机宕机” 触发器依赖于 “路由器2宕机” 触发器
“路由器2宕机” 触发器依赖于 “路由器1宕机” 触发器触发器依赖场景配置
依赖场景环境说明
- 容县中学S5120交换机作为校园局域网汇聚交换机,容县中学科文昌楼2楼楼层交换机作为楼层接入交换机
- 1.当容县中学科文昌楼2楼楼层交换机
ping检测不存活,需要检查容县中学S5120交换机是否存活 - 2.如果容县中学S5120交换机存活,则触发容县中学科文昌楼2楼楼层交换机的不存活警告
- 3.如果容县中学S5120交换机不存活,则仅触发容县中学S5120交换机不存活的警告,而不触发容县中学科文昌楼2楼楼层交换机的不存活警告
- 1.当容县中学科文昌楼2楼楼层交换机
定义触发器表达式
汇聚交换机:定义监控项,配置触发器
楼层交换机:定义监控项,配置触发器
模拟故障
模拟汇聚交换机、楼层交换机同时故障,会同时收到两个告警,显然不符合预期效果
配置触发器依赖关系
在楼层交换机上对应的触发器配置依赖关系,依赖汇聚交换机对应的触发器
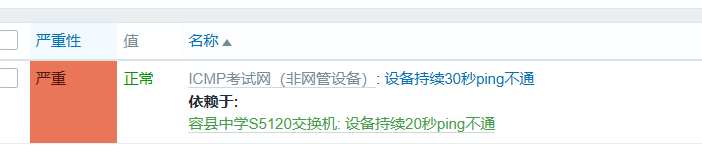
再次模拟故障
同时故障时,此时只有汇聚交换机主机会警告;汇聚交换机存活,楼层交换机故障,此时只有楼层交换机主机会警告;
通知(告警)
什么是事件告警
首先,我们不希望一直盯着触发器或事件列表。最好是在发生比较严重的事情(如问题)时能够接收到通知。并且,当发生问题时,我们希望所有相关人员都能收到通知
也就是说,当配置的监控项超过触发器设定的阈值则触发动作,这个动作可以是(发送消息|执行命令)
如何实现事件通知
为了能够实现发送和接收zabbix的通知,则必须:
- 定义媒介:(发件人)
- 什么类型,
qq邮件、微信、短信等
- 什么类型,
- 配置动作:使用媒介向-->用户发送信息(收件人)/向已定义的媒介发送信息
动作由触发器条件和操作组成。总的来说,当条件满足时,则执行相应的操作
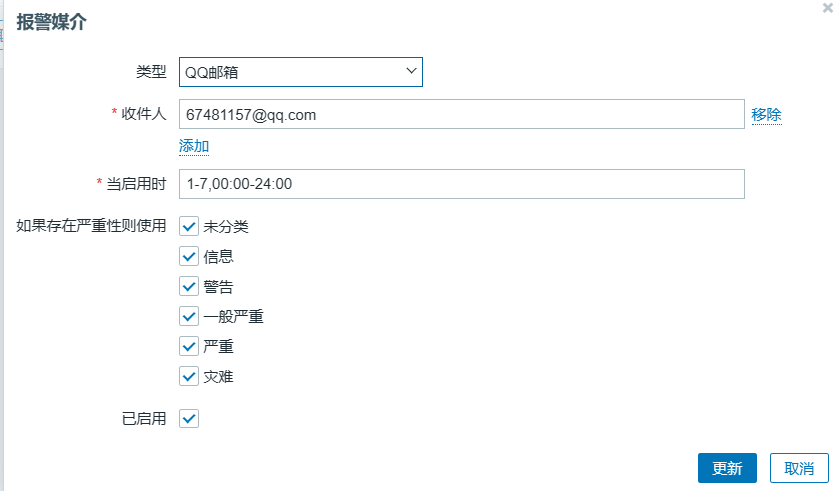
