elastic搜索引擎执行以下两个主要操作:
- 索引(
indexing):此操作用于接收文档,对其进行处理,并将其存储在一个索引中 - 搜索(
searching):此操作用于根据查询从索引中检索数据
除了上述的两个操作,作为数据库,通常它还有另外的两个操作:
- 更改(
update) - 删除(
deleting)
以上的操作详述,请参考彻底理解elasticsearch数据操作
什么是json?
json(javascript object notation)是一种轻量级的数据交换格式。
易于人阅读和编写,同时也易于机器解析和生成。
在elasticsearch中,所有的数据都是以json的格式来进行表述的。
来看一下一个简单的json格式的数据表达:
{
"name" : "Elastic",
"location" : {
"state" : "CA",
"zipcode" : 94123
}
}什么是restful接口?
rest即表述性状态传递(representational state transfer)是一种软件架构风格,是一种规范。
即参数通过封装后进行传递,响应也是返回一个封装对象。
我们可以通过
HTTP GET
HTTP POST
HTTP PUT
HTTP DELETE来对数据进行增加(Create),查询(Read),更新(Update)及删除(Delete)。也就是我们通常说是的 CRUD。
| 方法 | 用法 |
|---|---|
| get | 读取数据 |
| post | 插入数据 |
| put | 更新数据,或如果是一个新的id,则插入数据 |
| delete | 删除数据 |
elasticsearch里的接口都是通过rest接口来实现的。
用rest接口来实现对数据的操作和查询。
查看elasticsearch信息
我们直接打入
GET /
可以看到如下信息
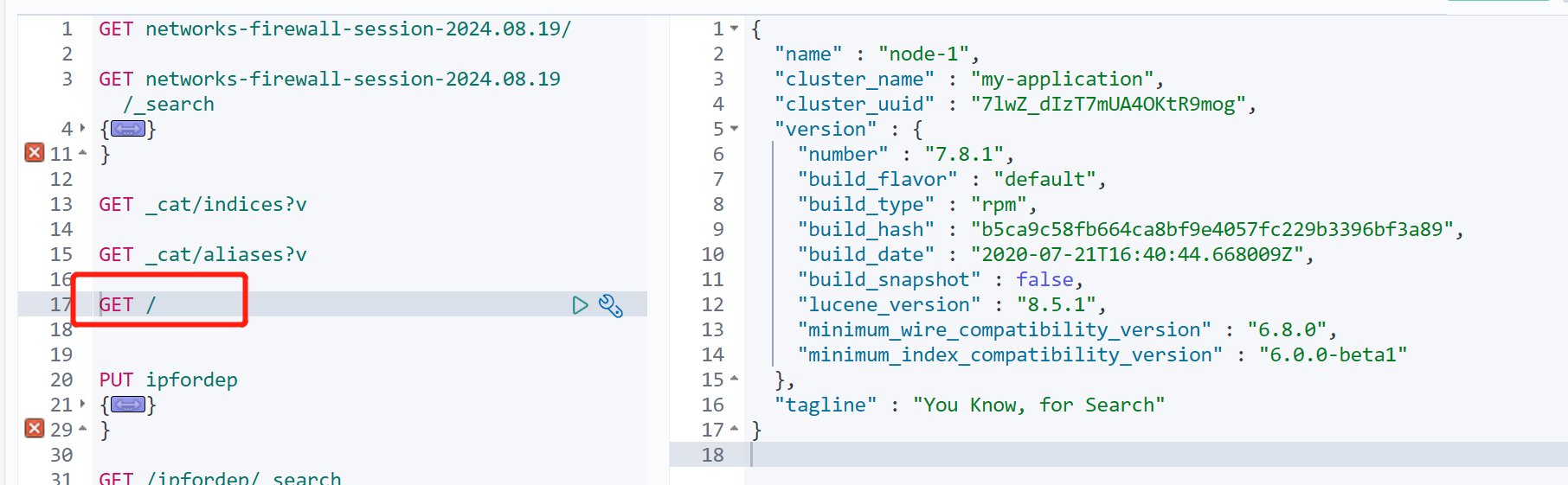
可以看到elasticsearch的版本信息及cluster名称等信息
我们把上面的命令拷贝为cURL,然后在粘贴到centos上,就会看到
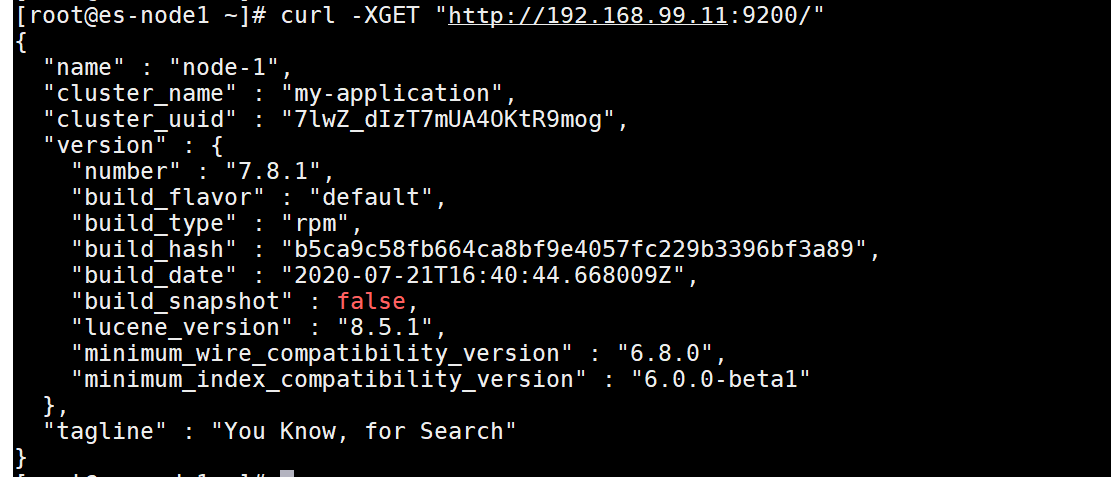
我们可以使用cURL将请求从命令行提交到本地elasticsearch示例
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
使用以下变量:
<VERB>:适当的HTTP方法或动词。 例如,GET,POST,PUT,HEAD或DELETE<PROTOCOL>:http或https。 如果你在Elasticsearch前面有一个HTTPS代理,或者你使用Elasticsearch安全功能来加密HTTP通信,请使用后者<HOST>:Elasticsearch集群中任何节点的主机名。<PORT>:运行Elasticsearch HTTP服务的端口,默认为9200<PATH>:API端点,可以包含多个组件,例如_cluster/stats或_nodes/stats/jvm<QUERY_STRING>:任何可选的查询字符串参数。 例如,?pretty将漂亮地打印JSON响应以使其更易于阅读<BODY>:JSON编码的请求正文(如有必要)
