PromQL基础概念
什么是PromQL
prometheus内置了一种强大的查询语言:PromQL,即prometheus query language。
PromQL允许用户实时查询监控数据,并对这些数据执行复杂的聚合和计算操作。
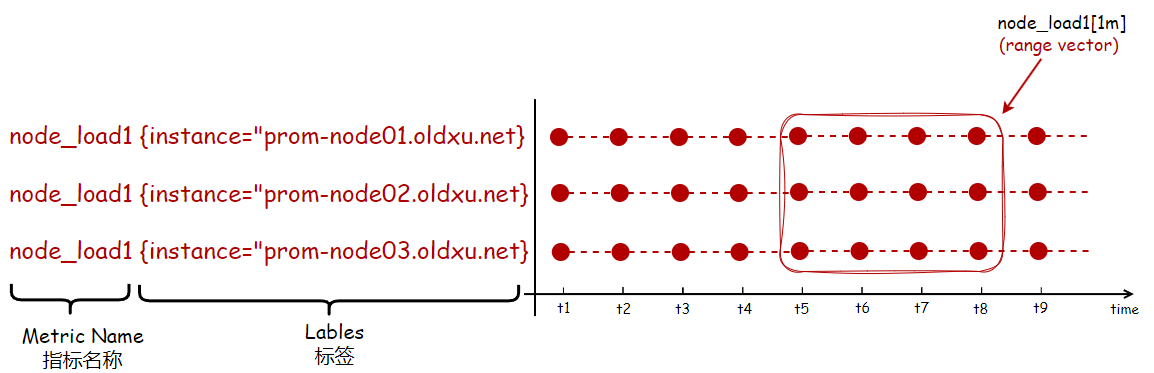
在PromQL,查询的结果被称为向量(vector),分为两种类型:
- 即时向量(
instant vector):即时向量查询返回的是一组时间序列数据,但每个时间序列中只包含单个的最新数据点。例如:查询当前时刻服务器1分钟的负载,所得到的结果就是一个即时向量。

- 范围向量(
range vector):范围向量查询的结果包含了一个时间范围内的所有数据点。例如:查询过去1分钟内服务器负载的变化情况,返回的数据集就是一个范围向量。
在PromQL中,除了有向量类型的数据,还有其他的数据类型,具体有标量(scalar):标量仅代表一个单一的浮点数值。可以将向量的某一个值通过scalar()函数转为标量,然后进行数值运算,但使用较少。
字符串(string):在PromQL查询结果中,每个事件序列都伴随着一组标签,这些标签和标签值,就是使用字符串类型来定义的。这些标签为时间序列提供了元数据信息,例如 {job="nginx",instance="prom-node01.oldxu.net", method="get", url="/api"},通过标签能很好的对数据进行分类和识别。
PromQL应用场景
prometheus的核心就是PromQL,PromQL在日常的数据可视化,查询、定义告警规则都会用到,因此掌握PromQL基本上就掌握了prometheus
- 临时查询:使用
PromQL,你可以实时地查询监控数据,这对于调试和诊断问题非常有帮助。通常,我们通过prometheus自带的表达式浏览器来执行这些查询。
-
数据可视化,
PromQL可以帮助我们创建数据的可视化展示,这些可视化通常是通过集成工具如grafana来实现的,可以将我们PromQL查询的结果展示得更直观。 -
监控告警:
prometheus可以直接使用PromQL对指标的查询结果来设置告警。一旦查询结果满足指定的条件,就会触发告警,一个完整的报警规则如下所示:包括了告警的名称、条件、持续时间等信息。
groups:
- name: 告警组
rules:
- alert: 节点宕机 # 告警名称
expr: up == 0 # 告警条件
for: 1m # 持续时间
labels:
severity: critical
annotations: # 定义邮件中收到的告警详细内容
summary: "节点宕机警告 - 实例:{{ $labels.instance }}"
description: "作业 {{ $labels.job }} 的节点⽆法访问,已经持续超过1分钟。"PromQL基础使用
指标查询
- 查询指标的最直接方式是输入指标的名称。比如,你想知道系统的一分钟负载(
node_load1)情况:
# 查询表达式
node_load1
# 查询结果(结果展示了所有被监控节点的一分钟负载)
node_load1{instance="192.168.99.7:9100", job="node_exporter"} 0
node_load1{instance="192.168.99.21:9100", job="node_exporter"} 0.89- 但是,在实际监控时,我们通常只需要关注特定节点的指标数据。例如,如果我们只想查看192.168.99.21这个节点的一分钟负载情况,那么就需要使用标签匹配器来筛选出所需的指标。
# 查询表达式
node_load1{instance="192.168.99.21:9100"}
# 查询结果(由于指定了过滤条件,因此只会展示匹配节点的1分钟负载)
node_load1{instance="192.168.99.21:9100", job="node_exporter"} 0.12- 因此,标签匹配器就是通过标签和标签值,来筛选出我们所需要的指标数据。使用标签匹配器时,可以按照以下语法构造查询表达式:
<metric_name>{<label_name>=<label_value>, <label_name2>=~<regex>, ...}
其中各个部分的含义如下:
# = 表示⼀个标签必须严格等于⼀个给定的值。
# != 表示排除等于特定值的标签。
# =~ 表示标签的值必须匹配⼀个正则表达式。
# !~ 表示标签的值不应匹配⼀个正则表达式。实例1:查询所有实例,cpu的第0个核心中的user用户空间所占用cpu的时间,指标名称:node_cpu_seconds_total
node_cpu_seconds_total{cpu="0",mode="user"}
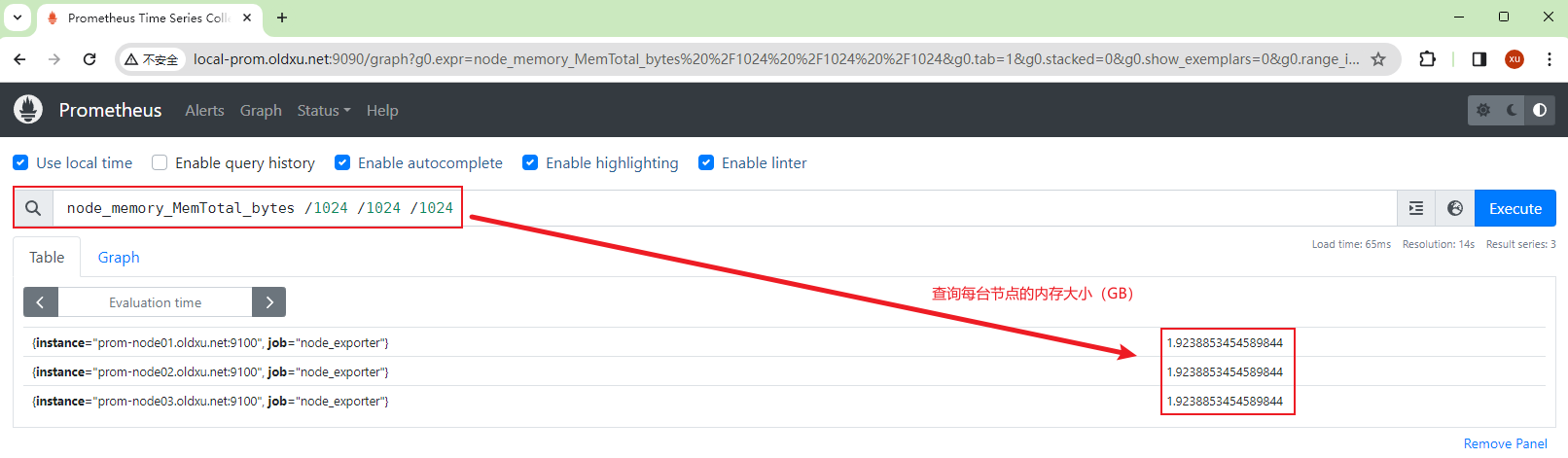
实例2:查询所有实例,eth0网卡发送总大小,指标名称:node_network_transmit_bytes_total
node_network_transmit_bytes_total{device="eth0"} /1024 /1024 /1024
实例3:查询所有实例的网卡接收字节数,排除lo接口,指标名称:
node_network_receive_bytes_total
node_network_transmit_bytes_total{device!="lo"} /1024 /1024 /1024
实例4:查询挂载点以/run开头的文件系统可用字节数,指标名称:node_filesystem_avail_bytes
node_filesystem_avail_bytes{mountpoint=~"^/run.*"} /1024 /1024
实例5:块设备名字不包含vda和sr0的读字节数,指标名称:node_disk_read_bytes_total
node_disk_read_bytes_total{device!~"vda|sr0"}
时间范围查询
在prometheus中,范围向量选择器使我们能够提取时间序列中一段时间范围内的数据点。要定义一个范围向量选择器,你只需要在指标名称后面加上方括号[],并在其中指定一个时间长度。时间长度有:s秒、m分钟、h小时、d天、w周、y年。使用范围向量选择器,你可以灵活查询从最近几分钟到几年的数据,便于分析和监控指标随时间的变化。
- 例如,我们想查询
192.168.99.21这个实例,在过去2分钟负载的所有数据点。
# 时间查询表达式
node_load1{instance="192.168.99.21:9100"}[1m]
# 查询结果(排序方式,从旧到新)
node_load1{instance="192.168.99.21:9100", job="node_exporter"}
0.54 @1730640927.056
0.42 @1730640942.056
0.68 @1730640957.056
0.53 @1730640972.056- 在
prometheus中,通常使用相对时间(如果去几分钟、小时或天)来查询数据。但是,如果你需要查询一个绝对时间点的数据,你可以直接使用unix时间戳来指定查询的具体时间。(在prometheus中通常是以毫秒为单位的)
时间偏移查询
除了能够查询过去几分钟或几个小时的数据,以及查询指定时间点的数据,同时prometheus也允许你通过offset修饰符来指定查询从当前时间往回推某个具体的时间段。这种方式常用于比较,例如:今天qps是10000,昨天这个时间是5000,我们就可以计算它们的增长率之类的。
- 如果你想要查看昨天整体的数据,可以使用以下查询表达式:
# 假设以下表达式查询的结果是 2024-11-03 21:50
node_load1
# 那么如下表达式查询的数据将返回:(2024-11-01 21:50 - 2024-11-02 21:50)
node_load1[1d] offset 1d- 如果想要查看一周前的时间范围内的数据,可以使用如下查询
# 查询表达式
node_load1[5m] offset 1w这个查询会返回当前时间往回推一周,并从那个时间点开始,往回推持续5分钟的数据范围内的node_load1指标。例如,如果现在是11月3日星期天晚上21:50,那么该查询将返回10月27日星期天晚上21:45到21:50这5分钟范围内的所有数据点。