配置邮件通知方式
定义媒介(发件人)
单击管理-->报警媒介类型,设定发送告警消息的媒介类型为电子邮件
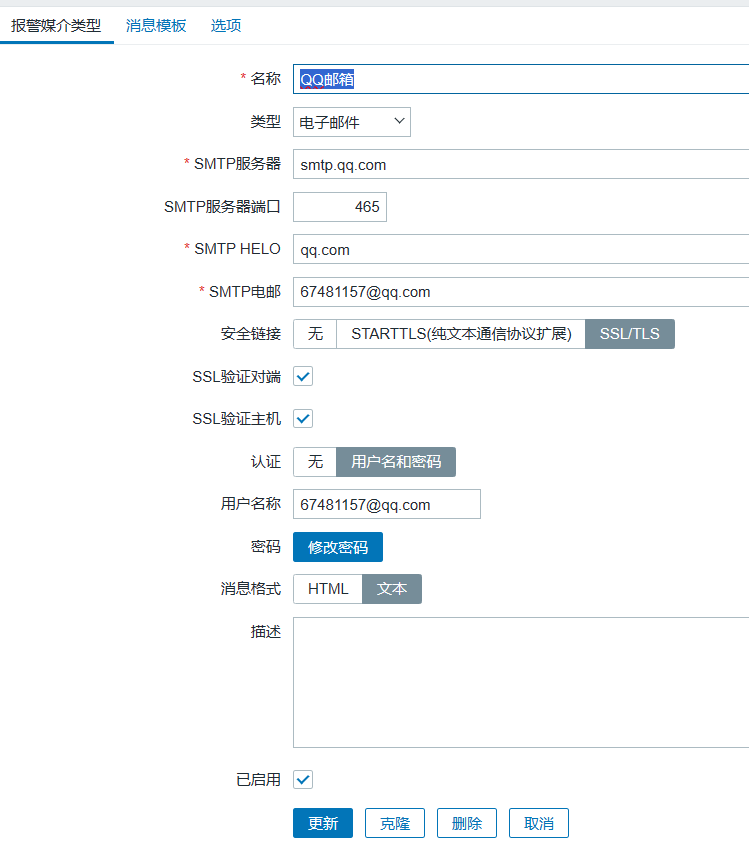
消息模板可修改如下:
# 告警
告警主机:{HOST.NAME1}
告警服务:{ITEM.NAME1}
告警Key1:{ITEM.KEY1}:{ITEM:VALUE1}
告警Key2:{ITEM.KEY2}:{ITEM:VALUE2}
严重级别:{TRIGGER.SEVERITY}
# 恢复
恢复主机:{HOST.NAME1}
恢复服务:{ITEM.NAME1}
恢复Key1:{ITEM.KEY1}:{ITEM:VALUE1}
恢复Key2:{ITEM.KEY2}:{ITEM:VALUE2}配置动作(发送给谁)
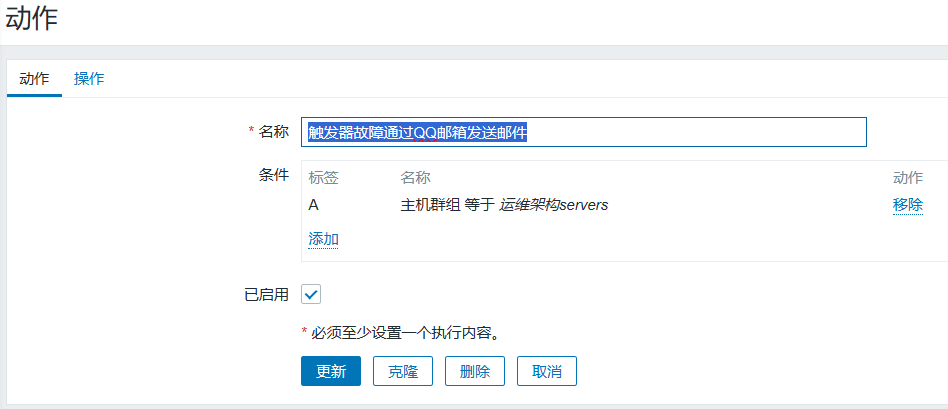
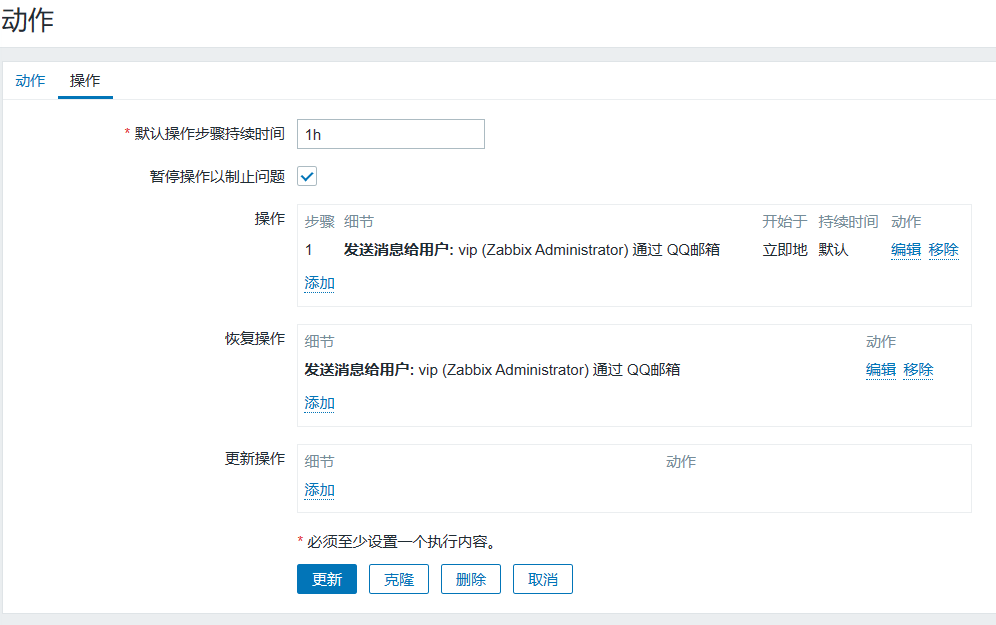
单击配置-->动作-->创建动作,以及对应的操作
配置媒介收件人
管理-->用户-->报警媒介-->选择类型-->收件人(收件人邮箱)
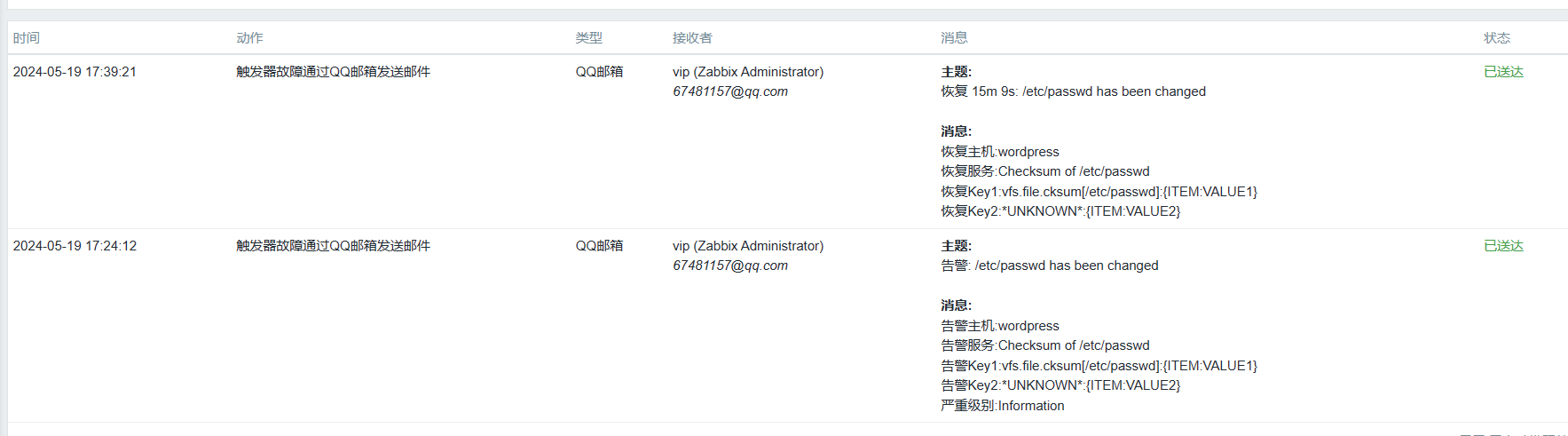
测试邮件告警
报表-->动作日志-->可以查看报警内容
基于企业微信通知方式
编写脚本
脚本文件:
#!/usr/bin/python3.6
#-*- coding: utf-8 -*-
import requests
import sys
import os
import json
import logging
logging.basicConfig(level = logging.DEBUG, format = '%(asctime)s, %(filename)s, %(levelname)s, %(message)s',
datefmt = '%a, %d %b %Y %H:%M:%S',