创建一个索引及文档
接下来创建一个叫做twitter的索引(index),并插入一个文档(document)。
在kibana dev tool左边的窗口中输入:
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}可以看到在kibana右边的窗口中有下面的输出:

一旦一个文档被写入,它经历如下的一个过程:
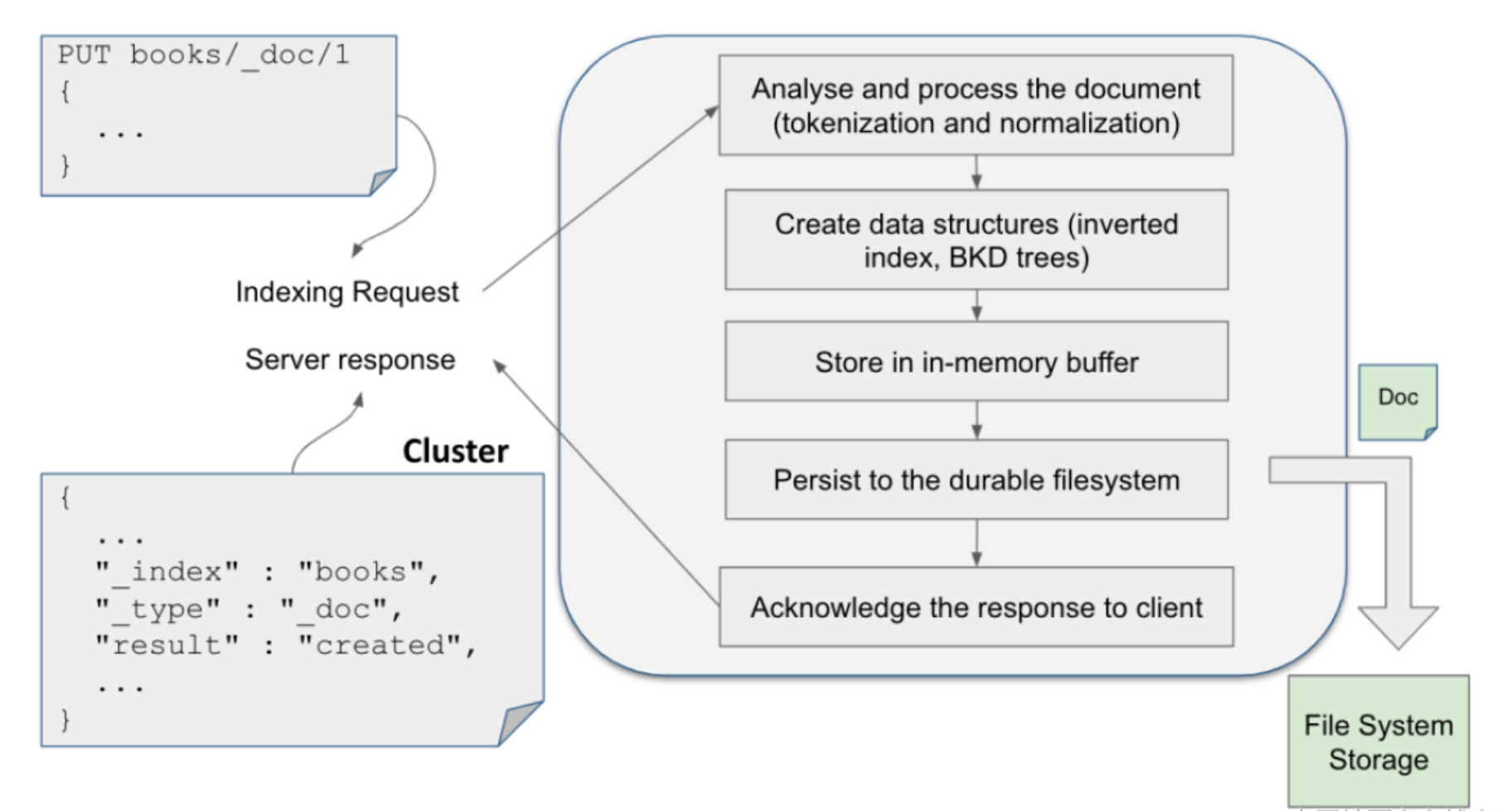
在通常的情况下,新写入的文档并不能马上被用于搜索。
新增的索引必须写入到 Segment 后才能被搜索到。
需要等到 refresh 操作才可以。
在默认的情况下每隔一秒的时间 refresh 一次。这就是我们通常所说的近实时。
请注意:在上面创建文档的过程中,我们并没有像其他 RDMS 系统一样,在输入文档之前需要定义各个字段的类型及长度等。
为了提高入门时的易用性,Elasticsearch 可以自动动态地为你创建索引 mapping。
当我们建立一个索引的第一个文档时,如果你没有创建它的 schema,那么 Elasticsearch 会根据所输入字段的数据进行猜测它的数据类型,比如上面的 user 被被认为是 text 类型,而 uid 将被猜测为整数类型。
这种方式我们称之为 schema on write,也即当我们写入第一个文档时,Elasticsearch 会自动帮我们创建相应的 schema。
在 Elasticsearch 的术语中,mapping 被称作为 Elasticsearch 的数据 schema。
文档中的所有字段都需要映射到 Elasticsearch 中的数据类型。
mapping 指定每个字段的数据类型,并确定应如何索引和分析字段以进行搜索。
mapping 可以显式声明或动态生成。
一旦一个索引的某个字段的类型被确定下来之后,那么后续导入的文档的这个字段的类型必须是和之前的是一致,否则写入将导致错误。
在写入文档时,如果该文档的 ID 已经存在,那么就更新现有的文档;
如果该文档从来没有存在过,那么就创建新的文档。
如果更新时该文档有新的字段并且这个字段在现有的 mapping 中没有出现,那么 Elasticsearch 会根据 schem on write 的策略来推测该字段的类型,并更新当前的 mapping 到最新的状态。
动态 mapping 还可能导致某些字段未映射到你的预期,从而导致索引请求失败。
显式 mapping 允许更好地控制索引中的字段和数据类型。
一旦知道索引 schema,明确定义索引映射是一个好主意。
在运行完上面的命令后,可以通过如下的命令来查看当前索引的 mapping:
GET twitter/_mapping
{
"twitter" : {
"mappings" : {
"properties" : {
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"country" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"province" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"uid" : {
