PromQL资源监控案例
监控系统资源方法论
- 1.
google的四个黄金指标着眼点在服务监控,这四个指标分别是延迟、流量、错误、饱和度。 - 2.
red方法主要着眼点在用户体验,它基于google的黄金指标,细化了三个关键指标:请求率、错误数、请求处理时间 - 3.
use方法主要着眼点在系统资源的使用i情况,这三个指标分别是使用率、饱和度、错误。
使用use监控系统资源
在监控cpu、内存、磁盘和网络等系统资源时,使用use的方法论是最为合适的,它要求我们针对每个资源(也就是cpu、内存、网络等)分别检查三个关键方面:使用率、饱和度和错误。
- 使用率:表示资源在工作时占用的平均时间,例如,
cpu在过去的60秒内有30秒被用来执行指令,那么我们可以说这个cpu的使用率是50% - 饱和度:指明资源已经到达或接近其处理能力极限的程度,表明无法再处理更多的工作量。这通常通过队列长度等指标来衡量。
- 错误:记录了资源在运行过程中发生的错误事件的次数。
cpu监控案例实践
cpu重点监控的维度
对应cpu资源的监控,采用use方法论通常关注以下几点:
cpu使用率:衡量cpu在一段时间内处于活跃状态的百分比。高使用率可能表明系统正在密集执行任务。cpu饱和度:反映了在某一时间点等待cpu时间的进程数量。高饱和度可能意味着有很多任务在争夺cpu资源。- 错误,通常对
cpu不太影响
计算cpu平均使用率
计算cpu平均使用率的公式:(1-cpu空闲率)*100=cpu使用率
-
获取每个
cpu模式的变化率,使用irate函数灵敏度更高,反映更接近实际使用率
irate(node_cpu_seconds_total[1m]) -
查询
cpu的空闲时间比率,即cpu处于空闲状态的时间比例
irate(node_cpu_seconds_total{mode="idle"}[1m]) -
系统可能会有多个
cpu核心,因此我们需要通过avg聚合函数来计算cpu的平均空闲率,最后按照实例进行分组统计。
avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) -
使用1减去每个核心的平均空闲率,得到平均使用率,然后将此值乘以100,转换为百分比,最终得出
cpu的整体平均使用率
(1-avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) * 100
计算cpu饱和度
评估主机的cpu饱和度,最常用的方法是跟踪系统的平均负载。通常情况下,如果这个负载的值低于cpu核心的数量,可以认为系统运行正常。然而,当平均负载持续高于cpu核心数量的两倍时,这通常是cpu已经非常饱和了。
计算cpu饱和度的公式:1分钟平均负载/(cpu核心数2)100=cpu饱和度的百分比,当大于80%则认为cpu已经接近处理能力的极限。
-
获取1分钟平均负载值,然后按照实例和
job进行分组计算
sum(node_load1) by (instance,job) -
获取
cpu的核心数,然后乘以2,按实例进行分组计算每个实例的核心数
count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2 -
计算
cpu饱和度百分比,如果这个百分比大于80%,
sum(node_load1) by (instance,job)
/
(count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100配置cpu告警规则
- 定义
cpu告警规则组,然后注入两条规则
cat node_rules.yml
groups:
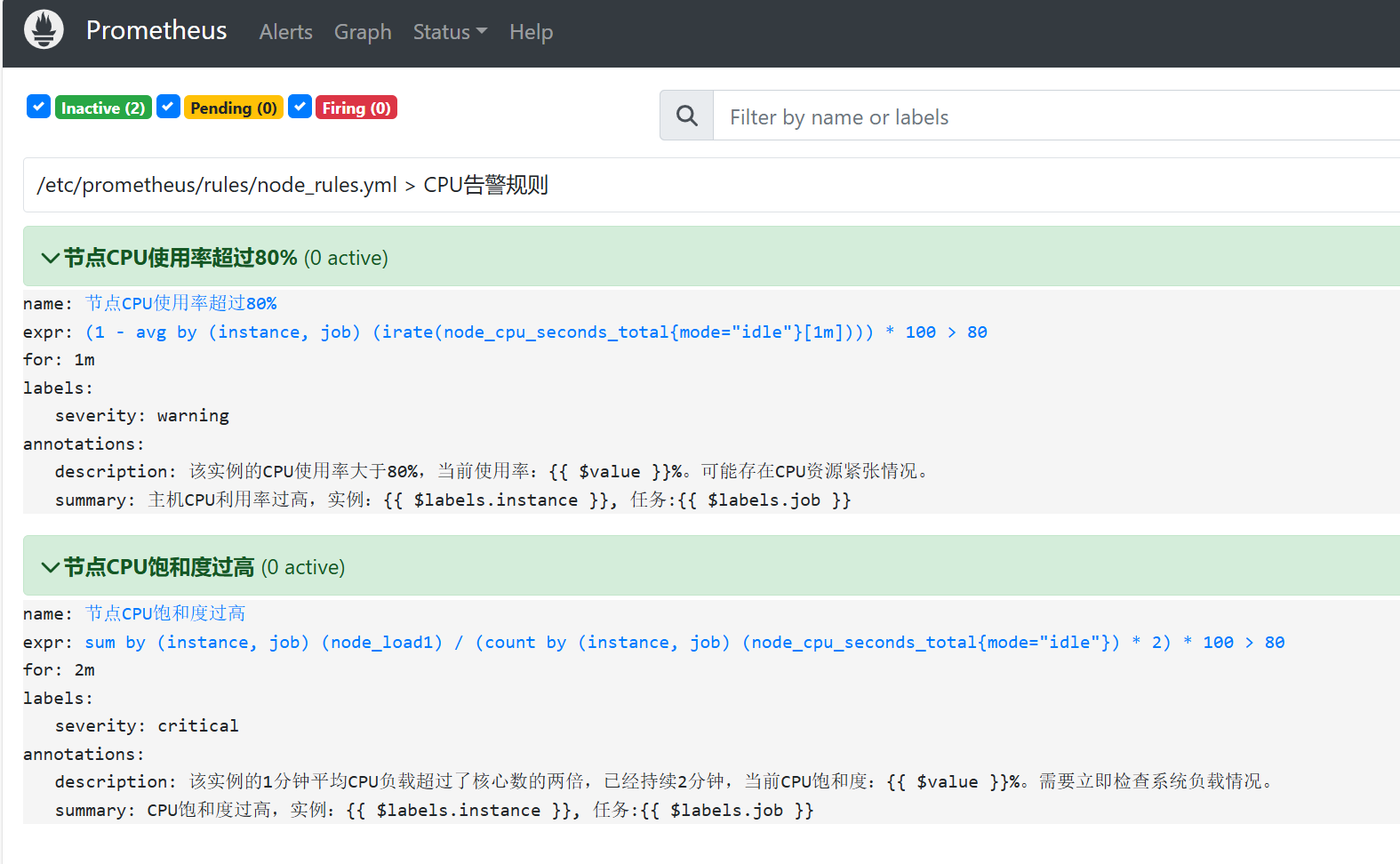
- name: CPU告警规则
rules:
- alert: 节点CPU使用率超过80%
expr: ( 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance,job) ) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "主机CPU利用率过高,实例:{{ $labels.instance }}, 任务:{{ $labels.job }}"
description: "该实例的CPU使用率大于80%,当前使用率:{{ $value }}%。可能存在CPU资源紧张情况。"
- alert: 节点CPU饱和度过高