- 对比分析实战:对比当前时间点接收的网络流量与1小时前的流量进行比对分析,以判断流量是增长还是减少。
-
计算同环比的增长率或减少率的公示:同环比率=(当前总流量-过去1小时的总流量)/过去1小时的总流量*100
-
例如,如果当前总接收流量是6000MB,而1小时前接收的总流量是5000MB
-
那么计算公式为:(6000-5000)/5000*100=20%(意味着相比1小时前,当前流量增长了20%)
# 表达式
((node_network_receive_bytes_total - node_network_receive_bytes_total offset 1h)/node_network_receive_bytes_total offset 1h)*100
# 如果想计算具体增长了多少MB
(node_network_receive_bytes_total - node_network_receive_bytes_total offset 1h)/1024/1024
等价于
increase(node_network_receive_bytes_total[1h])/1024/1024PromQL常用函数
counter类型常用函数
前面我们讲过,counter类型的监控指标只增不减,因此其样本值应该是不断增大的。因此单纯的counter总是并没有直接作用,而是需要借助rate、irate、increase等函数来计算样本数据的变化状况(增长率)
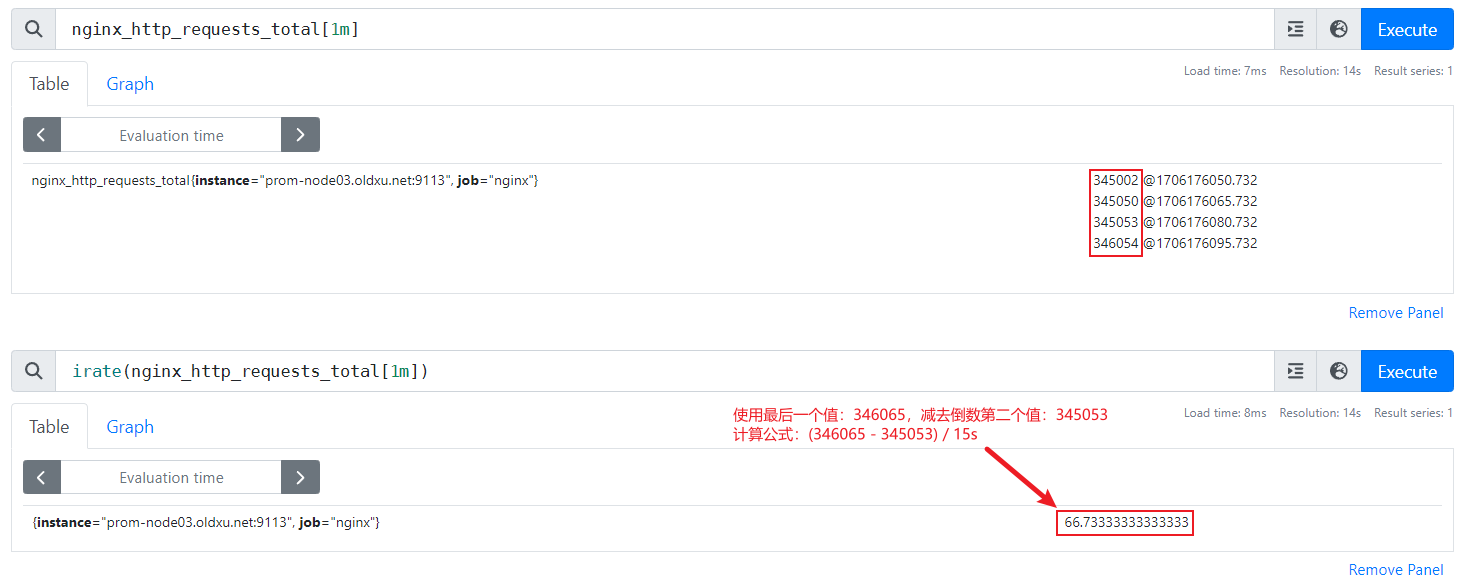
rate用于计算平均增长速率,计算公式:通过指定时间范围内的样本,使用最后一个样本的值减去第一个样本的值,而后除以这两个样本之间的间隔时长。
例如:rate(nginx_http_requests_total[1m]),表示要获取1分钟内,该指标上的http总请求数的平均增长速率

irate用于计算瞬时的增长速率(灵敏度较高),计算公式:通过指定时间范围内的样本最后一个样本的值减去前一个样本的值,而后除以这两个样本之间的间隔时长。
例如:irate(nginx_http_requests_total[1m]),表示要获取1分钟内,该指标上的http总请求数的瞬时增长速率
increase用于计算指定时间范围内样本值得增加量,计算公式:通过指定时间范围内得样本最后一个样本得值减去第一个样本得值。注意:increase可能会引用时间范围边界之前得样本值,以便于计算能覆盖到指定的整改时间范围。
例如:increase(nginx_http_requests_total[1m]),表示要获取1分钟内,http请求的增量

gauge类型常用函数
gauge类型额指标,存储的值是随着时间会发生变化的,它常用求和、取平均值、最小值、最大值等;也会结合PromQL的predict_linear和delta函数使用
-
predict_linear(v range-vector, t, scalar):预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的变化趋势;
例如:predict_linear(node_filesystem_avail_bytes[4h], 60*60*24*30),使用过去4小时的数据来预测接下来30天(606024*30)的磁盘空间趋势。 -
delta(v range-vector):计算范围向量中每个时间序列上的第一个样本值与最后一个样本值之差;其计算结果与increase函数相同;但delta更适用于没有重置的场景,或者用来监控那些可能上升或下降的指标,例如温度、磁盘空间等。
例如:delta(cpu_temp_celsius{host="prom01.oldxu.net"}[2h]),返回该服务器上的cpu温度与2小时之前的差异
例如:delta(node_filesystem_avail_bytes[10m]) /1024 /1024,返回服务器上磁盘可用空间与10分钟之前的差异; -
changes():计算监控时间范围内某个时间序列的数据变化的次数。它只关心变化的次数,而不关心具体变化的值是什么
例如:changes(nginx_up[10m])监控nginx服务在给定时间内变化的次数,如果停止了变化次数+1,启动了变化次数+1.