"type" : "long"
},
"user" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}如果仅想得到某一个字段的类型,可以使用如下的命令:
GET twitter/_mapping/field/city
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}上面的这个类型的字段,可能难以让人理解。
其实上面的这个字段是一个multi-field字段。
为不同目的以不同方式索引同一字段通常很有用。
比如在上面,我们定义字段 city 为 text 类型。
text 类型的数据在摄入的时候会分词,这样它可以实现搜索的功能。
同时,这个字段也被定义为 keyword 类型的数据。
这个类型的数据可以让我们针对它进行精确匹配(比如区分大小写,空格等符号),聚合和排序。
其实,上面的第一个 keyword 可以是你定义的任何词,而第二个 keyword 才是它的类型定义。
在实际的使用中,我们有时可能对一个字段需要同时进行搜索和聚合,我们可以这样定义它为 multi-field,但是如果我们仅对搜索或者聚合感兴趣,我们只需要定义其中的一种类型。
这样做的好处是,它可以提高数据摄入的速度,因为不必为两个类型进行索引,同时它也可以减少磁盘的使用。
elasticsearch的数据类型:
text:全文搜索字符串keyword:用于精确字符串匹配和聚合date及date_range:格式化为日期或数字日期的字符串byte、short、integer、long:整数类型boolean:布尔类型float、double、half_float:浮点数类型- 分级的类型:
object及nested。可以参考文章object及nested数据类型
在默认的情况下,elasticsearch可以理解你正在索引的文档的结构并自动创建映射(mapping)。
这称为显式映射(explicit mapping)。
为了在索引中获得更好的结果和性能,我们有时需要手动定义映射。
假如,我们想创建一个索引test,并且含有id及message字段。
id字段为keyword类型,而message字段为text类型,可以使用如下的方法来创建:
PUT test
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}我们甚至可以使用如下的API来追加一个新的字段age,并且它的类型为long类型
PUT test/_mapping
{
"properties": {
"age": {
"type": "long"
}
}
}我们可以使用如下的命令来查看索引test的最终mapping:
GET test/mapping
上面的命令显示的结果如下:
{
"test" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"id" : {