filename = os.path.join('/tmp','weixin.log'),
filemode = 'a')
corpid='xxx'
appsecret='xxx'
agentid=xxx
#获取accesstoken
token_url='https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=' + corpid + '&corpsecret=' + appsecret
req=requests.get(token_url)
accesstoken=req.json()['access_token']
#发送消息
msgsend_url='https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=' + accesstoken
touser=sys.argv[1]
subject=sys.argv[2]
#toparty='3|4|5|6'
message=sys.argv[2] + "\n\n" +sys.argv[3]
params={
"touser": touser,
# "toparty": toparty,
"msgtype": "text",
"agentid": agentid,
"text": {
"content": message
},
"safe":0
}
req=requests.post(msgsend_url, data=json.dumps(params))把编写好脚本上传到/usr/lib/zabbix/alertscripts目录,并赋予对应的执行权限
chmod +x weixin.py
修改脚本内容:
corpid='企业ID'
appsecret='企业微信自建应用的secret'
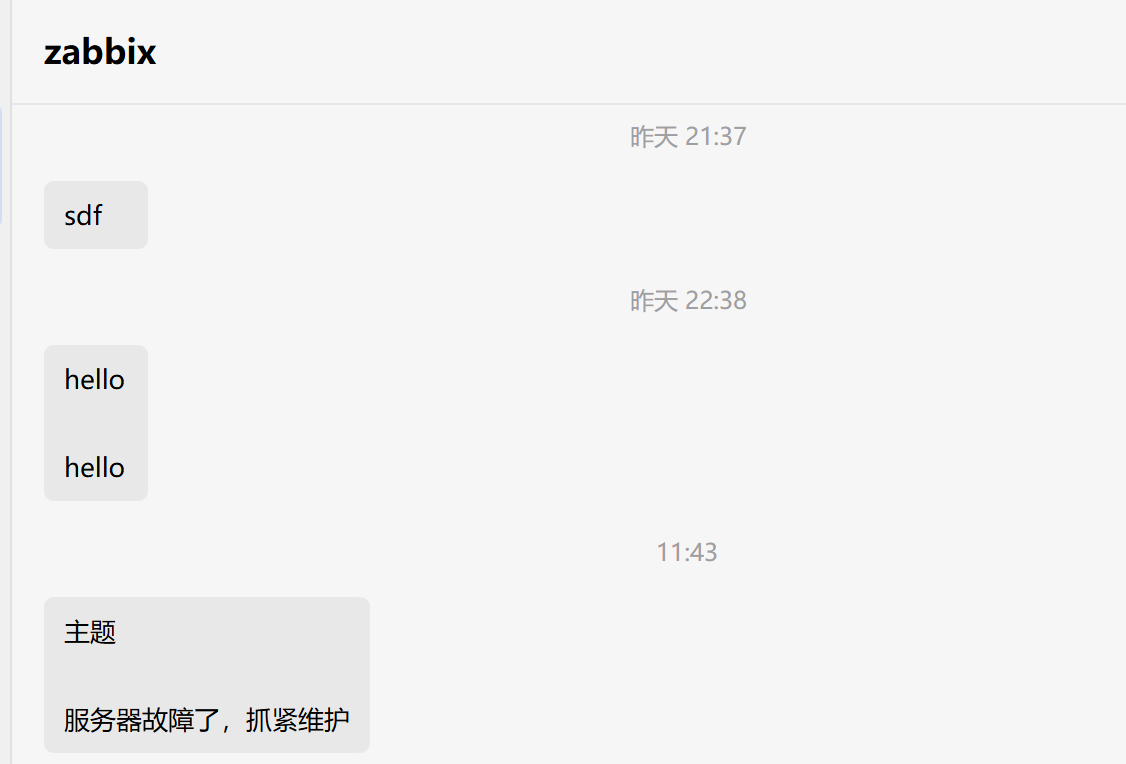
agentid=自建应用的agentid执行脚本,参数1:用户账号YuJing,参数2:消息主题,参数3:消息内容