expr: sum(node_load1) by (instance,job) / (count(node_cpu_seconds_total{mode="idle"}) by (instance,job) * 2) * 100 > 80
for: 2m
labels:
severity: critical
annotations:
summary: "CPU饱和度过高,实例:{{ $labels.instance }}, 任务:{{ $labels.job }}"
description: "该实例的1分钟平均CPU负载超过了核心数的两倍,已经持续2分钟,当前CPU饱和度:{{ $value }}%。需要立即检查系统负载情况。"-
检查告警规则配置是否正确
/etc/prometheus/promtool check rules /etc/prometheus/rules/node_rules.yml Checking /etc/prometheus/rules/node_rules.yml SUCCESS: 2 rules found -
加载配置文件
# 配置文件添加告警文件路径
cat prometheus.yml
rule_files:
- "/etc/prometheus/rules/*.yml"
# 加载配置文件
curl -X POST http://localhost:9090/-/reloadprometheus alerts页面效果
内存监控案例实践
内存重点监控的维度
对于内存资源的监控,采用use方法论通常关注以下几点:
- 1.内存使用率:衡量系统内存被使用的成都
- 2.内存饱和度:表明系统内存的负载程度。内存饱和度,通常监控
swap的使用率来评估 - 3.内存错误:通常较少发生。
计算内存使用率
计算内存使用率百分比公式:(总内存-可用内存)/总内存*100=内存使用率
(node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes*100
计算内存饱和度
计算内存饱和度百分比公式:(总swap-未使用的swap)/总swap*100
(node_memory_SwapTotal_bytes-node_memory_SwapFree_bytes)/node_memory_SwapTotal_bytes*100
配置内存告警规则
- 定义内存告警规则组,然后注入两条规则
cat /etc/prometheus/rules/node_rules.yml
groups:
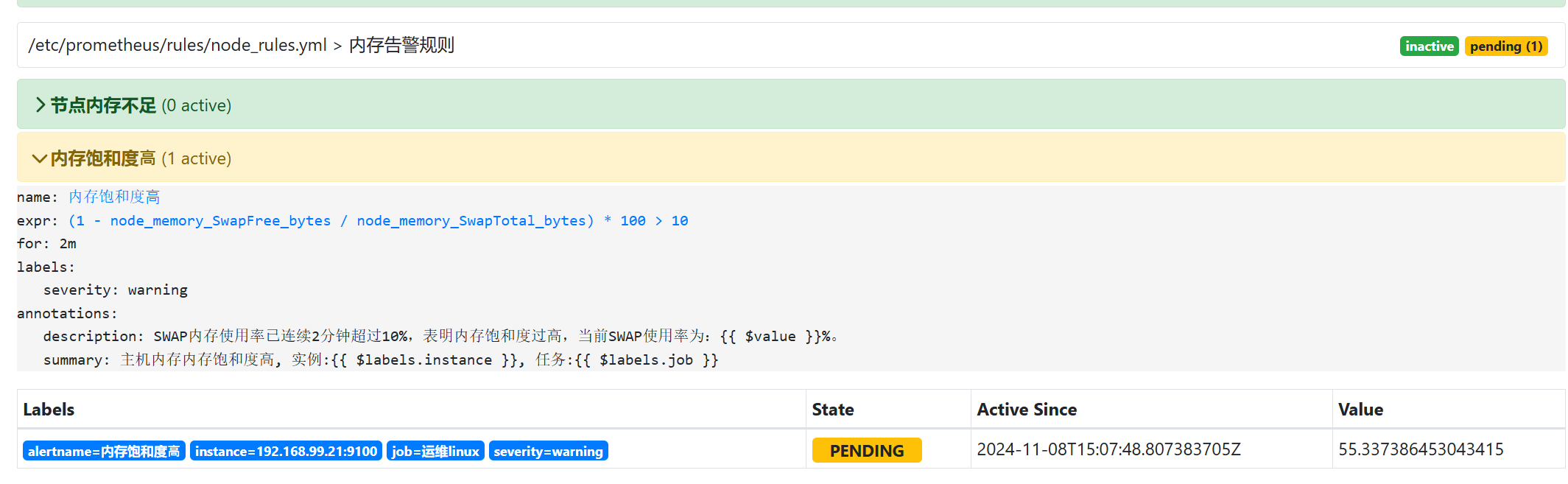
- name: 内存告警规则
rules:
- alert: 节点内存不足
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/ node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "主机内存使用率较高, 实例:{{ $labels.instance }}, 任务:{{ $labels.job }}"
description: "该实例的内存使用率持续2分钟高于80%,当前使用率率:{{ $value}}%"
- alert: 内存饱和度⾼
expr: ( 1 - node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes) * 100 > 10
for: 2m
labels:
severity: warning
annotations:
summary: "主机内存内存饱和度高, 实例:{{ $labels.instance }}, 任务:{{ $labels.job }}"
description: "SWAP内存使用率已连续2分钟超过10%,表明内存饱和度过高,当前SWAP使用率为:{{ $value }}%。"-
测试规则配置文件,然后重新加载
prometheus配置文件 -
prometheus alerts页面效果
磁盘监控案例实践
磁盘重点监控的维度
对于磁盘,我们不光需要度量磁盘使用率,甚至还需要度量磁盘io读写吞吐量、以及磁盘iops
- 1.磁盘使用率:衡量磁盘空间使用率、
inode使用率 - 2.磁盘延迟:有些磁盘明确标注了延迟,我们可以监控磁盘的读写延迟,而后进行判定;
- 3.磁盘饱和度:通过监控
i/o吞吐量和iops,可以衡量磁盘在繁忙时段的饱和度情况。