"type" : "keyword"
},
"message" : {
"type" : "text"
}
}
}
}
}通常对一个通过上面方法写入到 Elasticsearch 的文档,在默认的情况下并不马上可以进行搜索。
这是因为在 Elasticsearch 的设计中,有一个叫做 refresh 的操作。
它可以使更改可见以进行搜索的操作。
通常会有一个 refresh timer 来定时完成这个操作。
这个周期为1秒。这也是我们通常所说的 Elasticsearch 可以实现秒级的搜索。
当然这个 timer 的周期也可以在索引的设置中进行配置。
如果我们想让我们的结果马上可以对搜索可见,我们可以用如下的方法:
PUT twitter/_doc/1?refresh=true
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}上面的方式可以强制使 Elasticsearch 进行 refresh 的操作,当然这个是有代价的。
频繁的进行这种操作,可以使我们的 Elasticsearch 变得非常慢。
另外一种方式是通过设置 refresh=wait_for。
这样相当于一个同步的操作,它等待下一个 refresh 周期发生完后,才返回。
这样可以确保我们在调用上面的接口后,马上可以搜索到我们刚才录入的文档:
PUT twitter/_doc/1?refresh=wait_for
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}它也创建了一个被叫做 _doc 的 type。
一个 index 只能有一个 type。
如果我们创建另外一个 type 的话,系统会告诉我们是错误的。
我们也会发现有一个版本(_version)信息,它显示的是2。如果这个 _id 为 1 的 document 之前没有被创建过的话,它会显示为 1。
之后如果我们更改这个 document,它的版本会每次自动增加1。
比如,我们输入:
POST twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Shenzhen",
"province": "Guangdong",
"country": "China"
}右边返回信息如下:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}我们可以看到版本信息增加到3。
这是因为我们把左边的命令执行了两次。
我们把左边的数据进行了修改,看到了成功被修改的返回信息。
在上面我们可以看出来,我们每次执行那个 POST 或者 PUT 接口时,如果文档已经存在,那么相应的版本(_version)就会自动加1,之前的版本抛弃。
如果这个不是我们想要的,那么我们可以使 _create 端点接口来实现:
PUT twitter/_create/1
{
"user": "GB",
"uid": 1,
"city": "Shenzhen",
"province": "Guangdong",
"country": "China"
}如果文档已经存在的话,我们会收到一个错误的信息.