PromQL二元运算符
PromQL提供了一系列二元运算符,包括算术运算(+-*/)、比较运算(==<=>=)、以及集合运算(and or unless)。
在PromQL中,用户可以执行以下类型的运算:
- 1.标量与标量之间的运算
- 2.即时向量与标量之间的运算
- 3.两个及时向量值得运算。(当涉及到两个即时向量的运算时,
PromQL遵循向量匹配机制(vector matching),定义其运算逻辑)
算术运算符介绍
在PromQL中算术运算符,是用来对指标数据执行基本的数学运算。支持的运算符有:+(加)、-(减)、*(乘)、/(除)、%(取模)和^(幂运算)
- 标量与标量之间进行数学运算,其最终得到的也是标量
# 标量与标量算术运算表达式
5 + 5
# 结果
scalar 10- 即时向量与标量进行运算,例如
将node_memory_MemTotal_bytes(节点内存总大小)的默认bytes单位转为MB
# 即时向量与标量算术运算表达式
node_memory_MemTotal_bytes/1024/1024/1024
# 结果
{instance="192.168.99.7:9100", job="node_exporter"} 7.7768707275390625
{instance="192.168.99.21:9100", job="node_exporter"} 15.651866912841797- 即时向量与即时向量进行运算,它们需要遵循向量的匹配逻辑,也就是向量与向量的标签必须完全匹配一致才可以进行运算,如果它们的标签不一致,则不会执行这个运算。例如:我们想计算内存的可用百分比,计算公式为(内存可用空间/内存总空间*100)=内存可用百分比,这两个向量的标签是完全一致的,因此可以直接进行运算,否则无法正常进行计算,除非进行向量匹配特殊的处理。
# 即时向量与即时向量算术运算表达式
node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes*100
# 结果
{instance="192.168.99.7:9100", job="node_exporter"} 78.87509442476922
{instance="192.168.99.21:9100", job="node_exporter"} 55.93850710314272算术运算符实践
实例1:计算所有实例节点的eth0网卡,接收的总流量和发送的总流量之后(以GB显示)
node_network_receive_bytes_total:节点网络接收的总大小(以字节为单位)node_network_transmit_bytes_total:节点网络发送的总大小(以字节为单位)
# 表达式(计算公式:eth0接收的总流量+eth0发送的总流量)
(node_network_receive_bytes_total{device="eth0"}+node_network_transmit_bytes_total{device="eth0"})/1024/1024/1024
# 结果
{device="eth0", instance="192.168.99.7:9100", job="node_exporter"} 153.2382577760145
{device="eth0", instance="192.168.99.21:9100", job="node_exporter"} 26482.96267025359实例2:计算所有实例节点的/分区已经使用了多少空间(以GB显示)
node_filesystem_size_bytes:文件系统总大小(以字节为单位)node_filesystem_avail_bytes:文件系统可用空间(以字节为单位)
# 表达式(计算公式:(总空间-可用空间)/1024/1024/1024)
(node_filesystem_size_bytes{mountpoint="/"}-node_filesystem_avail_bytes{mountpoint="/"})/1024/1024/1024
# 结果
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.99.7:9100", job="node_exporter", mountpoint="/"} 3.4114036560058594
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.99.21:9100", job="node_exporter", mountpoint="/"} 2.9831771850585938实例3:计算所有实例节点的/分区已用空间百分比
# 表达式(计算公式:(总空间-可用空间)/总空间*100)
(node_filesystem_size_bytes{mountpoint="/"}-node_filesystem_avail_bytes{mountpoint="/"})/node_filesystem_size_bytes{mountpoint="/"}*100
# 结果
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.99.7:9100", job="node_exporter", mountpoint="/"} 9.753665861209786
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.99.21:9100", job="node_exporter", mountpoint="/"} 8.525610398867467实例4:计算所有节点内存的以用百分比
node_memory_MemTotal_bytes:总内存大小(单位字节)node_memory_MemAvailable_bytes:内存可用大小(单位字节)
# 表达式(计算公式:(总内存-可用内存)/总内存*100)
(node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes*100
# 结果
{instance="192.168.99.7:9100", job="node_exporter"} 21.12500367888711
{instance="192.168.99.21:9100", job="node_exporter"} 44.08610877341525比较运算符介绍