常规磁盘的每秒的iops能力和io吞吐量,有标准后,就好基于标准进行触发器设定,例如当iops每秒读写次数的饱和度超过80%则需要关注了
| 性能类别 | ESSD云盘(PL3) | SSD云盘 | 高效云盘 | 普通云盘 |
|---|---|---|---|---|
| iops(每秒能完成的读写次数) | 1000000/s | 最大25000/s、最小2400/s | 最大5000/s、最小1960/s | 最大80~150/s |
| io吞吐量(每秒传输大小) | 最大4000MB/s | 最大300MB/s、最小130MB/s | 最大140MB/s、最小103MB/s | 30MB/s~40MB/s |
计算磁盘空间使用率
计算磁盘空间使用率:(总的磁盘空间-可用的磁盘空间=已用的磁盘空间)/总的磁盘空间100
计算inode空间使用率:(总的inode数-可用的inode数)/总的inode数100
-
计算不同分区的磁盘空间使用率(排除
tmpfs的分区)
(node_filesystem_size_bytes{device!="tmpfs"}-node_filesystem_avail_bytes{device!="tmpfs"})/node_filesystem_size_bytes{device!="tmpfs"}*100 -
计算
inode使用率(排除tmpfs的分区)
(node_filesystem_files{device!="tmpfs"}-node_filesystem_files_free{device!="tmpfs"})/node_filesystem_files{device!="tmpfs"}*100
计算磁盘io吞吐量
i/o吞吐量:衡量在单位时间内磁盘能够读写多少数据量,通常以MB/s(兆字节每秒)为单位
i/o吞吐量饱和度(%)=(当前i/o吞吐量/磁盘的最大i/o吞吐量能力)*100
-
模拟
io写入吞吐量,并限制写入io最大20MB/s
dd if=/dev/zero bs=1M count=10000 | pv -L 20M > /tmp/bigdata -
获取当前磁盘最近1分钟的,写入吞吐量最大的值,然后按实例进行分组计算,最后将结果转为
MB
round(max(irate(node_disk_written_bytes_total[1m])) by (instance,job)/1024/1024) -
当前
io写入吞吐量除以磁盘最大写入io吞吐量,乘以100,获取io吞吐量的饱和度百分比
(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024 /1024) / 30 * 100
# 告警(当IO写⼊吞吐⼤于80%则触发告警)
round(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024/1024 / 30 * 100) > 80- 模拟
io读取吞吐量,并限制读取io最大20MB/s
# yum install pv -y
# pv -L 20M /tmp/bigdata > /dev/null-
获取当前磁盘最近1分钟读取吞吐量最大的值,然后按实例进行分组计算,最后将结果转为
MB
round(max(irate(node_disk_read_bytes_total[1m])) by (instance,job)/1024/1024) -
使用当前
io读取吞吐量除以磁盘最大读取io吞吐量,乘以100,获取io吞吐量的饱和度百分比
max(irate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /30 * 100
# 告警(当IO写⼊吞吐⼤于80%则触发告警)
round(max(irate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /30 * 100 ) > 80计算磁盘iops
iops:衡量在单位时间内磁盘能够读写操作的次数。
iops饱和度(%):(当前iops/磁盘的最大iops能力)*100
-
模拟
io写入吞吐量,也相当于有大量iops
dd if=/dev/zero bs=1M count=10000 | pv -L 100M > /tmp/bigdata -
获取当前磁盘最近1分钟的
iops写入次数的最大值,然后按实例进行分组计算
max(irate(node_disk_writes_completed_total[1m])) by (instance,job) -