上面的命令和如下的命令也是一样的效果:
PUT twitter/_doc/1?op_type=create
我们在请求时带上op_type。它可以有两种值:index及create
我们可以通过如下的命令来查看被修改的文档:
GET twitter/_doc/1
如果我们只想得到这个文档的_source部分,我们可以使用如下的命令格式:
GET twitter/_source/1
我们也可以只获取source的部分字段
GET twitter/_doc/1?_source=city
如果你想一次请求查找多个文档,我们可以使用_mget接口:
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1
},
{
"_index": "twitter",
"_id": 2
}
]
}我们也可以简单地写为:
GET twitter/_mget
{
"ids": ["1", "2"]
}我们也可以只获得部分字段:
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1,
"_source":["age", "city"]
},
{
"_index": "twitter",
"_id": 2,
"_source":["province", "address"]
}
]
}自动ID生成
在上面,特意为我们的文档分配了一个ID。
其实在实际的应用中,这个并不必要。
相反,当我们分配一个ID时,在数据导入的时候会检查这个ID的文档是否存在,如果是已经存在,那么就更新版本。
如果不存在,就创建一个新的文档。
如果我们不指定文档的ID,转而让elasticsearch自动帮我们生成一个ID,这样的速度更快。
在这种情况下,我们必须使用POST,而不是PUT,比如:
POST my_index/_doc
{
"content": "this is really cool"
}返回的结果:
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "egiY4nEBQTokU_uEEGZz",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}从上面我们可以看出来,系统会为我们自动分配一个ID。
id 像是一个随机的数值,同时我们可以看到它的一个版本信息为1。
在实际的需要有大量导入数据的情况下,我们建议让系统自动帮我们生成一个 id,这样可以提高导入的速度。
假如我们指定一个 id,通常 ES 会先查询这个 id 是否存在,然后在觉得是更新之前的文档还是创建一个新的文档。
这里是分两步走,显然它比直接创建一个文档要慢!
我们也可以看出来系统所给出来的字段都是以下划线的形式给出来的,比如:_id, _shards, _index, _type 等
修改一个文档
接下来看一下如何修改一个文档。
在上面我们看到了可以使用POST命令来修改一个文档。
通常我们使用POST来创建一个新的文档。
在使用POST的时候,我们甚至不用去指定特定的id,系统会帮我们自动生成。
但是我们修改一个文档时,通常会使用PUT来进行操作,并且,需要指定一个特定的id来进行修改:
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "北京",
"province": "北京",
"country": "中国",
"location":{
"lat":"29.084661",
"lon":"111.335210"
}
}如上面所示,我们使用PUT命令来对我们的id为1的文档进行修改。
我们也可以使用上面学过的GET来进行查询:
GET twitter/_doc/1
显然,我们的这个文档已经被成功修改了。
我们使用PUT的这个方法,每次修改一个文档时,我们需要把把文档的每一项都要写出来。
这对于有些情况来说,并不方便,我们可以使用如下的方法进行修改:
POST twitter/_update/1
{
"doc": {
"city": "成都",
"province": "四川"
}
}我们可以使用如上的命令来修改我们的部分数据。
同样可以使用GET来查询我们的修改是否成功。
在关系数据库中,我们通常是对数据库进行搜索,然后才进行修改。
在这种情况下,我们事先通常并不知道文档的id。
我们需要通过查询的方式来进行查询,然后进行修改。
es也提供了相应的REST接口.