在PromQL中比较运算符,是用来对指标的数据进行条件判断,一般在告警规则中定义何时应该触发告警。PromQL支持的比较运算符有如下几个:
==:等于,当两边的数值相等时为真。!=:不等于,当两边的数值不相等时为真。>:大于,当左边的数值大于右边时为真。<:小于,当左边的数值小于右边时为真。>=:大于等于,当左边的数值大于或等于右边时为真。<=:小于等于,当左边的数值小于或等于右边时为真。
在PromQL中,使用比较运算符时,默认情况下,如果比较结果为假(即条件不满足),则相关的时间序列不会出现在结果中。
但是,如果在测试时,想要明确地看到哪些时间序列满足条件(为真)和哪些不满足(为假),可以使用bool修饰符,这个修饰符会将所有的时间序列都显示在结果中,满足条件的序列会有一个值为1(true),不满足的序列会有一个值为0(false)。
- 标量与标量之间进行比较运算
# 标量与标量比较表达式
5 == bool 5
# 结果
scalar 1 # 说明条件成立- 即时向量与标量进行比较运算,例如判断服务器1分钟的负载,是否有大于0以上的节点。
# 即时向量与标量进行比较表达式
node_load1 > 10- 即时向量与即时向量进行比较运算,它们需要遵循向量的匹配逻辑,也就是向量与向量的标签必须完全匹配一致才可以进行运算,如果它们的标签不一致,则不会执行这个运算。例如:我们可以比较可用内存是否大于空闲内存,如果满足该条件,那么会显示左侧的指标名称和指标当前的值。
# 即时向量与即时向量比较表达式
node_memory_MemAvailable_bytes > node_memory_MemFree_bytes比较运算符实践
实例1:查询 job="运维linux",目前不存活实例有哪些(1为存活、0为不存活)。
# 表达式
up{job="运维linux"} != 1
up{instance="192.168.99.21:9100", job="运维linux"} 0 # 表示该节点目前不存活实例2:查询所有实例已使用内存超过30%的节点
# 表达式:(总内存-可用内存)/总内存 * 100 大于 30
(node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes * 100 > 30实例3: 查询所有的实例磁盘可用空间不足80%的节点
# 表达式:(可用空间/总磁盘空间) * 100 < 80
node_filesystem_avail_bytes/node_filesystem_size_bytes*100 < 80实例4:查询所有实例中eth0设备的网络带宽,每秒发送速率超过200Mb/s的实例
# 1.在两个测试的节点上安装:yum install iperf
# 2.服务端运行并指定端口:iperf -s -p 9999
# 3.客户端模拟宽带发送命令,-b指定发送大小,-t指定发送持续时长:iperf -c <ip> -p 9999 -b 300M -t 60
# 表达式 rate(总的传输[1m]) * 8/1024/1024 > 200
# 网络速度或带宽通常以位每秒(如Mbps,Gbps)为单位。因此需要将字节乘以8,能够将字节转换为位,这样可以更准确地描述传输速率
rate(node_network_transmit_bytes_total[1m])*8/1024/1024 > 200实例5:查询所有https的域名,检查域名证书的过期时间,将还剩不到90天的域名列出来(需要借助后面的blackbox黑盒监控,才能获取到对应的指标)
# 表达式,计算公式( (过期时间-当前时间) / 天(24*60*60) )
(probe_ssl_earliest_cert_expiry - time() ) / 86400 < 90集合运算符介绍
在prometheus的查询语言中,集合运算符主要用到的运算符包括and(并且)、or(或者)和unless(排除)
例如:我们有两个关键指标:backup_duration_seconds用于记录每次备份的持续时间,而backup_success则表示备份操作是否成功(1表示成功,0表示失败)
场景1:备份成功但时间超过9s
当备份操作成功完成(backup_success == 1),并且执行时间超过9秒(backup_duration_seconds > 9)时,我们需要发出告警通知备份成功但备份时间过长。这就需要使用and运算符来确保只有当这两个条件都满足时,才触发告警。
对应的表达式为:backup_duration_seconds > 9 and backup_success == 1
场景2:备份失败过时间超过9s
如果备份时长超过了9秒(backup_duration_seconds > 9),或者备份操作失败(backup_success == 0),则同样需要发出告警备份失败或时间过长。这种情况下,是用or运算符可以帮助我们在任一条件满足时触发告警。
对应的表达式为:backup_duration_seconds > 9 or backup_success == 0
场景3:查询成功的备份,但排除耗时超过9s
查询所有成功的备份认为,同时排除那些执行时间超过9秒的任务,这样我们就可以只关注于那些成功备份的任务,并且备份效率较高的。我们可以利用unless运算符来实现,
对应的表达式为:backup_success == 1 unless backup_duration_seconds > 9
and运算符示例,查询当前实例1分钟负载大于2,并且5分钟负载小于2,如果满足条件说明当前发生了突增的负载压力。注意:and运算需要遵循向量的匹配逻辑,也就是向量与向量的标签必须完全匹配一致才可以进行匹配,如果它们的标签不一致,则不会执行匹配逻辑,除非使用ignore忽略不一致的标签来进行匹配
# 模拟负载⾼命令 stress --cpu 8 --timeout 60
# 表达式
node_load1 > 2 and
node_load5 < 2or示例,查询cpu编号为0的idle时间或user时间
# 表达式
node_cpu_seconds_total{instance="192.168.99.21:9100",cpu="0",mode="idle"} or node_cpu_seconds_total{instance="192.168.99.21:9100",cpu="0",mode="user"}