使用当前
iops写入次数除以磁盘最大iops,乘以100,获取iops写入的饱和度百分比
max(irate(node_disk_writes_completed_total[1m])) by (instance,job) / 120 *100
# 告警(当IOPS饱和度⼤于60%则触发告警)
round(max(irate(node_disk_writes_completed_total[1m])) by (instance,job) /120 * 100) > 60- 模拟
io读取,也相当于有大量ios
# yum install pv -y
# pv -L 50M /tmp/bigdata > /dev/null-
获取当前磁盘最近1分钟读取
iops最大次数的值,然后按实例进行分组计算
max(irate(node_disk_reads_completed_total[1m])) by (instance,job) -
使用当前
io读取吞吐量除以磁盘最大读取io吞吐量,乘以100,获取iops读取的饱和度百分比。
max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 120 * 100
# 告警(当IOPS读取⼤于60%则触发告警)
round(max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 120 * 100) > 60配置磁盘告警规则
- 编写磁盘告警规则文件
cat /etc/prometheus/rules/node_rules.yml
groups:
- name: 磁盘告警规则
rules:
- alert: 磁盘空间告急
expr: ( node_filesystem_size_bytes{device!="tmpfs"} - node_filesystem_avail_bytes{device!="tmpfs"} ) / node_file system_size_bytes{device!="tmpfs"} * 100 > 70
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 磁盘 {{ $labels.mountpoint }}分区空间不足"
description: "实例 {{ $labels.instance }} 磁盘 {{ $labels.mountpoint}} 分区空间使用率已超过 70%,当前使用率为 {{ $value }}%,请及时处理。"
- alert: 磁盘Inode空间告急
expr: (node_filesystem_files{device!="tmpfs"} - node_filesystem_files_free{device!="tmpfs"} ) / node_filesystem_ files{device!="tmpfs"} * 100 > 70
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 磁盘 {{ $labels.mountpoint }}分区Inode空间不足"
description: "实例 {{ $labels.instance }} 磁盘 {{ $labels.mountpoint}} 分区的Inode空间使用率已超过 70%,当前使 用率为 {{ $value }}%,请及时处理。"
- alert: 磁盘IOPS写入较高
#expr: sum(rate(node_disk_writes_completed_total[1m])) by (instance,job) / 5000 * 100 >60
#round函数可以对值进行四舍五入
expr: round(max(irate(node_disk_writes_completed_total[1m])) by (instance,job) / 5000 * 100) > 60
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} IOPS每秒写入次数超过3000次/s"
description:
目前磁盘IOPS写入饱和度是 {{ $value }}%
目前磁盘IOPS每秒写入最大 {{ printf `max(rate(node_disk_writes_completed_total{instance="%s",job="%s"}[1m]))` $labels.instance $labels.job | query | first | value | printf "%.2f" }} 次/s