POST twitter/_update_by_query
{
"query": {
"match": {
"user": "GB"
}
},
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;ctx._source.country = params.country",
"lang": "painless",
"params": {
"city": "上海",
"province": "上海",
"country": "中国"
}
}
}我们可以通过上面的方法搜寻 user 为 GB 的用户,并且把它的数据项修改。
我们甚至可以使用 _update 接口使用 ctx['_op'] 来达到删除一个文档的目的,比如:
POST twitter/_update/1
{
"script": {
"source": """
if(ctx._source.uid == 1) {
ctx.op = 'delete'
} else {
ctx.op = "none"
}
"""
}
}当检测文档的 uid 是否为 1,如果为 1 的话,那么该文档将被删除,否则将不做任何事情。
我还可以充分使用 script 的一些高级操作,比如我们可以通过如下的方法来添加一个崭新的字段:
POST twitter/_update/1
{
"script" : {
"source": "ctx._source.newfield=4",
"lang": "painless"
}
}通过上面的操作,我们可以发现,我们新增加了一个叫做 newfield 的字段。
当然我们也可以使用如下的方法来删除一个字段:
POST twitter/_update/1
{
"script" : {
"source": "ctx._source.remove(\"newfield\")",
"lang": "painless"
}
}在上面的命令中,我们通过 remove 删除了刚才被创建的 newfiled 字段。
在这里请注意的是:一旦一个字段被创建,那么它就会存在于更新的 mapping 中。
即便针对 id 为 1 的文档删除了 newfield,但是 newfield 还将继续存在于 twitter 的 mapping 中。
我们可以使用如下的命令来查看 twitter 的 mapping:
GET twitter/_mapping
这里值得注意是:对于多用户,我们可以从各个客户端同时更新,这里可能会造成更新数据的一致性问题。
UPSERT 一个文档
仅在文档事先存在的情况下,我们在前面的代码中看到的部分更新才有效。
如果具有给定 id 的文档不存在,Elasticsearch 将返回一个错误,指出该文档丢失。
让我们了解如何使用更新 API 进行 upsert 操作。
术语 “upsert” 宽松地表示更新或插入,即更新文档(如果存在),否则,插入新文档。
doc_as_upsert 参数检查具有给定ID的文档是否已经存在,并将提供的 doc 与现有文档合并。
如果不存在具有给定 id 的文档,则会插入具有给定文档内容的新文档。
下面的示例使用 doc_as_upsert 合并到 id 为 3 的文档中,或者如果不存在则插入一个新文档:
POST /catalog/_update/3
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}检查一个文档是否存在
有时候我们想知道一个文档是否存在,可以使用如下的方法
HEAD twitter/_doc/1
这个HEAD接口可以很方便地告诉我们在twitter的索引里是否有 id 为1的文档
删除一个文档
如果我们想删除一个文档的话,可以使用如下的命令:
DELETE twitter/_doc/1
在上面的命令中,我们删除了 id 为1的文档。
在关系数据库中,我们通常是对数据库进行搜索,然后才进行删除。
在这种情况下,我们事先通常并不知道文档的 id 。
我们需要通过查询的方式来进行查询,然后进行删除。
ES也提供了相应的REST接口。
POST twitter/_delete_by_query
{
"query": {
"match": {
"city": "上海"
}
}
}上面的命令是把所有 city 是上海的文档都删除了。
检查一个索引是否存在
我们可以使用如下的命令来检查一个索引是否存在:
HEAD twitter
如果 twitter 索引存在,那么上面的命令会返回:
200 - OK
否则就会返回:
{"statusCode":404,"error":"Not Found","message":"404 - Not Found"}
删除一个索引
删除一个索引是否非常直接的,我们可以使用如下的命令来进行删除:
DELETE twitter
当我们执行完这一条语句后,所有的在twitter中的所有文档都将被删除。
批处理命令
上面我们已经了解了如何使用 REST 接口来创建一个 index,并为之创建(Create),读取(Read),修改(Update),删除文档(Delete)(CRUD)。
因为每一次操作都是一个 REST 请求,对于大量的数据进行操作的话,这个显得比较慢。