# 用正则
node_cpu_seconds_total{instance="192.168.99.21:9100",cpu="0",mode=~"idle|user"}unless示例,查询node_cpu_seconds_total指标上cpu编号为0的,但要排除模式为idle|user|system|steal|nice
# 表达式
node_cpu_seconds_total{instance="192.168.99.21:9100",cpu="0"} unless node_cpu_seconds_total{instance="192.168.99.21:9100",cpu="0",mode=~"idle|user|system|steal|nice"}集合运算符实践
实例1:查询实例的网络接收流量并且网络发送流量,每秒传输超过200Mb的节点
#模拟接收和发送流量⽐较⾼:"需要在同⼀节点"模拟服务端和客户端,执⾏如下命令
# 1、模拟服务端:iperf -s -p 9999
# 2、模拟客户端:iperf -c x.x.x.x -p 9999 -b 300M -t 60
# 表达式
rate(node_network_transmit_bytes_total[1m])/1024/1024 > 200 and rate(node_network_receive_bytes_total[1m])/1024/1024 > 200实例2:查询当前磁盘,可用空间不足20GB 或者 当前磁盘可用空间不足30%
# 表达式
node_filesystem_avail_bytes/1024/1024/1024 < 20 or
node_filesystem_avail_bytes/node_filesystem_size_bytes*100 < 30实例3:通过probe_http_status_code指标获取当前监控的网站返回的状态码,并从中筛选出小于200的状态码或者大于等于400的状态码
# 表达式
probe_http_status_code < 200 or
probe_http_status_code >= 400PromQL聚合操作
聚合操作介绍
聚合运算,是数据处理中的比较常见操作,例如统计公司所有人员的年龄,求公司整体的平均年龄,最大年龄,或最小年龄等。因此聚合操作是从一组数据值中,计算出一个单一的值。
以下是一个包含了不同城市,以及各地区天气温度的表格。如果想要从这些数据中提取有价值的信息,如温度的最大值和最小值,我们需要使用聚合运算。
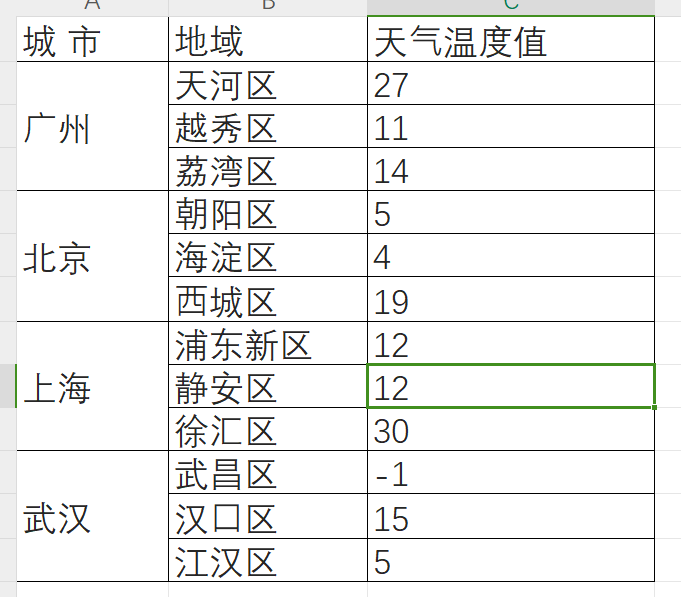
整体聚合:它不会区分数据的维度,而是将所有的数据作为一个整体来处理。这可以帮助我们了解整个数据集的总体情况。例如:
- 整体平均温度(
avg):计算方法是将所有温度值相加后,除以数量(27 + 11 + 14 + 5 + 4 + 19 + 12 + 12 + 30 + (-1) + 15+ 5) / 12 ≈ 12.83度 - 整体最高温度(
max):所有区域中,记录的最高温度,上述数据中为30度。 - 整体最低温度(
min):所有区域中,记录的最低温度,上述数据中为-1度。
分组聚合:是按照数据集的子集进行分组,例如:按照城市这个维度进行分组聚合,我们就可以分别计算不同城市的气温分布情况
- 广州的平均温度(
avg):广州所有区的平均温度是(27 + 11 + 14) / 3 = 17.33度 - 上海的最高温度(
max):上海各区中的最高温度,为徐汇区的30度。 - 武汉的最低温度(
min):武汉各区中的最低温度,为武昌区的-1度。
PromQL聚合介绍
prometheus的聚合操作与此前刚才所描述的常规聚合在本质上是相似的,只不过它支持多种聚合运算函数,包括:
max:计算一组时间序列中的最大值min:计算一组时间序列中的最小值avg:计算时间序列的平均值sum:计算时间序列值得总和count:它不考虑时间序列得具体值,仅用来统计时间序列的数量。例如统计不同OS的数量,或者统计有多少个正在运行的Pod等等count_values:对每个样本的值进行数量统计,例如:http请求的状态码,200出现了多少次,404出现了多少次,500出现了多少次topkbottomk
除了这些基本聚合功能外,prometheus也提供了分组聚合的功能,它是基于时间序列的标签进行分组聚合
by:通过by关键字,明确指定保留哪些标签进行聚合,其他的标签将被忽略without:与by相反,without关键字用于指定要排除的标签,而剩下的标签则用于聚合和分组。
PromQL聚合实践
实例1:查询所有节点,最近1分钟的负载,是否高于cpu核心数的30%
# 获取每个节点的负载表达式
sum(node_load1) by (instance)
# cpu核心数的30%表达式
count(node_cpu_seconds_total{mode="idle"}) by (instance) * 0.3
# 整体表达式
sum(node_load1) by (instance) > count(node_cpu_seconds_total{mode="idle"}) by (instance) * 0.3实例2:查询每个节点的cpu的使用率,指标名称:node_cpu_seconds_total
# 表达式:(1-cpu整体空闲使用率)*100=cpu使用率
(1-avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))*100实例3:查询所有节点,最近1分钟磁盘的最大写入速率,以MB/s为单位,指标名称:node_disk_written_bytes_total
# 模拟数据写⼊,复制2G的数据,控制每秒20M左右的速度写
# yum install pv -y
# dd if=/dev/zero bs=1M count=2000 | pv -L 20M > /tmp/bigdata
# 表达式:获取每分钟的磁盘速率,然后提取最大的值
max(rate(node_disk_written_bytes_total[1m])) by (instance)/1024/1024实例4:查询所有节点,最近1分钟磁盘的读取速率,以MB/s为单位,指标名称:node_disk_read_bytes_total