- alert: 磁盘IOPS读取较高
expr: round(max(irate(node_disk_reads_completed_total[1m])) by (instance,job) / 5000 * 100) > 60
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} IOPS每秒读取次数超过3000次/s"
description:
目前磁盘IOPS读取饱和度是 {{ $value }}%
目前磁盘IOPS每秒读取最大 {{ printf `max(rate(node_disk_reads_completed_total{instance="%s",job="%s"}[1m]))` $labels.instance $labels.job | query | first | value | printf "%.2f" }} 次/s
- alert: 磁盘IO写入吞吐较高
expr: round(max(rate(node_disk_written_bytes_total[1m])) by (instance,job) / 1024 /1024 / 140 * 100) > 60
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 磁盘IO写⼊每秒超过最大84MB/s"
description:
目前磁盘IO写入吞吐量的饱和度是 {{ $value }}%。
目前磁盘IO写入吞吐量每秒最大是 {{ printf `max(rate(node_disk_written_bytes_total{instance="%s",job="%s"}[1m] )) /1024/1024` $labels.instance $labels.job | query | first | value | printf "%.2f" }}MB/s
- alert: 磁盘IO读取吞吐较高
expr: round(max(rate(node_disk_read_bytes_total[1m])) by (instance,job) / 1024 /1024 /140 * 100 ) > 60
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 磁盘IO读取每秒超过最大84MB/s"
description:
目前磁盘IO读取吞吐量的饱和度是 {{ $value }}%。
目前磁盘IO读取吞吐量每秒最大是 {{ printf `max(rate(node_disk_read_bytes_total{instance="%s",job="%s"}[1m])) /1024/1024` $labels.instance $labels.job | query | first | value | printf "%.2f" }}MB/s- 检查告警规则文件

网络监控案例实践
网络重点监控的维度
对于网络,通常使用use方法监控如下几个维度:
- 1.网络传输速率:即当前网络每秒传输的带宽
- 2.网络饱和度:对于网络饱和度,通常查看网络是否丢包严重,如果持续有丢包情况则任务目前网络比较饱和
- 3.网络错误率:可以通过监控网络发送和接收的错误来获得
计算网络传输速率
网络传输速率= irate(网络接口发送/接收的总数据量)*8/1024/1024=Mbps
- 模拟带宽
# 1、在两个测试的节点上安装:yum install iperf -y
# 2、服务端运⾏并指定端⼝:iperf -s -p 9999
# 3、客户端模拟带宽发送命令,-b指定发送⼤⼩,-t指定发送持续时⻓:iperf -c <ip> -p 9999 -b 300M -t 60-
获取最大的下载带宽,也就是每秒能接收多少
Mbps
max(irate(node_network_receive_bytes_total{device!~"ethA.*|ethB.*|lo|bond0"}[1m])*8/1024/1024) by (instance,job,device) -
获取最大的上传带宽,也就是每秒能传输多少
Mbps
max(irate(node_network_transmit_bytes_total{device!~"ethA.*|ethB.*|lo|bond0"}[1m])*8/1024/1024) by (instance,job,device) -