ES 创建一个批量处理的命令给我们使用。
这样我们在一次的 REST 请求中,我们就可以完成很多的操作。
这无疑是一个非常大的好处。
下面,我们来介绍一下这个 _bulk 命令。
我们使用如下的命令来进行 bulk 操作:
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}在上面的命令中,我们使用了bulk指令来完成操作。
在输入命令时,我们需要特别的注意:千万不要添加换行以外的空格,否则会导致错误
在上面我们使用 index 用来创建一个文档。
为了说明问题的所在,我们在每一个文档里,特别指定了每个文档的id。
显然,我们的创建时成功的。
bulk 指令是高效的,因为一个请求就可以处理很多个操作。
在实际的使用中,我们必须注意的是:一个好的起点是批量处理 1,000 到 5,000 个文档,总有效负载在 5MB 到 15MB 之间。
如果我们的 payload 过大,那么可能会造成请求的失败。
如果你想查询到所有的输入文档,可以使用如下的命令来进行查询:
GET twitter/_search
我们可以通过使用_count命令查询有多少条数据:
GET twitter/_count
上面我们已经使用了 index 来创建6条文档记录。我也可以尝试其它的命令,比如 create:
POST _bulk
{ "create" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}在上面,我们的第一个记录里,我们使用了 create 来创建第一个 id 为1的记录。因为之前,我们已经创建过了,所以我们会看到错误信息。
可以看出来 index 和 create 的区别。
index 总是可以成功,它可以覆盖之前的已经创建的文档,但是 create 则不行,如果已经有以那个 id 的文档,就不会成功。
我们可以使用 delete 来删除一个已经创建好的文档。
POST _bulk
{ "delete" : { "_index" : "twitter", "_id": 1 }}我们也可以使用 update 来进行更新一个文档
POST _bulk
{ "update" : { "_index" : "twitter", "_id": 2 }}
{"doc": { "city": "长沙"}}注意:通过 bulk API 为数据编制索引时,你不应在集群上进行任何查询/搜索。 这样做可能会导致严重的性能问题。
如果你对脚本编程比较熟悉的话,你可能更希望通过脚本的方法来把大量的数据通过脚本的方式来导入。
索引统计
elasticsearch提供有关进入索引的数据以及提取的数据的详细统计信息。
它提供API来生成报告,例如索引包含的文档数、已删除的文档、合并和刷新统计信息等。
每个索引都会生成统计信息,例如它拥有的文档总是、已删除文档的计数、分片的内存、获取和搜索请求数据等。
_stats API帮助我们检索索引的统计信息,包括主分片和副本分片。
我们甚至可以同时获得多个索引的统计数据:
GET twitter1,twitter2,twitter3/_stats
我们也可以使用通配符来匹配多个索引:
GET twitter*/_stats
open/close index
Elasticsearch 支持索引的在线/离线模式。
使用脱机模式时,在群集上几乎没有任何开销地维护数据。
关闭索引后,将阻止读/写操作。
当你希望索引重新联机时,只需打开它即可。
但是,关闭索引会占用大量磁盘空间。
你可以通过将 cluster.indices.close.enable 的默认值从 true 更改为 false 来禁用关闭索引功能,以避免发生意外。
POST twitter/_close
一旦 twitter 索引被关闭了,那么我们再访问时会出现错误。
我们可以重新打开这个index:
POST twitter/_open
freeze/unfreeze index
冻结索引(freeze index)在群集上几乎没有开销(除了将其元数据保留在内存中),并且是只读的。
只读索引被阻止进行写操作。
冻结索引受到限制,以限制每个节点的内存消耗。
每个节点的并发加载的冻结索引数受 search_throttled 线程池中的线程数限制,默认情况下为1。
默认情况下,即使已明确命名冻结索引,也不会针对冻结索引执行搜索请求。
这是为了防止由于误将冻结的索引作为目标而导致的意外减速。
如果要包含冻结索引做搜索,必须使用查询参数 ignore_throttled = false 来执行搜索请求。
我们可以使用如下的命令来对 twitter 索引来冻结:
POST twitter/_freeze
在执行上面的命令后,我们再对twitter进行搜索:
我们搜索不到任何结果。
必须加上 ignore_throttled=false 参数来进行搜索:
GET twitter/_search?ignore_throttled=false
我们可以通过如下的命令来对这个已经冻结的索引来进行解冻:
POST twitter/_unfreeze
总结
在这篇文章中,我们详细地介绍了如何在 Elasticserch 中创建我们的索引,文档,并对他们进行更改,删除,查询的操作。
留言