# 模拟数据读取,读取/tmp/bigdata⽂件,然后以每秒15MB的速度读取
# yum install pv -y
# pv -L 15M /tmp/bigdata > /dev/null
# 表达式
max(rate(node_disk_read_bytes_total[1m])) by (instance) /1024 /1024实例5:计算prometheus服务器的http请求成功率,指标名称:prometheus_http_requests_total
# 表达式
sum(prometheus_http_requests_total{code=~"2.*|3.*"})/sum(prometheus_http_requests_total)*100
# 结果
{} 99.93752484807179 # 网站整体请求成功率在99.9%实例6:查询请求排名前三的url,指标名称:prometheus_http_requests_total
# 表达式
sum(topk(3,prometheus_http_requests_total)) by (handler)
# 结果
{handler="/metrics"} 46463
{handler="/api/v1/query_range"} 3649
{handler="/api/v1/query"} 2849PromQL时间聚合操作
PromQL时间聚合介绍
在prometheus中,除了可以纵向的聚合以外,还可以基于时间聚合也就是横向聚合。
时间聚合不是在不同的序列上进行聚合操作,而是在单个序列的不同时间点之间进行聚合,这意味着,对于单个序列,我们可以计算过去一段时间内的最大值,最小值以及平均值等。
avg_over_time(range-vector):区间向量内每个指标的平均值min_over_time(range-vector):区间向量内每个指标的最小值max_over_time(range-vector):区间向量内每个指标的最大值sum_over_time(range-vector):区间向量内每个指标的求和count_over_time(range-vectro):区间向量内指标样本的总个数
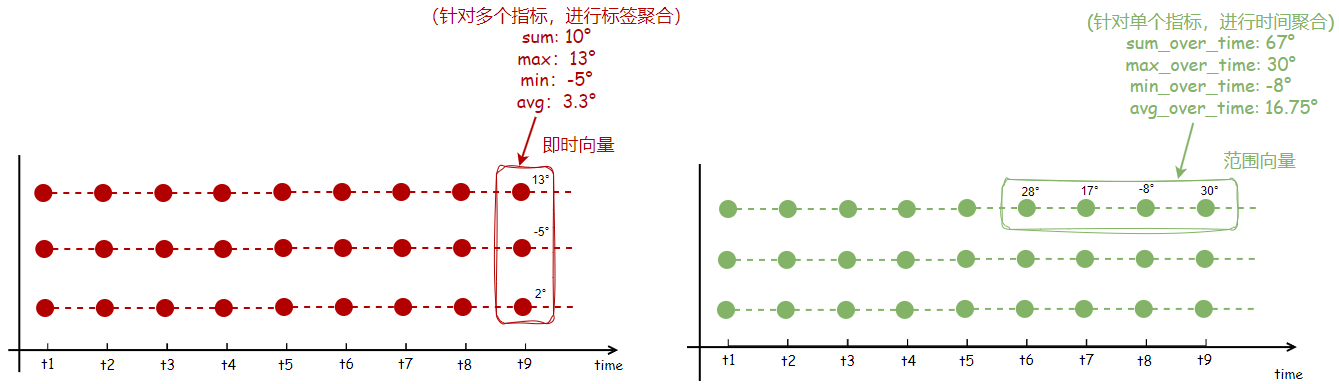
PromQL时间聚合实践
实例1:查询最近1分钟内tcp_timewait连接数的最大值,并检查是否超过1000个,
指标名称:node_tcp_connection_states{state="time_wait"}
# 模拟⼤量tcp_timewait:ab -n 1000 -c 2 http://localhost:9090/
# 表达式
max_over_time(node_tcp_connection_states{state="time_wait"}[1m]) > 1000实例2:查询最近1分钟内tcp_estableshed连接数的最大值,并检查是否超过100个,指标名称:node_tcp_connection_states{state="estableshed"}
# 模拟established:
# 服务端(node01):nc -lk 2345
# 客户端(node02):for i in {1..1000}; do nc prom-node01.oldxu.net 2345 >/dev/null 2>&1 & done
# 表达式
max_over_time(node_tcp_connection_states{state="established"}[1m]) > 100实例3: 查询网站1分钟平均请求延迟大于3s的站点,指标名称:probe_duration_seconds(需要blackbox)
# 表达式
avg_over_time(probe_duration_seconds[1m]) > 3实例4: 查询mysql服务器在最近1分钟内平均运行线程数超过50的。指标名称:mysql_global_status_threads_running
# 模拟MySQL线程数
for i in {1..120} ; do
mysql -e "SELECT SLEEP(60);" &
done
# 表达式
avg_over_time(mysql_global_status_threads_running[1m]) > 50实例5:查询以监控mysql服务器过去1分钟内的线程当前打开的最大连接数。如果这个数值超过了服务器配置的最大连接数的80%则触发告警。
指标名称:
mysql_global_status_threads_connected(表示当前打开的连接数)mysql_global_variables_max_connections(表示配置允许的最大连接数)
# 模拟MySQL连接数
for i in {1..120} ; do
mysql -e "SELECT SLEEP(60);" &
done
# 表达式
max_over_time(mysql_global_status_threads_connected[1m]) / mysql_global_va
riables_max_connections * 100 > 80PromQL向量匹配
PromQL向量匹配介绍
在Prometheus中,执行向量与向量之间的运算时,需要遵循向量匹配的规则。这意味着两个向量必须具有相同的标签,且对应的标签值也必须完全相同,这才能进行运算。如果有任何一个标签或标签值不匹配,那么此次的运算将不会执行。这种匹配规则也被称为向量的一对一匹配。
例如,下面两个时间序列可以成功进行一对一匹配,而后可以正常执行各种运算:
http_requests_total{job="webserver",instance="prom-node01:9100"}http_requests_duration_seconds{job="webserver",instance="prom-node01:9100"}
因为它们的标签以及标签值完全一致,所以它们可以直接进行运算操作
PromQL一对一向量匹配
但是在实际监控场景中,我们会经常遇到标签不完全相同的两个向量,但它们仍然需要进行运算。
prometheus_http_requests_total{job="webserver",instance="prom-node01:9100"} 3200:表示该实例的http请求总数prometheus_http_requests_status_total{job="webserver",instance="prom-node01:9100,method="GET"} 500:表示该实例中使用get方法的http请求总数。