python3 weixin.py YuJing 主题 "服务器故障了,抓紧维护"
#切记一定要删除,否则会导致权限问题
rm -f /tmp/weixin.log还有文件格式问题
- 究其原因就是因为在
windows下编辑的文件,上传到linux用vim编辑后,文件的格式发生了变化。
直接vim weixin.py,使用set ff查一下文件格式,如果格式是dos,就直接把格式改成unix就可以了,使用set ff=unix回车确认修改格式为fileformat=unix
执行结果如下:
但是,实际调试过程中会出现如下错误:
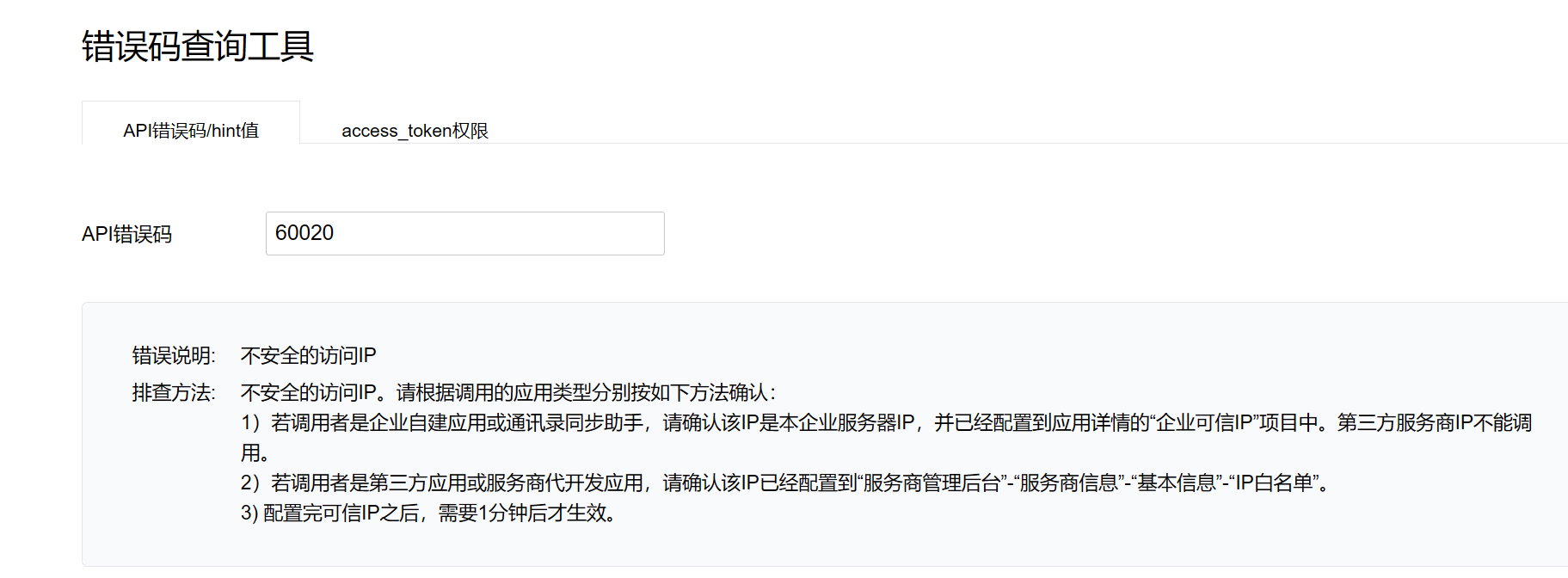
需把zabbix所在服务器的公网ip地址配置自建应用zabbx的企业可信ip(仅所配ip可通过接口获取企业数据)
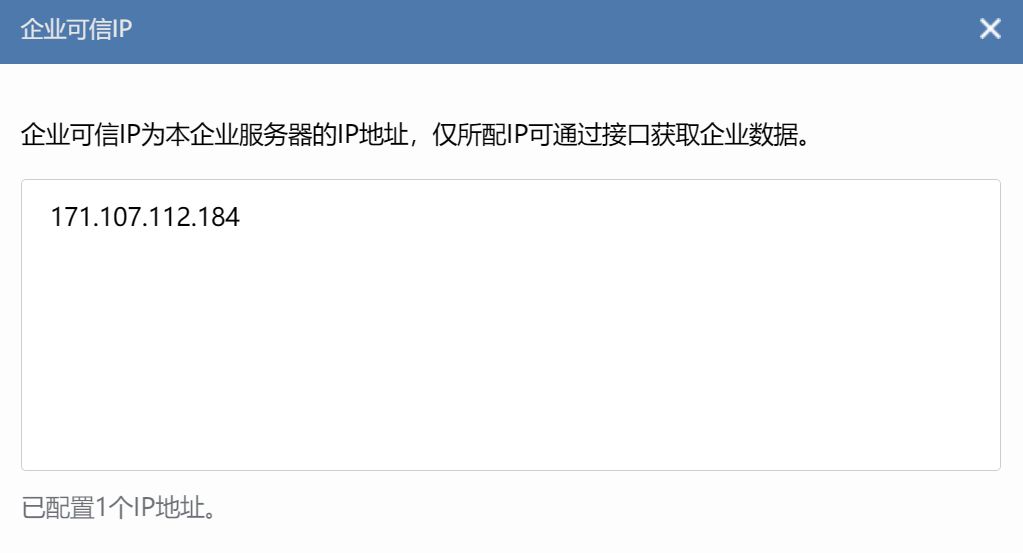
加入企业可信ip之前需设置可信域名如下:
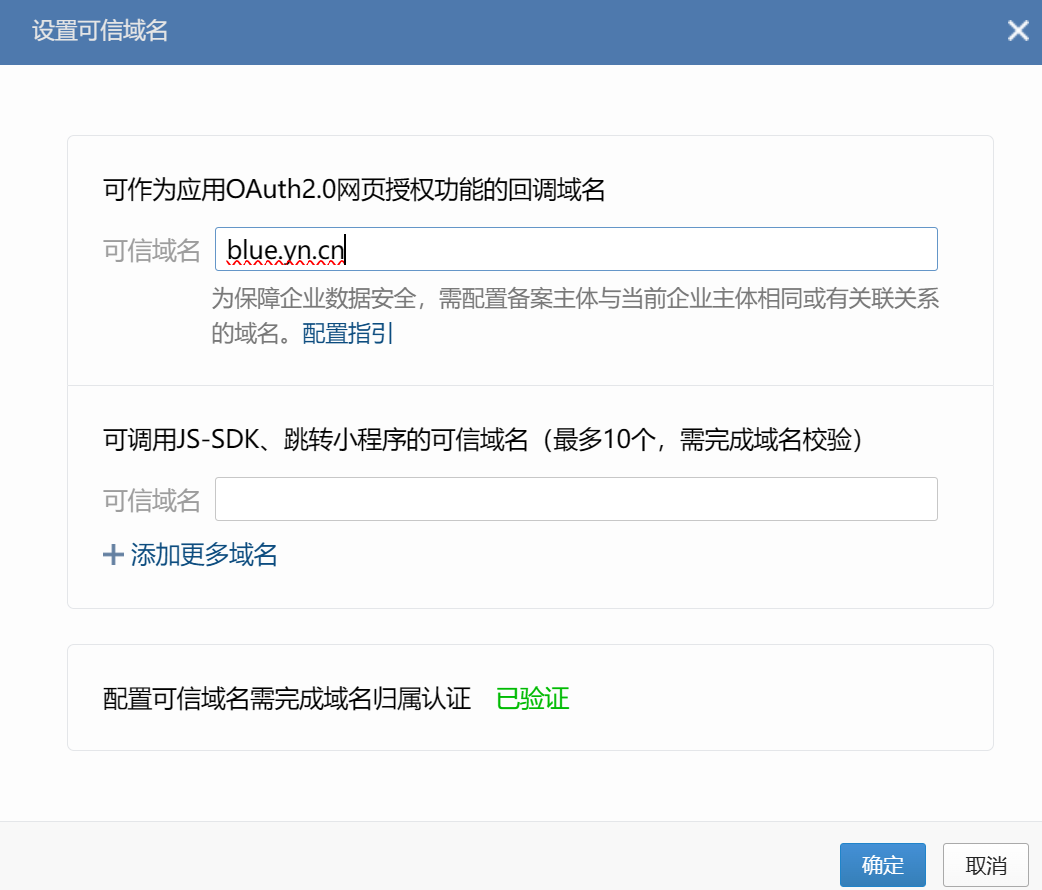
可信域名完成域名归属认证方法如下:
把WW_verify_hswWfpVABntC3f9n.txt传到blue.yn.cn域名所在网站服务器的/website/wordpress/目录下,
确保能访问bule.yn.cn/WW_verify_hswWfpVABntC3f9n.txt

定义报警媒介(发件人)
单击管理-->报警媒介类型-->创建媒体类型
设置如下:
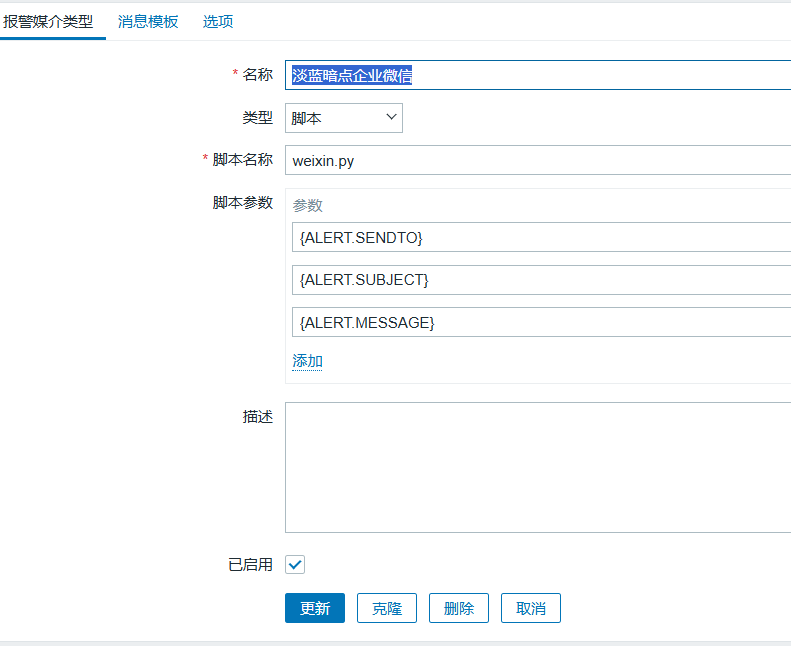
{ALERT.SENDTO} # 发送的用户
{ALERT.SUBJECT} # 发送的主题
{ALERT.MESSAGE} # 发送的内容
# 消息模板,消息类型:问题
主题:<font color="warning">告警通知</font>:设备**{HOST.NAME}**发生{TRIGGER.NAME}故障!