假设公司带宽是
50Mbps,我希望达到40Mbps时则触发告警,计算公式:网络每秒传输带宽/网络最大带宽 * 100 >= 80
# 下载
max(irate(node_network_receive_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80
# 上传
max(irate(node_network_transmit_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 50 * 100 >= 80计算网络连接数使用率
网络连接率 = 当前活跃tcp连接数 / 系统内核最大支持的tcp连接数 * 100
(node_nf_conntrack_entries / node_nf_conntrack_entries_limit) * 100
# 告警
(node_nf_conntrack_entries / node_nf_conntrack_entries_limit) * 100 > 80配置网络告警规则
- 配置网络告警规则
cat /etc/prometheus/rules/node_rules.yml
- name: 网络络告警规则
rules:
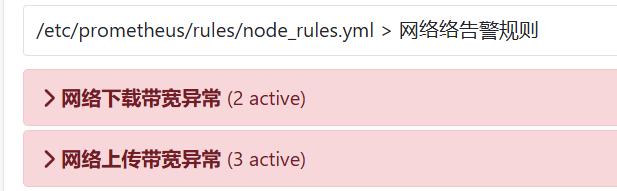
- alert: 网络下载带宽异常
expr: max(irate(node_network_receive_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 1000 * 100 >= 80
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 的 {{ $labels.device }} 接口下载流量已经超过800Mbps"
description:
目前下载带宽已经达到 {{ printf `(irate(node_network_receive_bytes_total{instance="%s",job="%s",device="%s"}[1m]) * 8 / 1024 / 1024)` $labels.instance $labels.job $labels.device | query | first | value | printf "%.2f"}} Mbps/s
目前下载带宽使用率在 {{ $value }}%
- alert: 网络上传带宽异常
expr: max(irate(node_network_transmit_bytes_total[1m]) * 8 / 1024 / 1024) by (instance,job,device) / 1000 * 100 >= 80
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 的 {{ $labels.device }} 接口上传流量已经超过800Mbps"
description:
目前上传带宽已经达到 {{ printf `(irate(node_network_transmit_bytes_total{instance="%s",job="%s",device="%s"}[1m]) * 8 / 1024 / 1024)` $labels.instance $labels.job $labels.device | query | first | value | printf "%.2f"}} Mbps/s
目前上传带宽使用率在 {{ $value }}%
- alert: 网络TCP连接数异常
expr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit * 100 > 80
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 的 tcp连接数超过80%"
description:
目前TCP连接数是 {{ printf `node_nf_conntrack_entries{instance="%s",job="%s"}` $labels.instance $labels.job | query | first | value | printf "%.2f" }}
目前TCP连接使用率是 {{ $value }}%prometheus web界面查看告警
留言