假设我们想要计算使用get方法的请求总数,占总请求数的比例是多少。理想的计算公式是:get方法的请求总数 / 总的请求数 * 100 = get请求所占的比例。但由于两个向量的标签不完全相同(一个有method标签,一个没有),因此无法直接进行计算。
为了解决这个问题,我们可以借助PromQL的向量匹配选项
- 基于标签的匹配(
on):指定基于哪些标签进行匹配。只有当指定的标签及其值在两个向量中都相同,向量之间才能进行运算。 - 忽略标签的匹配(
ignoring):指定忽略某些标签,也就是在运算时不考虑这些标签,只要其他标签以及标签的值相同,向量之间就可以进行运算。
方式1:使用on关键字匹配特定标签,明确指定仅基于job和instance标签进行匹配
方式2:使用ignoring关键字忽略特定标签,忽略不希望参与匹配的method标签
PromQL一对多向量匹配
在实际监控中,我们还会遇到需要进行一对多向量匹配的情况,即一个时间序列中的数据点需要与另一个时间序列中的多个数据点进行匹配运算。
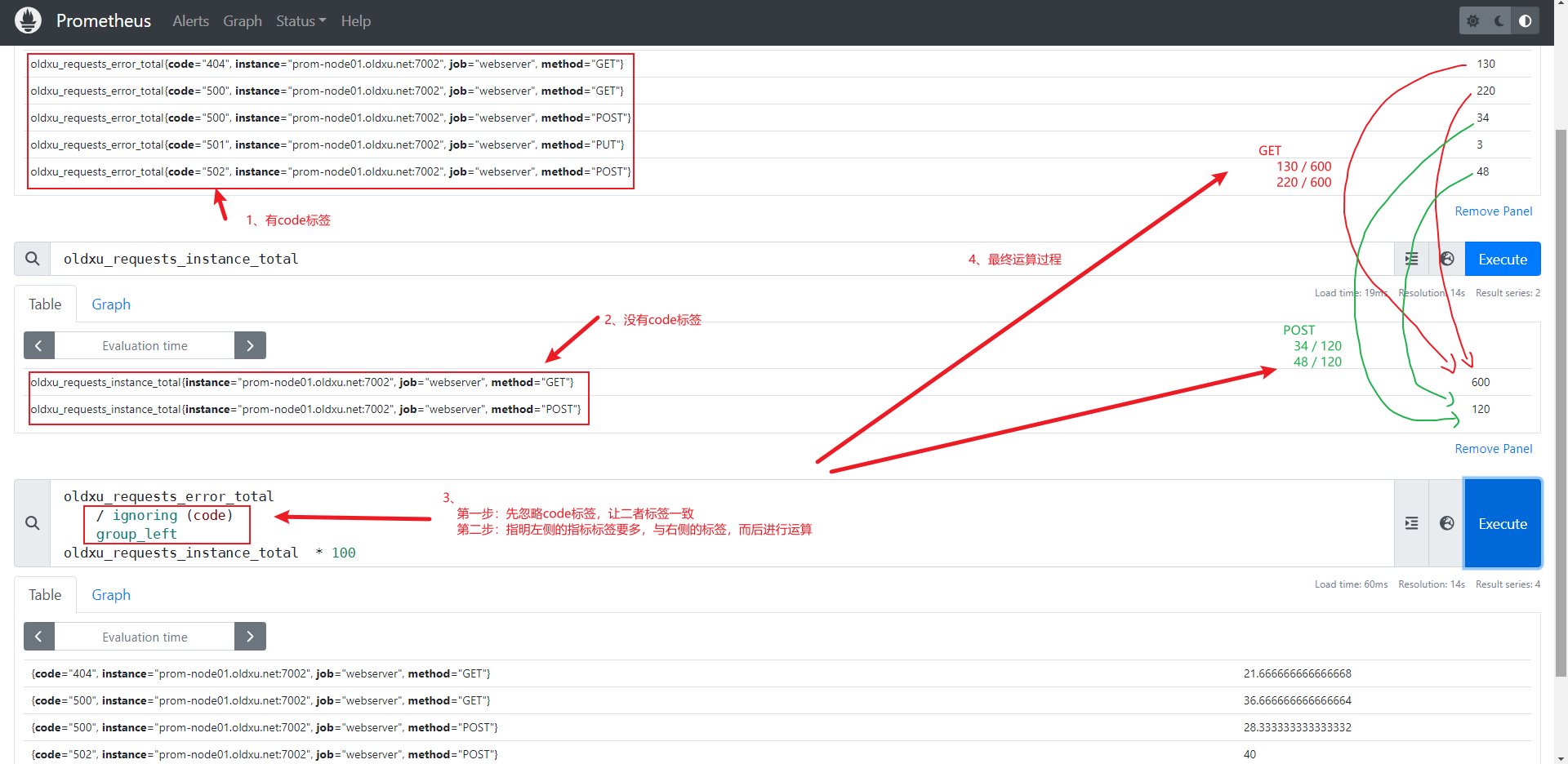
举个例子:假设我们有如下两个指标:
# 第⼀个时间序列:记录了不同HTTP⽅法和状态码的错误请求总数。
oldxu_requests_error_total{job="webserver", method="GET",code="500"} 220
oldxu_requests_error_total{job="webserver", method="GET",code="404"} 130
oldxu_requests_error_total{job="webserver", method="PUT",code="501"} 3
oldxu_requests_error_total{job="webserver", method="POST",code="500"} 34
oldxu_requests_error_total{job="webserver", method="POST",code="502"} 48
# 第⼆个时间序列:记录了每种HTTP⽅法的请求总数。
oldxu_requests_instance_total{job="webserver",method="GET"} 600
oldxu_requests_instance_total{job="webserver","method"="POST"} 120我们的目标是计算每种http方法(get和post)对应不同状态码(404和500)的请求占该方法总请求的比例。大体计算公式如下:
# 1、GET⽅法为500的请求总数 / GET的总请求数 * 100 = GET 500错误⽐例。 (220 /
600 * 100 = 21.666666666666668)
# 2、GET⽅法为404的请求总数 / GET的总请求数 * 100 = GET 404错误⽐例。 (130 /
600 * 100 = 36.666666666666664)
# 3、POST⽅法为500的请求总数 / POST的总请求数 * 100 = POST 500错误⽐例。 (34 / 1
20 * 100 = 28.333333333333332)
# 4、POST⽅法为502的请求总数 / POST的总请求数 * 100 = POST 502错误⽐例。 (48 / 1
20 * 100 = 40 )为了实现这一目标,我们有两个问题需要解决:
-
标签不一致:
具体问题:两个时间序列的标签集合不完全一致,oldxu_requests_error_total包含code标签,而oldxu_requests_instance_total不包含。
解决方法:使用ignoring(code)来忽略code标签,从而使得两个时间序列在没有code标签的情况下可以匹配。 -
一对多匹配:
具体问题:oldxu_requests_error_total中的每个数据点,都需要与oldxu_requests_instance_total中的总请求数相差。
解决方法:必须明确左侧还是右侧为多的以便,因此我们可以使用group_left或group_right来指明哪个是多,然后进行匹配
因此完整的PromQl查询如下:
- 1.使用
ignoring(code)忽略左侧查询oldxu_requests_error_total中的code标签 - 2.使用
group_left修饰符来确保它能够与标签较少的右侧进行匹配 - 3.将匹配后的结果相除,并乘以100得到百分比。
# 表达式
oldxu_requests_error_total
/ ignoring (code)
group_left
oldxu_requests_instance_total * 100PromQL向量匹配示例

PromQL向量匹配实践
实例1:查询每个实例cpu的各个模式使用的时间占总cpu的时间比例是多少,也就是占多少百分比
- 获取每个实例各个模式占用
cpu的时间,按照(instance、mode)进行分组并求和 - 获取每个实例总占用
cpu时间,按照(instance)进行分组求和; - 将每种模式所使用的
cpu时间 /cpu总的时间 * 100 = 每种模式占总cpu时间的百分比
# 表达式
sum(node_cpu_seconds_total) by (instance,mode)
/ on (instance) group_left
sum(node_cpu_seconds_total) by (instance,job) * 100实例2:查询每个cpu核心上不同模式的时间,占总cpu时间的比率是多少,也就是占多少百分比
- 1.计算每个
cpu在各个模式下的累计cpu使用时间,按照(instanc、cpu、mode)进行分组并求和 - 2.计算每个
cpu核心的总cpu时间不区分模式。按照(instanc、cpu)进行分组并求和 - 3.每个
cpu核心的各个模式 /cpu核心的总时间 * 100 = 每个cpu核心的各个模式时间占用百分比
# 表达式
sum(node_cpu_seconds_total{instance="192.168.99.7:9100"}) by (instance,mode,cpu)
/ ignoring (mode)
group_left
sum(node_cpu_seconds_total{instance="192.168.99.7:9100"}) by (instance,cpu)
留言