消息:
>告警地址:<font color="comment">{HOST.IP}</font>
>告警时间:<font color="comment">{EVENT.DATE} {EVENT.TIME}</font>
>告警内容:<font color="comment">{ITEM.LASTVALUE}</font>
>事件ID:<font color="comment">{EVENT.ID}</font>
#消息类型:问题恢复
主题:<font color="info">恢复通知</font>:设备{HOST.NAME}发生{TRIGGER.NAME}已恢复!
消息:
>地址:<font color="comment">{HOST.IP}</font>
>恢复时间:<font color="comment">{EVENT.DATE} {EVENT.RECOVERY.TIME}</font>
>持续时间:<font color="comment">{EVENT.DURATION}</font>
>内容:<font color="comment">{ITEM.LASTVALUE}</font>
>事件ID:<font color="comment">{EVENT.ID}</font>配置动作(通过哪个媒介发送给哪个用户)
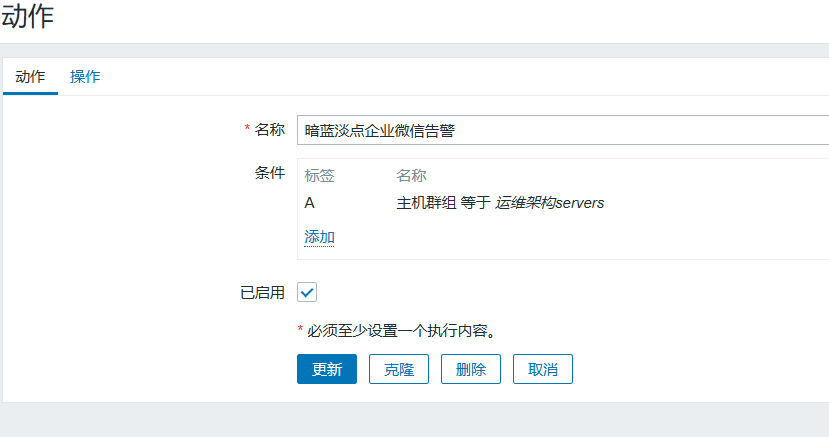
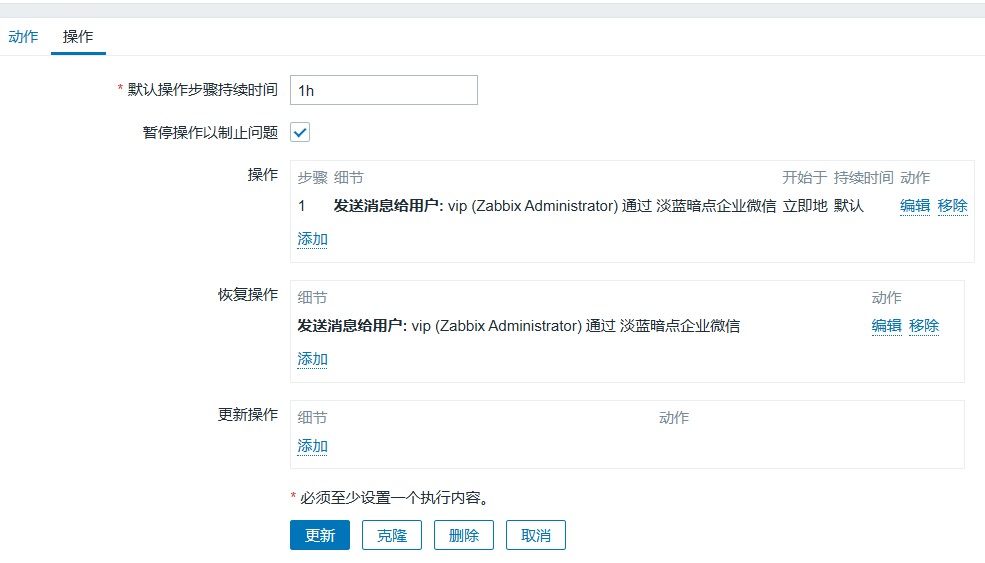
配置媒介(收件人)
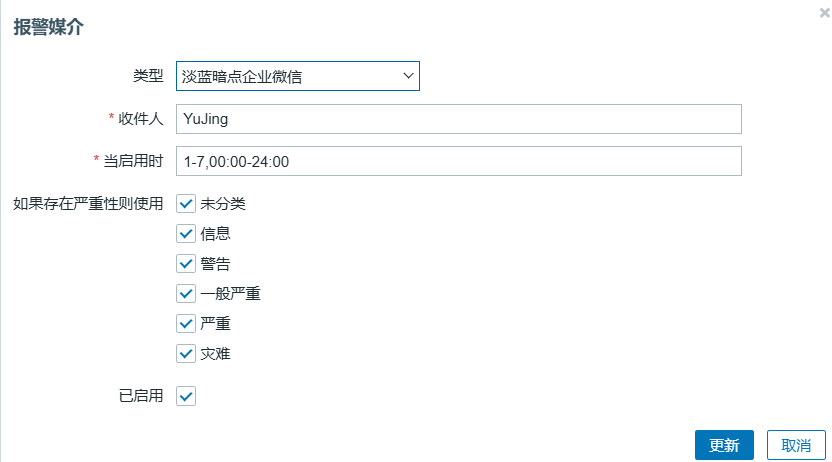
配置接收的企业微信号(收件人是企业微信中的用户账号)
报表-->动作日志

基于短信通知
- 使用阿里云短信进行通知,有几个前提:
- 1.必须购买阿里云短信服务(需要花钱)
- 2.需要申请签名、同时还需要申请短信模板
- 3.安装阿里云提供的
sdk(python版)
改写SDK示例脚本
pip安装sdk
pip install alibabacloud_dysmsapi20170525==2.0.24
- 修改
sdk示例,- 1.
access_key_id和access_key_secret
- 2.
phone_numbers,zabbix传参过来的手机号码 - 3.
sign_name=阿里云短信服务的签名名称, - 4.
template_code=模板CODE - 5.
template_param,zabbix传参过来的告警内容
- 1.
# -*- coding: utf-8 -*-
# This file is auto-generated, don't edit it. Thanks.
import os
import sys
from typing import List
from alibabacloud_dysmsapi20170525.client import Client as Dysmsapi20170525Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_dysmsapi20170525 import models as dysmsapi_20170525_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_tea_util.client import Client as UtilClient
class Sample:
def __init__(self):
pass
@staticmethod
def create_client() -> Dysmsapi20170525Client:
"""
使用AK&SK初始化账号Client
@return: Client
@throws Exception
"""
# 工程代码泄露可能会导致 AccessKey 泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考。
# 建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.html。
config = open_api_models.Config(
# 必填,请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_ID。,
# 因为进程zabbix调用不了root配置的环境变量,所以写道代码中
access_key_id='xxx',
# 必填,请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_SECRET。,
access_key_secret='xxx'
)
# Endpoint 请参考 https://api.aliyun.com/product/Dysmsapi
config.endpoint = f'dysmsapi.aliyuncs.com'
return Dysmsapi20170525Client(config)
@staticmethod
def main(
args: List[str],
) -> None:
client = Sample.create_client()
send_sms_request = dysmsapi_20170525_models.SendSmsRequest(
# zabbix传过来的第一个参数{ALERT.SENDTO}
phone_numbers=str(sys.argv[1]),
sign_name='暗蓝淡点',
template_code='SMS_467015253',
# zabbix传过来的第二个参数{ALERT.MESSAGE}
template_param=str(sys.argv[2])
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印 API 的返回值
client.send_sms_with_options(send_sms_request, runtime)
except Exception as error:
# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。
# 错误 message
print(error.message)
# 诊断地址
print(error.data.get("Recommend"))
UtilClient.assert_as_string(error.message)
@staticmethod
async def main_async(
args: List[str],
) -> None:
client = Sample.create_client()
send_sms_request = dysmsapi_20170525_models.SendSmsRequest(
# zabbix传过来的第一个参数{ALERT.SENDTO}
phone_numbers=str(sys.argv[1]),
sign_name='暗蓝淡点',
template_code='SMS_467015253',
# zabbix传过来的第二个参数{ALERT.MESSAGE}
template_param=str(sys.argv[2])
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印 API 的返回值
await client.send_sms_with_options_async(send_sms_request, runtime)
except Exception as error:
# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。
# 错误 message
print(error.message)
# 诊断地址
print(error.data.get("Recommend"))
UtilClient.assert_as_string(error.message)
if __name__ == '__main__':
Sample.main(sys.argv[1:])- 添加执行权限,脚本放到
/usr/lib/zabbix/alertscripts目录
chmod +x sms.py
- 本地
root用户测试
python3.6 sms.py 1897757xxx '{"title":" /etc/passwd has been changed","datetime":"2024.05.23 08:00:46","name":"腾讯云主机 139.199.79.133","info":"3699559811"}'
/usr/local/lib/python3.6/site-packages/alibabacloud_openapi_util/client.py:8: CryptographyDeprecationWarning: Python 3.6 is no longer supported by the Python core team. Therefore, support for it is deprecated in cryptography. The next release of cryptography will remove support for Python 3.6.
from cryptography.hazmat.backends import default_backend定义报警媒介(发件人)
单击管理-->报警媒介类型-->创建媒体类型
设置如下:
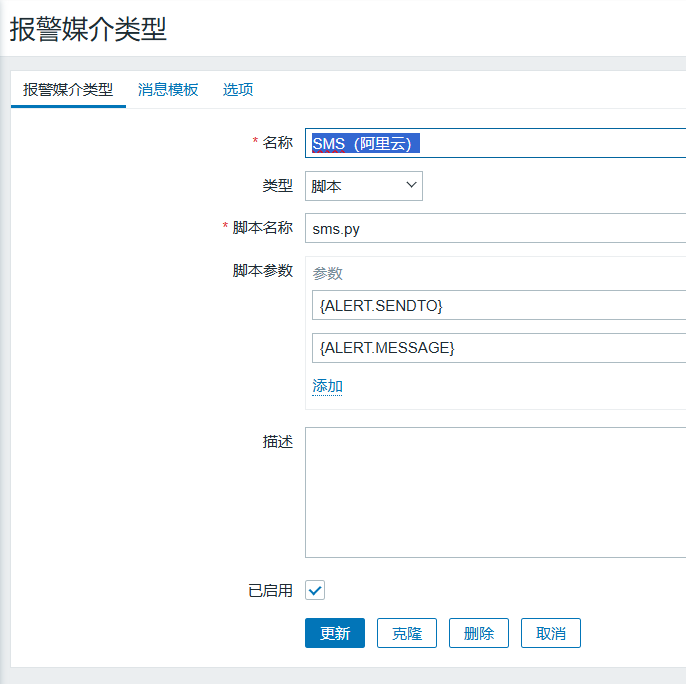
{ALERT.SENDTO} # 发送的用户
{ALERT.MESSAGE} # 发送的内容
# 消息模板,消息类型:问题
主题:zabbix告警
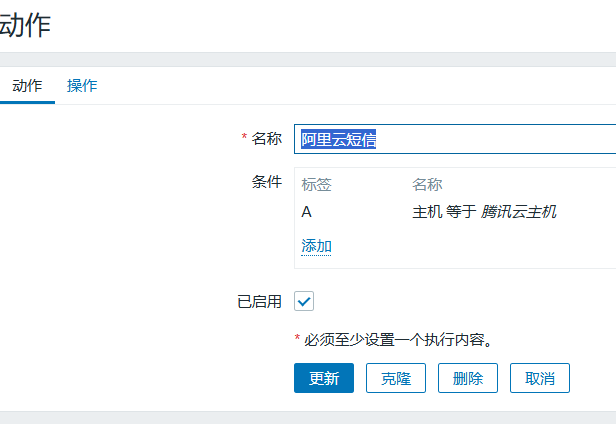
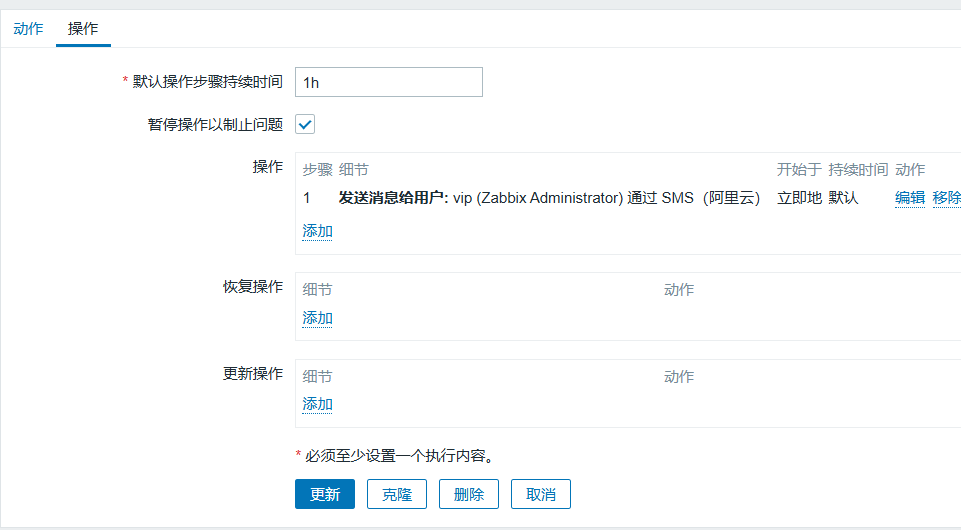
消息:{"title":" {TRIGGER.NAME}","datetime":"{EVENT.DATE} {EVENT.TIME}","name":"{HOST.NAME} {HOST.IP}","info":"{ITEM.VALUE1}"}配置动作(通过哪个媒介发送给哪个用户)
配置媒介(收件人)
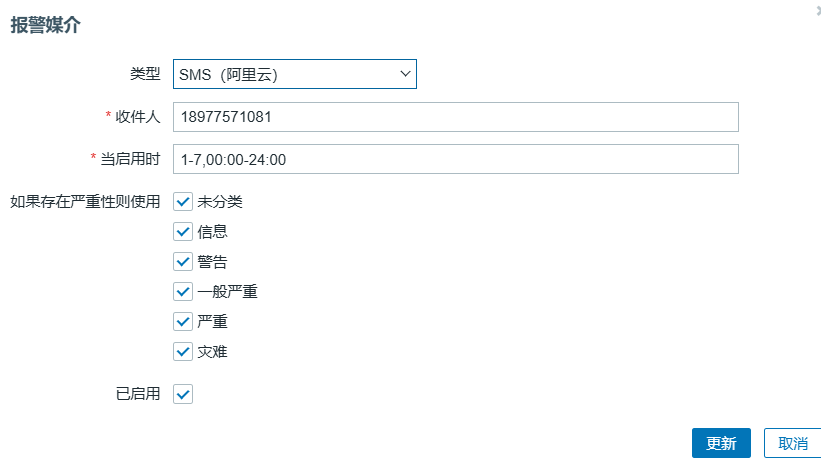
测试短信报警
通知升级
通知升级的作用
- 用户可以在一定时间内重复收到通知,直到问题解决
- 对于已知故障,或长期存在的故障,可以延时发送通知消息
- 对应长期没有解决的故障,可以升级至另一个更高级别的用户组,比如
leader
通知升级示例
通知升级示例1
每30分钟向mysql administrator组发送一次重复的通知(共5次)。配置如下:
- 在动作-->操作选项卡中,将默认操作步骤持续时间
default operation step duration设置为30m(30分钟) - 在操作细节界面将步骤设置为从1到5
- 选择
mysql administrator组作为消息的接收者
通知将分别在问题发生后的第一时间(0:00)以及30分钟(0:30)、1小时(1:00)、1个半小时(1:30)和2个小时(2:00)发生。(当然,除非问题已经被解决)
通知升级示例2
将问题升级到老板那里
如果监控项长时间处于一个反复报警的状态时,可能是没有人去解决也可能是他们无法解决。在这种情况下,将问题升级到经理之前,运维人员会收到四条消息。
注意:只有在问题尚未被确认的情况下(假设没有人处理这个问题),第五条消息经理才会收到消息。
默认操作步骤持续时间30m
步骤:1-0(0为无穷大)发送消息给运维人员(立即,每隔30分钟)
步骤:5发送消息给经理(2个小时后)
通知升级示例3
本示例展示了一个更为复杂的场景。在向mysql管理员发送了多个消息并升级到经理之后,zabbix将尝试重启mysql数据库。如果该问题持续了两个半小时还没得到确认,将会进行重启的操作。
如果问题仍然存在,则再过30分钟,zabbix将向所有来宾用户发送一条消息
如果还没有解决,则再过1小时,zabbix将使用命令重启mysql数据库服务器
默认操作步骤持续时间30m
步骤:1-0(0为无穷大)发送消息给运维人员(立即,每隔30分钟)
步骤:5发送消息给经理(2个小时后)
步骤:6运行远程命令重启mysql数据库(2个半小时后)
步骤:7发送消息给所有来宾用户(3个小时后)
步骤:9运行远程命令重启mysql数据库服务器(4个小时后)
通知升级示例4
发送关于一个长期存在的问题的延迟通知
- 在动作-->操作选项卡中,将默认操作步骤持续时间
default operation step duration设置为10h(10小时) - 将步骤设置为从2到2
通知只会在问题发生10小时后发送
默认操作步骤持续时间10h
步骤:2发送消息给运维人员(10小时后)
事件通知升级实践
当一个问题如果长时间没有被解决,则将该问题升级到leader那里
创建用户及用户组
- 点击管理-->用户组,创建
ops组,leader组 - 点击管理-->用户,创建用户
ops1,加入ops组,创建用户yujing加入leader组;报警媒介选项卡添加相关报警媒介类型
配置通知升级动作
配置-->动作,创建邮件通知升级步骤;
请注意{ESC.HISTORY}宏在自定义消息中的使用。该宏将包含关于此升级之前执行的所有步骤的信息,例如发送的通知和执行的命令
主题:PROBLEM:{EVENT.NAME}
告警主机:{HOST.NAME1}
告警服务:{ITEM.NAME1}
告警Key1:{ITEM.KEY1}:{ITEM.VALUE1}
告警Key2:{ITEM.KEY2}:{ITEM.VALUE2}
严重级别:{TRIGGER.SEVERITY}
此前步骤:{ESC.HISTORY}测试通知升级结果
- 1步是给
ops发送消息,立即发送 - 2步是给
ops发送消息,2分钟后发送一次 - 3-4步是给
leader发送消息,每隔2分钟发送一次,总共2个步骤,所以发送2次 - 5-6步是给
admin发送消息,每隔2分钟发送一次,总共2个步骤,所以发送2次
总结:1-2(2分钟),3-4(4分钟),5-6(4分钟),所以在触发告警放送时间计算是2m+4m+4m=10m
故障自愈功能
什么是故障自愈
当zabbix服务监控到指定的监控项异常时,可以通过指定的操作使故障自动修复
比如当运行的nginx服务没有响应了,我们可以通过远程命令方式让其自动重启,以达到恢复的效果
故障自愈应用场景
- 使用
IPMIrebboot命令,重启那些不响应请求的远程服务器 - 自动释放空间不足的磁盘(删除旧文件,清理/tmp等)
- 根据
cpu的负载情况,将虚拟机从一个物理机迁移到另一个物理机上 - 在
cpu(磁盘、内存等)资源不足的情况下,向云环境添加新的节点
配置故障自愈远程执行
配置远程命令的操作类似于发送消息,区别在于一个执行命令,一个发送消息
远程命令可以直接在zabbixserver、zabbixproxy、zabbixagent上执行
但在zabbix agent和zabbix proxy上,远程命令默认是不开启的,它们可以通过以下方式启用:
- 在
agnet配置中添加Allowkey=system.run[*]、UnsafeUserParameters=1参数 - 在
proxy配置中,将enableremotecomcommands参数设置为1
故障自愈示例
故障自愈示例1
在一定条件下重启windows
为了在zabbix检测到问题时自动重启windows定义了以下操作
| 参数 | 描述 |
|---|---|
| Operation type | remote command |
| Type | custom script |
| Command | c:\windows\system32\shutdown.exe -r -f |
故障自愈示例2
通过IPMI控制重启主机
| 参数 | 描述 |
|---|---|
| Operation type | remote command |
| Type | IPMI |
| Command | reset |
故障自愈示例3
通过IPMI控制关闭主机电源
| 参数 | 描述 |
|---|---|
| Operation type | remote command |
| Type | IPMI |
| Command | poweroff |
故障自愈示例4
当磁盘空间不足时,自动删除/tmp目录已获取更多空间
| 参数 | 描述 |
|---|---|
| Operation type | remote command |
| Type | custom script |
| Command | /user/bin/rm -f /tmp/* |
故障自愈实现场景
监控客户端tcp80端口,当端口不存活,则通过远程执行命令方式尝试重新启动
开启被控端远程执行命令
1.在被监控服务器上开启远程执行命令
vim /etc/zabbix/zabbix_agent2.conf
UnsafeUserParameters=1
Allowkey=system.run[*]
systemctl restart zabbix-agent22.为zabbix用户配置sudo权限,否则会出现权限不足情况
echo "zabbix ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
visudo -c
/etc/sudoers:解析正确为触发器添加对应动作
- 配置动作,配置条件(选择对应的触发器)
- 操作类型为远程命令,然后填写对应的重启命令(
sudo /usr/bin/systemctl restart nginx),目标列表勾选当前主机
严重故障自愈功能
- 关闭
nginx服务 - 触发动作后,会重启
nginx服务 nginx服务启动正常
当然也可以打开服务端debug调试模式,检测服务端执行日志
grep "nginx" /var/log/zabbix/zabbix_server.log
图形
什么是图形
随着大量数据流入zabbix,对于用户而言,如果可以通过可视化图形方式查看数据,而不仅仅是看到数字,那么更容易了解发生了什么事情
自定义图形
自定义图形,顾名思义,就是提供自定义定制的功能。自定义图形需要人为配置,可以为某台主机、多台主机、某个模板创建自定义图形。
聚合图形
什么是聚合图形
将多张大图整合为一张图形
将多个不同主机的图片整合在一张图上
聚合图形场景
聚合图形示例1
将一台主机的多个图片组合到一张聚合图形上,点击监测-->聚合图形-->创建聚合图形
聚合图形示例2
为多个不同的主机的模板创建一个图形,然后聚合至一张图形上
比如:为Template Module linux generic by Zabbix agent模板中[Number of processes]监控项,添加一个图形,然后所有主机调用,最后聚合在一张图上。
聚合图形轮播
可以将多个聚合图形放到一个幻灯片中,然后进行轮播展示
点击-->监测-->聚合图形-->幻灯片-->创建
模板
为何需要模板
- 1.为每隔主机单独添加监控项比较麻烦,例如100台主机增加一个
tcp80的监控项 - 2.修改监控项比较麻烦,例如100台服务器81端口改成82端口
- 3.删除主机,会连同主机的监控项一起被删除
所以我们可以使用模板的方式,来解决上述的一些问题
自定义模板
- 1.创建模板,模板需属于某个主机组(Templates)
- 2.在模板中创建监控项、图形、触发器
- 3.创建需要监控的主机,然后关联对应的模板
- 4.更改模板的监控项,所以使用模板的主机都会自动更改
- 5.导出模板,后期可以导入其他系统继续使用
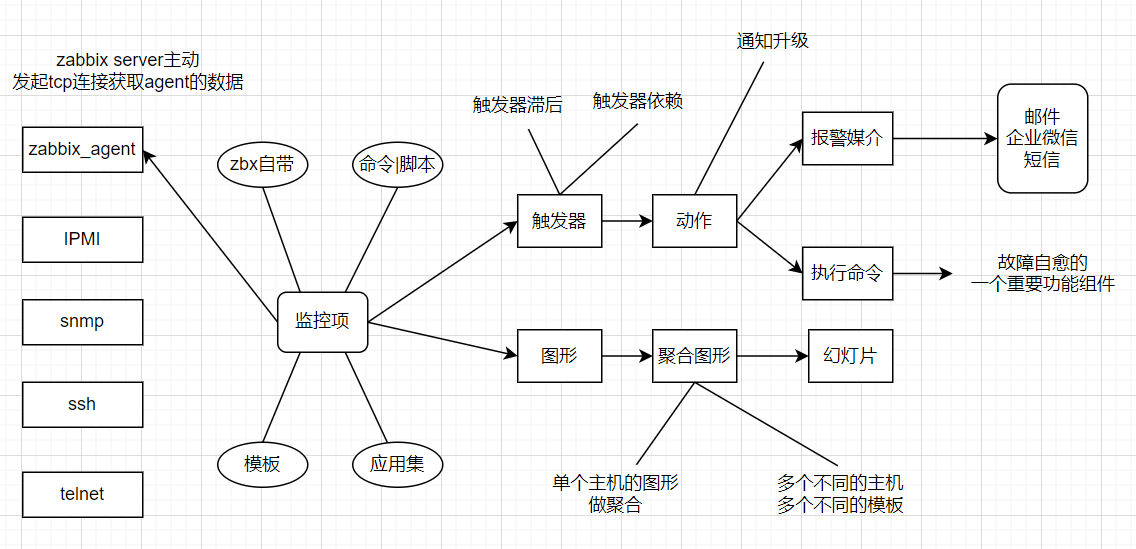
总结
数据流
此外,重要的是,需要回过头来了解下zabbix内部的整体数据流。
首先,为了创建一个采集数据的监控项,我们就必须先创建主机。
其次,必须有一个监控项来创建触发器。
最后,我们必须有一个触发器来创建一个动作,这几个点构成了一个完整的数据流。
因此,如果我们想要收到cpu load is too high on server x的告警,我们必须首先为server x创建一个主机条目,
其次创建一个用于监视其cpu的监控项,最后创建一个触发器,用来触发cpu is too high这个动作,并将其发送到邮箱。
虽然这些步骤看起来很繁琐,但是使用模板的话,其实并不复杂。
也正是由于这种设计,使得zabbix的配置变得更加灵活易用。
留言